Hadoop安装配置
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
Hadoop环境搭建及wordcount实例运行
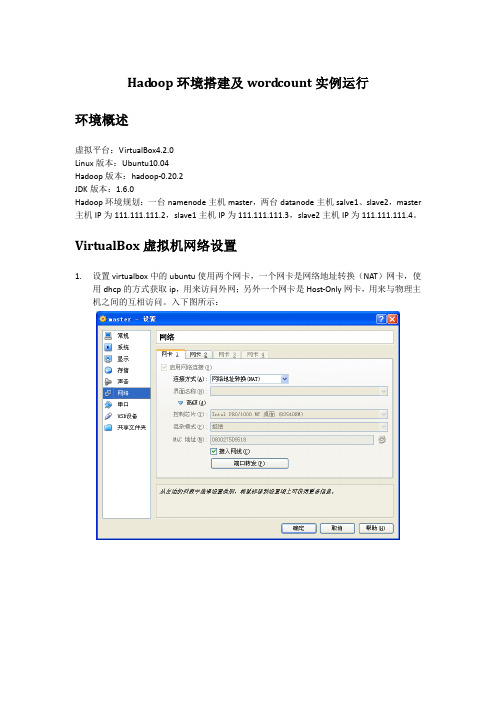
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
hadoop核心组件概述及hadoop集群的搭建

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。
ubuntu下hadoop配置指南

ubuntu下hadoop配置指南目录1.实验目的2.实验内容(hadoop伪分布式与分布式集群环境配置)3.运行wordcount词频统计程序一 . 实验目的通过学习和使用开源的Apache Hadoop工具,亲身实践云计算环境下对海量数据的处理,理解并掌握分布式的编程模式MapReduce,并能够运用MapReduce编程模式完成特定的分布式应用程序设计,用于处理实际的海量数据问题。
二 . 实验内容1.实验环境搭建1.1. 前期准备操作系统:Linux Ubuntu 10.04Java开发环境:需要JDK 6及以上,Ubuntu 10.04默认安装的OpenJDK可直接使用。
不过我使用的是sun的jdk,从官方网站上下载,具体可以参考博客:ubuntu下安装JDK 并配置java环境Hadoop开发包:试过了hadoop的各种版本,包括0.20.1,0.20.203.0和0.21.0,三个版本都可以配置成功,但是只有0.20.1这个版本的eclipse插件是可用的,其他版本的eclipse插件都出现各种问题,因此当前使用版本为hadoop-0.20.1Eclipse:与hadoop-0.20.1的eclipse插件兼容的只有一些低版本的eclipse,这里使用eclipse-3.5.2。
1.2. 在单节点(伪分布式)环境下运行Hadoop(1)添加hadoop用户并赋予sudo权限(可选)为hadoop应用添加一个单独的用户,这样可以把安装过程和同一台机器上的其他软件分离开来,使得逻辑更加清晰。
可以参考博客:Ubuntu-10.10如何给用户添加sudo权限。
(2)配置SSH无论是在单机环境还是多机环境中,Hadoop均采用SSH来访问各个节点的信息。
在单机环境中,需要配置SSH 来使用户hadoop 能够访问localhost 的信息。
首先需要安装openssh-server。
[sql]view plaincopyprint?1. s udo apt-get install openssh-server其次是配置SSH使得Hadoop应用能够实现无密码登录:[sql]view plