管理统计学异方差自相关多重共线性的检验

实验名称:多元回归模型的异方差、自相关性、多重共线性检验
【实验内容】
表4-7给出了我国1995-2007年名义服务产业产出(Y)、服务员就业人数(X1)、软件外包服务收入(X2)和技术进步知识(X3)的数据。试完成:
表4-7 我国1995-2007年名义服务业产出、服务员就业人数、软件外包服务收入和技术进步指数的数据
年份名义服务业产出
(亿元)
服务员就业人数
(万人)
软件外包服务收
入(亿美元)
技术进步指数
1995 19978.5 16880 0.09 1.086
1996 23326.2 17927 0.08 1.089
1997 26988.1 18432 0.11 1.047
1998 30580.5 18860 0.14 1.065
1999 33873.4 19205 0.58 1.015
2000 38714 19823 1.06 0.999
2001 44361.6 20228 1.8 1.021
2002 49898.9 21090 3.26 1.139
2003 56004.7 21809 4 0.772
2004 64561.3 23011 6.33 1.34
2005 73432.9 23771 9.6 1.45
2006 84721.4 24614 14.3 1.58
2007 100053.5 24917 22.06 1.64
(1)根据表4-7的数据建立多元回归模型,并进行估计。
(2)用White检验法对回归模型的随机干扰项进行异方差检验。
(3)用LM检验法回归模型的随机干扰项进行自相关检验。
(4)根据回归方程的结果判断各项系数是否通过了t检验,方程是否通过了F检验。
【实验步骤】
(一)参数估计:
打开EViews软件,输入数据,估计样本回归方程(操作方法同第二章案例的建立工作文件部分)如下图:
根据上图,模型的估计的回归方程为:
Y=-76769.99+6.0453X1+1631.505X2-6206.783X3 (0.199) (2.235) (31.487) (17.770)
998.02=R 181.1617=F 括号内为t 统计量值。
(二)检验异方差性: (1)图形检验分析:
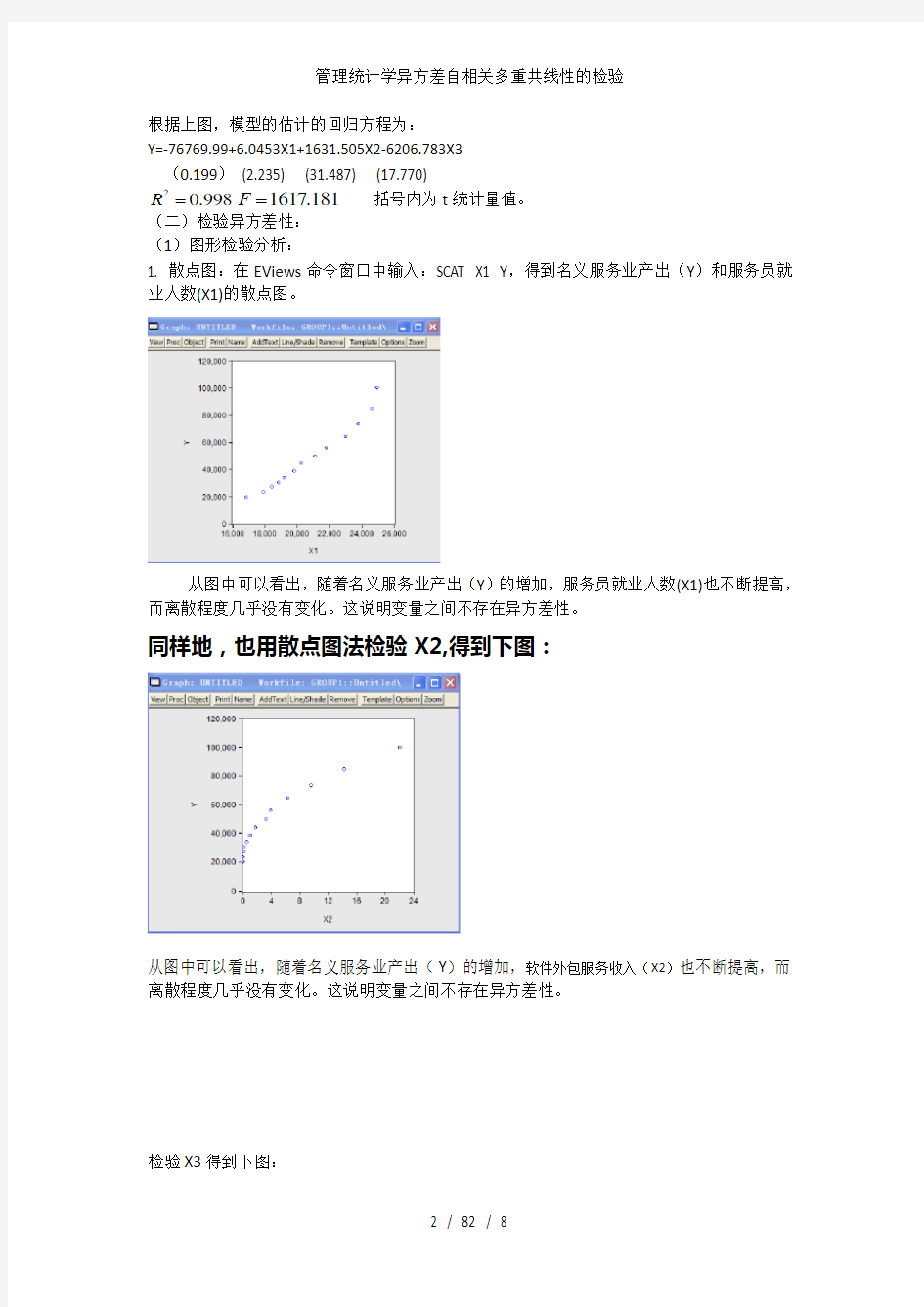
1. 散点图:在EViews 命令窗口中输入:SCAT X1 Y ,得到名义服务业产出(Y )和服务员就业人数(X1)的散点图。
从图中可以看出,随着名义服务业产出(Y )的增加,服务员就业人数(X1)也不断提高,而离散程度几乎没有变化。这说明变量之间不存在异方差性。
同样地,也用散点图法检验X2,得到下图:
从图中可以看出,随着名义服务业产出(Y )的增加,软件外包服务收入(X2)也不断提高,而离散程度几乎没有变化。这说明变量之间不存在异方差性。
检验X3得到下图:
从图中可以看出,随着名义服务业产出(Y)的增加,技术进步指数也不断提高,而离散程度几乎没有变化。这说明变量之间不存在异方差性。
2、残差检验法:
在命令窗口输入:line resid,得到如下图的模型残差分布图
上图显示回归方程的残差分布有明显的缩小的趋势,即表明不存在异方差性。
3、White检验法:
(1)建立回归模型:ls y c x1 x2 x3,回归结果如最上面的图所示,
(2) 在方程窗口上以此点击View\Residual\Test\White Heteroskedastcity,检验结果如下图:
其中F 值为辅助回归模型的F 统计量值。取显著水平
05
.0=α,由于
9073.116.919)9(20.052=>=nR χ,所以不存在异方差性。实际应用中可以直接观察相伴概
率p 值的大小,在显著水平05.0=α的条件下,若p 值小于0.05,则认为存在异方差性。反之,则认为不存在异方差性。 4、Park 检验:
1. 建立回归模型。
2. 生成新变量序列残差平方的对数:在命令窗口分别输入GENR LNE2=log(RESID^2)。
3. 建立新残差序列对解释变量的回归模型:LS LNE2 C X1 X2 X3,回归结果如图3-10所示。
从上图所示的回归结果中的p 值可以直接看出,X 的系数估计值在显著水平05.0=α的条件下,显著为0,即随机干扰项的方差与解释变量不存在较强的相关关系,即认为不存在异方差性。由于Gleiser 检验与Park 检验原理相同,在此略去。
三、自相关性检验:
模型的估计的回归方程为:
Y=-76769.99+6.0453X1+1631.505X2-6206.783X3 se=(6477.589) (0.290) (149.751) (2744.556) t = (0.199) (2.235) (31.487) (17.770)
998.02=R 181.1617=F DW=1.6205 (一)DW 检验
由于样本容量小于15,所以该检验法不适合使用。 (二)BG 检验
在方程窗口中点击View/Residual Test/Serial Correlation LM Test ,选择滞后期为2,输出结果如下图。
可得16.919)9(11534.0008872.0*1305.022=<==χnR ,相伴概率(即p 值)为0.5618,因此在显著性水平0.05α=的条件下,接受无自相关的原假设,即随机干扰项不存在自相关。
(4)模型检验: 1、经济意义检验:
模型估计结果说明,在假定其他变量不变的情况下,当服务就业人数每增长1万人,名义服务业产出就会增加6.0453亿美元;在假定其他变量不变的情况下,当软件外包服务收入每增长1亿美元,国债发行总量就会增加1631.505亿美元;在假定其他变量不变的情况下,当技术进步指数每增长1,国债发行总量就会增加-6206.783亿美元;服务就业人数、软件外包服务收入与名义服务业产出均为正相关,这与理论分析及经验判断相一致。但技术进步指数与名义服务业产出为负相关,这与理论分析及经验判断不一致。说明该模型可能存在多重共线性。 2、t 检验: 分别针对
0H :
)
3,2,1(0==j j β,给定显著性水平α=0.05,查t 分布表得自由度为13-3-1=9,
临界值2622.2)9(025.0=t 。
)
3,2,1(==j t j 对应的t 统计量分别为2.435、31.487、17.770。,
其绝对值均大于临界值2.2622,所以均通过了显著性检验。
3、F 检验:
针对
0H :
321===βββ,给定显著性水平05.0=α,在F 分布表中查出自由度为3和9
的临界值68.3)9,3(05.0=F 。由于F=1617.181>3.86,应拒绝原假设
H ,说明回归方程显著,
即服务员就业人数(X1)、软件外包服务收入(X2)、技术进步指数(X3)对名义服务业产出有显著影响。
(5)多重共线性检验: 计算各解释变量的系数,选择X1,X2,X3的数据,点“View/covariance analysis ”,勾选correlation 得相关系数矩阵,如下图所示:
由相关系数矩阵可以看出,个解释变量之间存在较高的相关系数,由此证实存在较严重的多重共线性。
(6)多重共线性的修正:
①采用逐步回归的办法,去检验和解决多重共线性问题。分别作Y 对X1、X2、X3的一元回变量 X1 X2 X3 参数估计值 9.297 3514.690 76854.93 t 统计量 17.409 10.232 4.161 2
R
0.965
0.905
0.611 修正后的2
R
0.962
0.896
0.576
F 统计值
303.065
104.685
17.312
按2
R 的大小排序为:X1、X2、X3。
②以X1为基础,顺次加入其他变量逐步回归。首先加入X2回归结果为:
Y=-84355.98+6.112X1+1408.58X2 t=(-12.81) (17.82) (10.52) R=0.997 F=1716.85
X2的系数为正,合理,而且Prob=0,显著,所以予以保留。 ③加入X3,以X1,X2,X3作为解释变量,得到回归结果为:
Y=-76769.99+6.0453X1+1631.505X2-6206.783X3 t = (0.199) (2.235) (31.487) (17.770)
998.02=R 181.1617=F
可以发现X3的系数估计值为负,不合理,予以剔除。
那么,消除共线性后的最终模型为:
Y=-84355.98+6.112X1+1408.58X2
异方差性的white检验及处理方法
实验二异方差模型的white检验与处理 【实验目的】 掌握异方差性的white检验及处理方法 【实验原理】 1. 定性分析异方差 (1) 经济变量规模差别很大时容易出现异方差。如个人收入与支出关系,投入与产出 关系。 (2) 利用散点图做初步判断。 (3) 利用残差图做初步判断。 2、异方差表现与来源异方差通常有三种表现形式 (1)递增型 (2)递减型 (3)条件自回归型。 3、White检验 (1)不需要对观测值排序,也不依赖于随机误差项服从正态分布,它是通过一个辅助回归式构造 2 统计量进行异方差检验。White检验的零假设和备择假设是 H0: (4-1)式中的ut不存在异方差, H1: (4-2)式中的ut存在异方差。 (2)在不存在异方差假设条件下,统计量 T R 2 2(5) 其中T表示样本容量,R2是辅助回归式(4-3)的OLS估计式的可决系数。自由度5表示辅助回归式(4-3)中解释变量项数(注意,不计算常数项)。T R 2属于LM统计量。 (3)判别规则是 若T R 2 2 (5), 接受H0(ut 具有同方差) 若T R 2 > 2 (5), 拒绝H0(ut 具有异方差) 【实验软件】 Eview6 【实验要求】 熟练掌握异方差white检验方法 【实验内容】 建立并检验我国部分城市国民收入y和对外直接投资FDI异方差模型 【实验方案设计】 下表列出了我国各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据,并利用统计软件Eviews建立异方差模型
表1 各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据(单位:元) 【实验过程】 1、启动Eviews6软件,建立新的workfile. 在主菜单中选择【File 】--【New 】--【Workfile 】,弹出 Workfile Create 对话框,在Workfile structure typ 中选择unstructured/undted.然后在observations 中输入31.在WF 中输入Work1,点击OK 按钮。如图: 2、数据导入且将要分析的数据复制黏贴. 在主菜单的空白处输入data x y 按下enter 。将家庭人均纯收入X 和家庭生活消 地区 家庭人均 纯收入 家庭生活消费支出 地区 家庭人均 纯收入 家庭生活消费支出 北京 湖北 3090 天津 湖南 河北 广东 山西 广西 内蒙古 海南 辽宁 重庆 吉林 四川 黑龙江 贵州 上海 云南 江苏 西藏 浙江 陕西 安徽 甘肃 福建 青海 江西 宁夏 山东 新疆 河南
eviews异方差、自相关检验与解决办法
eviews异方差、自相关检验与解决办法 一、异方差检验: 1.相关图检验法 LS Y C X 对模型进行参数估计 GENR E=RESID 求出残差序列 GENR E2=E^2 求出残差的平方序列 SORT X 对解释变量X排序 SCAT X E2 画出残差平方与解释变量X的相关图 2.戈德菲尔德——匡特检验 已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。 SORT X 将样本数据关于X排序 SMPL 1 10 确定子样本1 LS Y C X 求出子样本1的回归平方和RSS1 SMPL 17 26 确定子样本2 LS Y C X 求出子样本2的回归平方和RSS2 计算F统计量并做出判断。 解决办法 3.加权最小二乘法 LS Y C X 最小二乘法估计,得到残差序列 GRNR E1=ABS(RESID) 生成残差绝对值序列 LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计 二、自相关 1.图示法检验 LS Y C X 最小二乘法估计,得到残差序列 GENR E=RESID 生成残差序列 SCAT E(-1) E et—et-1的散点图 PLOT E 还可绘制et的趋势图 2.广义差分法 LS Y C X AR(1) AR(2)
首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。接着,使用spss16来解决自相关。第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。第四步,最后定义两个新变量,即X2=X-B*X1,Y2=Y-B*X2,最后做X2和Y2的回归,这样广义差分就完成了。但是这仅仅只是一次广义差分,观察X2和Y2的回归分析表,如果DW值仍然显示有自相关,则还要做一次差分,即重复上述步骤即可。 一般来说,广义差分最多做2次就行了。。。 本文来自: 人大经济论坛SPSS专版版,详细出处参考:https://www.360docs.net/doc/c915912584.html,/forum.php?mod=viewthread&tid=289529&page=1
计量经济学异方差的检验与修正
《计量经济学》实训报告 实训项目名称异方差模型的检验与处理 实训时间 2012-01-02 实训地点实验楼308 班级 学号 姓名
实 训 (实 践 ) 报 告 实 训 名 称 异方差模型的检验与处理 一、 实训目的 掌握异方差性的检验及处理方法。 二 、实训要求 1.求销售利润与销售收入的样本回归函数,并对模型进行经济意义检验和统计检验; 2.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 3.如果模型存在异方差,选用适当的方法对异方差进行修正,消除或减小异方差对模型的影响。 三、实训内容 建立并检验我国制造业利润函数模型,检验异方差性,并选用适当方法对其进行修正,消除或不同) 四、实训步骤 1.建立一元线性回归方程; 2.建立Workfile 和对象,录入数据; 3.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 4.对所估计的模型再进行White 检验,观察异方差的调整情况,从而消除或减小异方差对模型的影响。 五、实训分析、总结 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料。假设销售利润与销售收入之间满足线性约束,则理论模型设定为: 12i i i Y X u ββ=++ 其中i Y 表示销售利润,i X 表示销售收入。
表1 我国制造工业1998年销售利润与销售收入情况 行业名称销售利润Y 销售收入X 行业名称销售利润销售收入 食品加工业187.25 3180.44 医药制造业238.71 1264.1 食品制造业111.42 1119.88 化学纤维制品81.57 779.46 饮料制造业205.42 1489.89 橡胶制品业77.84 692.08 烟草加工业183.87 1328.59 塑料制品业144.34 1345 纺织业316.79 3862.9 非金属矿制品339.26 2866.14 服装制品业157.7 1779.1 黑色金属冶炼367.47 3868.28 皮革羽绒制品81.7 1081.77 有色金属冶炼144.29 1535.16 木材加工业35.67 443.74 金属制品业201.42 1948.12 家具制造业31.06 226.78 普通机械制造354.69 2351.68 造纸及纸品业134.4 1124.94 专用设备制造238.16 1714.73 印刷业90.12 499.83 交通运输设备511.94 4011.53 文教体育用品54.4 504.44 电子机械制造409.83 3286.15 石油加工业194.45 2363.8 电子通讯设备508.15 4499.19 化学原料纸品502.61 4195.22 仪器仪表设备72.46 663.68 1.建立Workfile和对象,录入销售收入X和销售利润Y: 图1 销售收入X和销售利润Y的录入 2.图形法检验 ⑴观察销售利润Y与销售收入X的相关图:在群对象窗口工具栏中点击
计量经济学多元线性回归、多重共线性、异方差实验报告记录
计量经济学多元线性回归、多重共线性、异方差实验报告记录
————————————————————————————————作者:————————————————————————————————日期:
计量经济学实验报告
多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β 1 X 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元
异方差性检验
金融122班 23号钟萌 异方差性检验 引入滞后变量X-1、X-2、Y-1 。可建立如下中国居民消费函数: Y=β0+β1X+β2X(-1)+β3X(-2)+β4Y(-1) 用OLS法进行估计,结果如下: 对应的表达式为 Y=429.3512+0.143X-0.104X(-1)+0.063X(-2)+0.838Y(-1) 2.18 2.09 -0.73 0.63 7.66 R2=0.9988 F=4503.94 估计结果显示,在5%的显著性水平下,自由度为25的临界值为2.060,若存在异方差性,则可能是由X、Y(-1)引起的。
做OLS回归得到的残差平方项分别与X、Y(-1)的散点图
从散点图可以看出,两者存在异方差性。下面进行统计检验。 采用White异方差检验: 所以辅助回归结果为: e2=-194156.4-249.491X+0.003X2+265.306X(-1)-0.004X(-1)2+4.187X(-2)- 0.001X(-2)2 +51.377Y(-1)+0.001Y(-1)2 -1.566 -4.604 2.863 2.648 -1.604 0.055 -0.301 0.579 0.410 X与X的平方项的参数的t检验是显著的,且White统计量为
16.999>5%显著性水平下,自由度为8的卡方分布值15.51,(从nR2 统计量的对应值的伴随概率值容易看出)所以在5%的显著性水平下,拒绝同方差性这一原假设,方程确实存在异方差性。 用加权最小二乘法对异方差性进行修正,重新进行回归估计, 得到加权后消除异方差性的估计结果: 回归表达式为: Y=275.0278-0.0192X+0.1617X(-1)-0.0732X(-2)+0.9165Y(-1) 3.5753 -0.3139 1.3190 -1.0469 16.5504
试验一异方差的检验与修正-时间序列分析
案例三 ARIMA 模型的建立 一、实验目的 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容及要求 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2007年中国进出口贸易总额数据运用经典B-J 方法论建立合适的ARIMA (,,p d q )模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验指导 1、模型识别 (1)数据录入 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated –regular frequency ”,在“Date specification ”栏中分别选择“Annual ”(年数据) ,分别在起始年输入1950,终止年输入2007,点击ok ,见图3-1,这样就建立了一个工作文件。点击File/Import ,找到相应的Excel 数据集,导入即可。
计量经济学多元线性回归、多重共线性、异方差实验报告概要
计量经济学实验报告
多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到30.0亿人次,同比增长13.6%,国内旅游收入2.3万亿元,同比增长19.1%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β1X 1 +β2X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元
异方差性习题及答案
异方差性 一、单项选择 1.Goldfeld-Quandt 方法用于检验( ) A.异方差性 B.自相关性 C.随机解释变量 D.多重共线性 2.在异方差性情况下,常用的估计方法是( ) A.一阶差分法 B.广义差分法 C.工具变量法 D.加权最小二乘法 3.White 检验方法主要用于检验( ) A.异方差性 B.自相关性 C.随机解释变量 D.多重共线性 4.Glejser 检验方法主要用于检验( ) A.异方差性 B.自相关性 C.随机解释变量 D.多重共线性 5.下列哪种方法不是检验异方差的方法 ( ) A.戈德菲尔特——匡特检验 B.怀特检验 C.戈里瑟检验 D.方差膨胀因子检验 6.当存在异方差现象时,估计模型参数的适当方法是 ( ) A.加权最小二乘法 B.工具变量法 C.广义差分法 D.使用非样本先验信息 7.加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即 ( ) A.重视大误差的作用,轻视小误差的作用 B.重视小误差的作用,轻视大误差的作用 C.重视小误差和大误差的作用 D.轻视小误差和大误差的作用 8.如果戈里瑟检验表明,普通最小二乘估计结果的残差i e 与i x 有显著的形式 i i i v x e +=28715.0的相关关系(i v 满足线性模型的全部经典假设),则用加权最小二 乘法估计模型参数时,权数应为 ( ) A. i x B. 21i x C. i x 1 D. i x 1 9.如果戈德菲尔特——匡特检验显著,则认为什么问题是严重的 ( ) A.异方差问题 B.序列相关问题 C.多重共线性问题 D.设定误差问题 10.设回归模型为i i i u bx y +=,其中i i x u Var 2)(σ=,则b 的最有效估计量为( ) A. ∑∑=2?x xy b B. 2 2)(?∑∑∑∑∑--=x x n y x xy n b C. x y b =? D. ∑=x y n b 1? 二、多项选择 1.下列计量经济分析中那些很可能存在异方差问题( ) A.用横截面数据建立家庭消费支出对家庭收入水平的回归模型 B.用横截面数据建立产出对劳动和资本的回归模型 C.以凯恩斯的有效需求理论为基础构造宏观计量经济模型
异方差性的检验及处理方法
实验四异方差性 【实验目的】 掌握异方差性的检验及处理方法 【实验内容】 建立并检验我国制造业利润函数模型 【实验步骤】 【例1】表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。 一、检验异方差性 ⒈图形分析检验 ⑴观察销售利润(Y)与销售收入(X)的相关图(图1):SCAT X Y 图1 我国制造工业销售利润与销售收入相关图 从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。
⑵残差分析 首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。 图2 我国制造业销售利润回归模型残差分布 图2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。 ⒉Goldfeld-Quant检验 ⑴将样本按解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本) ⑵利用样本1建立回归模型1(回归结果如图3),其残差平方和为2579.587。 SMPL 1 10 LS Y C X 图3 样本1回归结果 ⑶利用样本2建立回归模型2(回归结果如图4),其残差平方和为63769.67。 SMPL 19 28 LS Y C X
图4 样本2回归结果 ⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。 取 05 .0=α时,查F 分布表得 44.3)1110,1110(05.0=----F ,而 44.372.2405.0=>=F F ,所以存在异方差性 ⒊White 检验 ⑴建立回归模型:LS Y C X ,回归结果如图5。 图5 我国制造业销售利润回归模型 ⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图6。 图6 White 检验结果
异方差的检验与修正
财经学院 本科实验报告 学院(部)统计学院 实验室313 课程名称计量经济学 学生姓名 学号1204100213 专业统计学 教务处制 2014年12 月15 日
《异方差》实验报告
五、实验过程原始记录(数据、图表、计算等) 一.选择数据 1.建立工作文件并录入数据File\New\workfile, 弹出Workfile create 对话框中选择数据类型。Object\new object\group,按向上的方向键,出现两个obs 后输入数据. 中国地2006年各地区农村居民家庭人均纯收入与消费支出 单位:元 城市 y x1 x2 城市 y x1 x2 5724.5 958.3 7317.2 2732.5 1934.6 1484.8 3341.1 1738.9 4489 3013.3 1342.6 2047 2495.3 1607.1 2194.7 3886 1313.9 3765.9 2253.3 1188.2 1992.7 广西 2413.9 1596.9 1173.6 2772 2560.8 781.1 2232.2 2213.2 1042.3 3066.9 2026.1 2064.3 2205.2 1234.1 1639.7 2700.7 2623.2 1017.9 2395 1405 1597.4 2618.2 2622.9 929.5 1627.1 961.4 1023.2 8006 532 8606.7 2195.6 1570.3 680.2 4135.2 1497.9 4315.3 2002.2 1399.1 1035.9 6057.2 1403.1 5931.7 2181 1070.4 1189.8 2420.9 1472.8 1496.3 1855.5 1167.9 966.2 3591.4 1691.4 3143.4 2179 1274.3 1084.1 2676.6 1609.2 1850.3 2247 1535.7 1224.4 3143.8 1948.2 2420.1 2032.4 2267.4 469.9 2229.3 1844.6 1416.4 二.对数据进行参数估计,得出多元线性回归模型 1.模型设定为εβββ+++=23121i i i X X Y Yi ----人均消费支出 X1--从事农业经营的纯收入 X2--其他来源的纯收入 2.点Quick\estimate equation,在弹出的对话框中输入”Y C X ”,结果如下:
实验异方差地检验与修正
实验异方差的检验与修正 实验目的 1、理解异方差的含义后果、 2、学会异方差的检验与加权最小二乘法 实验容 一、准备工作。建立工作文件,并输入数据,用普通最小二乘法估计方程(操作 步骤与方法同前),得到残差序列。 表2列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。 表2 我国制造工业1998年销售利润与销售收入情况 二、异方差的检验 1、图形分析检验 ⑴观察销售利润(Y)与销售收入(X)的相关图(图3-1):SCAT X Y
图3-1 我国制造工业销售利润与销售收入相关图 从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 ⑵残差分析 首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。 图3-2 我国制造业销售利润回归模型残差分布 图3-2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。 2、Goldfeld-Quant检验 ⑴将样本安解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本) ⑵利用样本1建立回归模型1(回归结果如图3-3),其残差平方和为2579.587。 SMPL 1 10 LS Y C X
图3-3 样本1回归结果 ⑶利用样本2建立回归模型2(回归结果如图3-4),其残差平方和为63769.67。 SMPL 19 28 LS Y C X 图3-4 样本2回归结果 ⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。 取05.0=α时,查F 分布表得44.3)1110,1110(05.0=----F ,而 44.372.2405.0=>=F F ,所以存在异方差性 3、White 检验 ⑴建立回归模型:LS Y C X ,回归结果如图3-5。
异方差性及其检验
异方差性及其检验 I 概念 对于多元线性回归模型 同方差性假设为 如果出现 即对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,不具有等同的分散程度,则认为出现了异方差(Heteroskedasticity ) II 类型 同方差性假定是指,回归模型中不可观察的随机误差项i u 以解释变量X 为条件的方差是一个常数,因此每个i u 的条件方差不随X 的变化而变化,即有 2()i i f X σ=≠常数 在异方差的情况下,总体中的随机误差项i u 的方差 2 i σ不再是常数, 通常它随解释变量值的变化而变化,即 异方差一般可归结为三种类型: 01122 1,2, ,i i i k ki i Y X X X i n ββββμ=+++ ++=2(), 1,2,...,i Var i n μσ==2(), 1,2,...,i i Var i n μσ==2() i i f X σ=
异方差类型图: III来源 (1)截面数据(不同样本点除解释变量外其他影响差异大) (2)时间序列(规模差异) (3)分组数据、异常值等 (4)模型函数形式设置不正确和数据变形不正确 (5)边错边改学习模型 IV影响 计量经济学模型一旦出现异方差,如果仍然用普通最小二乘法估计模型参数,会产生一系列不良后果。 (1)参数估计量非有效 (2)OLS估计的随机干扰项的方差不再是无偏的
(3)基于OLS估计的各种统计检验非有效 (4)模型的预测失效 V检验 异方差性,即相对于不同的样本点,也就是相对于不同的解释变量观测值,随机干扰项具有不同的方差,那么检验异方差性,也就是检验随机干扰项的方差与解释变量观测值之间的相关性。 一般检验方法如下: (1)图示检验法 (2)帕克(Park)检验与戈里瑟(Gleiser)检验 (3)G-Q(Goldfeld-Quandt)检验 (4)F检验 (5)拉格朗日乘子检验 (6)怀特检验 (具体步骤随后介绍) VI修正方法 加权最小二乘法 定义:加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用OLS法估计其参数。 基本思想:在采用OLS方法时,对较小的残差平方2? e赋予较大的权 i 重,对较大的2? e赋予较小的权重,以对残差提供的信息的重要程度 i 作一番修正,提高参数估计的精确程度。 不同形式的异方差要求用不同的加权方法来处理:
检验和消除异方差和自相关的报告
消除异方差和自相关的实验报告【实验内容】 通过查询中国统计局的2012年中国统计年鉴及新浪财经数据网,获得1980年--2012年各项指标的数据,如下表所示: 年份Y-出口贸易总额 (亿美元)X-外商直接投资(亿美元) 1980181.19 3.54 1981220.10 3.54 1982223.20 3.54 1983222.309.20 1984261.4014.20 1985273.5019.56 1986309.4022.44 1987394.4023.14 1988475.2031.94 1989525.4033.92 1990620.9134.87 1991719.1043.66 1992849.40110.08 1993917.44275.15 19941210.06337.67 19951487.80375.21 19961510.48417.26 19971827.92452.57 19981837.09454.63 19991949.31403.19
20002492.03407.15 20012660.98468.78 20023255.96527.43 20034382.28535.05 20045933.26606.30 20057619.53603.25 20069689.36630.21 200712177.76747.68 200814306.93923.95 200912016.12900.33 201015779.301057.40 201118986.001160.23 201220489.301116.16【实验步骤——检验并消除异方差】 一检查模型是否存在异方差性 1、图形分析检验 (1)散点相关图分析
异方差性的检验和补救
异方差性的检验和补救 一、研究目的和要求 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型,检验其是否存在异方差,并加以补救。 表1 我国制造工业1998年销售利润与销售收入情况 二、参数估计 EVIEWS 软件估计参数结果如下
Dependent Variable: Y Method: Least Squares Date: 06/01/16 Time: 20:16 Sample: 1 28 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 12.03349 19.51809 0.616530 0.5429 X 0.104394 0.008442 12.36658 0.0000 R-squared 0.854694 Mean dependent var 213.4639 Adjusted R-squared 0.849105 S.D. dependent var 146.4905 S.E. of regression 56.90455 Akaike info criterion 10.98938 Sum squared resid 84191.34 Schwarz criterion 11.08453 Log likelihood -151.8513 Hannan-Quinn criter. 11.01847 F-statistic 152.9322 Durbin-Watson stat 1.212781 Prob(F-statistic) 0.000000 用规范的形式将参数估计和检验结果写下 2?12.033490.104394(19.51809)(0.008442) =(0.616530) (12.36658)0.854694152.9322 i Y X t R F =+ = = 三、 检验模型的异方差 (一) 图形法 1. 相关关系图 X Y X Y 相关关系图
异方差检验
七、 异方差与自相关 一、背景 我们讨论如果古典假定中的同方差和无自相关假定不能得到满足,会引起什么样的估计问题呢?另一方面,如何发现问题,也就是发现和检验异方差以及自相关的存在性也是一个重要的方面,这个部分就是就这个问题进行讨论。 二、知识要点 1、引起异方差的原因及其对参数估计的影响 2、异方差的检验(发现异方差) 3、异方差问题的解决办法 4、引起自相关的原因及其对参数估计的影响 5、自相关的检验(发现自相关) 6、自相关问题的解决办法 (时间序列部分讲解) 三、要点细纲 1、引起异方差的原因及其对参数估计的影响 原因:引起异方差的众多原因中,我们讨论两个主要的原因,一是模型的设定偏误,主要指的是遗漏变量的影响。这样,遗漏的变量就进入了模型的残差项中。当省略的变量与回归方程中的变量有相关关系的时候,不仅会引起内生性问题,还会引起异方差。二是截面数据中总体各单位的差异。 后果:异方差对参数估计的影响主要是对参数估计有效性的影响。在存在异方差的情况下,OLS 方法得到的参数估计仍然是无偏的,但是已经不具备最小方差性质。一般而言,异方差会引起真实方差的低估,从而夸大参数估计的显著性,即是参数估计的t 统计量偏大,使得本应该被接受的原假设被错误的拒绝。 2、异方差的检验 (1)图示检验法 由于异方差通常被认为是由于残差的大小随自变量的大小而变化,因此,可以通过散点图的方式来简单的判断是否存在异方差。具体的做法是,以回归的残差的平方2i e 为纵坐标,回归式中的某个解释变量i x 为横坐标,画散点图。如果散点图表现出一定的趋势,则可以判断存在异方差。 (2)Goldfeld-Quandt 检验
违背基本假设的问题:多重共线性异方差和自相关
第5章、违背基本假设的问题: 多重共线性、异方差和自相关 回顾并再次记住最小二乘法(LS)的三个基本假设: 1.y=Xβ+ε 2.Rank(X)=K 3.ε|X~N(0,σ2I) 1 / 51
§1、多重共线性(multicollinearity) 1、含义及后果 1)完全的多重共线性 如果存在完全的多重共线性(perfect multicollinearity),即在X中存在不完全为0的a i,使得 a1x1+…+a K x K=0 即X的列向量之间存在线性相关。因此,有Rank(X) 3 / 51 4 / 51 2)近似共线性 常见为近似共线性,即 a 1x 1+…+a K x K ≈0 则有|X’X|≈0,那么(X’X)-1对角线元素较大。由于 21|[,(')]b X N X X βσ- , 21|[,(')]k k kk b X N X X βσ- , 所以b k 的方差将较大。 例子:Longley 是著名例子。 5 / 51 6 / 51 2、检验方法 1)VIF 法(方差膨胀因子法,variance inflation factor ) 第j 个解释变量的VIF 定义为 2 1 VIF 1j j R = - 此处2j R 是第j 个解释变量对其他解释变量进行回归的确定系数。若2j R 接近于1,那么VIF 数值将较大,说明第j 个解释变量与其他解释变量之间存在线性关系。从而,可以用VIF 来度量多重共线性的严重程度。当 2j R 大于0.9,也就是VIF 大于10时,认为自变量之间存在比较严重的 第四章 多重共线性 一、判断题 1、多重共线性是一种随机误差现象。(F ) 2、多重共线性是总体的特征。(F ) 3、在存在不完全多重共线性的情况下,回归系数的标准差会趋于变小,相应的t 值会趋于变大。(F ) 4、尽管有不完全的多重共线性,OLS 估计量仍然是最优线性无偏估计量。(T ) 5、在高度多重共线的情形中,要评价一个或多个偏回归系数的个别显著性是不可能的。(T ) 6、变量的两两高度相关并不表示高度多重共线性。(F ) 7、如果分析的目的仅仅是预测,则多重共线性一定是无害的。(T ) 8、在多元回归中,根据通常的t 检验,每个参数都是统计上不显著的,你就不会得到一个高的2 R 值。(F ) 9、如果简单相关系数检测法证明多元回归模型的解释变量两两不相关,则可以判断解释变量间不存在多重共线性。( F ) 10、多重共线性问题的实质是样本问题,因此可以通过增加样本信息得到改善。(T ) 11、虽然多重共线性下,很难精确区分各个解释变量的单独影响,但可据此模型进行预测。(T ) 12、如果回归模型存在严重的多重共线性,可不加分析地去掉某个解释变量从而消除多重共线性。(F ) 13、多重共线性的存在会降低OLS 估计的方差。(F ) 14、随着多重共线性程度的增强,方差膨胀因子以及系数估计误差都在增大。(T ) 15、解释变量和随机误差项相关,是产生多重共线性的原因。(F ) 16、对于模型i ni n i 110i u X X Y ++++=βββ ,n 1i ,, =;如果132X X X -=,模型必然存在解释变量的多重共线性问题。(T ) 17、多重共线性问题是随机扰动项违背古典假定引起的。(F ) 18、存在多重共线性时,模型参数无法估计。(F ) 二、单项选择题 1、在线性回归模型中,若解释变量1X 和2X 的观测值成比例,既有12i i X kX =,其中k 为 非零常数,则表明模型中存在 ( B ) A 、异方差 B 、多重共线性 C 、序列相关 D 、随机解释变量 2、 在多元线性回归模型中,若某个解释变量对其余解释变量的可决系数接近1,则表明模型中存在 ( C ) A 、异方差性 B 、序列相关 第五章 异方差性 一、判断题 1. 在异方差的情况下,通常预测失效。( T ) 2. 当模型存在异方差时,普通最小二乘法是有偏的。( F ) 3. 存在异方差时,可以用广义差分法进行补救。(F ) 4. 存在异方差时,普通最小二乘法会低估参数估计量的方差。(F ) 5. 如果回归模型遗漏一个重要变量,则OLS 残差必定表现出明显的趋势。( T ) 二、单项选择题 方法用于检验( A ) A.异方差性 B.自相关性 C.随机解释变量 D.多重共线性 2.在异方差性情况下,常用的估计方法是( D ) A.一阶差分法 B.广义差分法 C.工具变量法 D.加权最小二乘法 检验方法主要用于检验( A ) A.异方差性 B.自相关性 C.随机解释变量 D.多重共线性 4.下列哪种方法不是检验异方差的方法( D ) A.戈德菲尔特——匡特检验 B.怀特检验 C.戈里瑟检验 D.方差膨胀因子检验 5.加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即( B ) A.重视大误差的作用,轻视小误差的作用 B.重视小误差的作用,轻视大误差的作用 C.重视小误差和大误差的作用 D.轻视小误差和大误差的作用 6.如果戈里瑟检验表明,普通最小二乘估计结果的残差i e 与i x 有显著的形式 i i i v x e +=28715.0的相关关系(i v 满足线性模型的全部经典假设),则用加权最小二乘法估计模型参数时,权数应为( B ) A. i x B. 21i x C. i x 1 D. i x 1 7.设回归模型为i i i u bx y +=,其中()2i 2i x u Var σ=,则b 的最有效估计量为( D ) 实验四-异方差性的检验与处理 实验四 异方差性的检验及处理(2学时) 一、实验目的 (1)、掌握异方差检验的基本方法; (2)、掌握异方差的处理方法。 二、实验学时:2学时 三、实验要求 (1)掌握用MATLAB 软件实现异方差的检验和处理; (2)掌握异方差的检验和处理的基本步骤。 四、实验原理 1、异方差检验的常用方法 (1) 用X-Y 的散点图进行判断 (2). 22 ?(,)(,)e x e y %%或的图形 ,),x )i i y %%i i ((e 或(e 的图形) (3) 等级相关系数法(又称Spearman 检验) 是一种应用较广的方法,既可以用于大样本,也可与小样本。 :i u 0原假设H 是等方差的;:i u 0备择假设H 是异方差; 检验的三个步骤 ① ?t t y y =-%i e ② |i x %%i i 将e 取绝对值,并把|e 和按递增或递减次序排序, 计算Spearman 系数rs ,其中:2 1n i i d =∑s 2 6r =1-n(n -1) |i x %i i 其中, n 为样本容量d 为|e 和的等级的差数。 ③ 做等级相关系数的显著性检验。n>8时, 22(2) 1s s n t t n r -= --0当H 成立时, /2(2),t t n α≤-若认为异方差性问题不存在; /2(2),t t n α>-反之,若||i i e x %说明与之间存在系统关系, 异方差问题存在。 (4) 帕克(Park)检验 帕克检验常用的函数形式: 若α在统计上是显著的,表明存在异方差性。 2、异方差性的处理方法: 加权最小二乘法 如果在检验过程中已经知道:222 ()()()i i i ji u Var u E u f x σσ=== 则将原模型变形为: 121()()()() () i i p pi i ji ji ji ji ji y x x u f x f x f x f x f x βββ=+?++?+L 在该模型中: 22 11 ( )()()()()() i i ji u u ji ji ji Var u Var u f x f x f x f x σσ=== 即满足同方差性。于是可以用OLS 估计其参数,得到关于参数12,,,p βββL 的无偏、有效估计量。 五、实验举例 例1、某地区居民的可支配收入x(千元)与居民消费支出y(千元)的数据如下: No x y no x y 1 10 8 16 25 19.1 2 10 8.2 17 25 23.5 3 10 8.3 18 25 22. 4 4 10 8.1 19 2 5 23.1 5 10 8.7 20 25 15.1 6 15 12.3 21 30 24.2 7 15 9.4 22 30 16.7 8 15 11.6 23 30 27 9 15 12 24 30 26 10 15 8.9 25 30 22.1 11 20 15 26 35 30.5 12 20 16 27 35 28.7 13 20 12 28 35 31.1 14 20 13 29 35 20 15 20 19.1 30 35 29.9第四章 多重共线性 答案(1)
第五章 异方差性 答案
实验四-异方差性的检验与处理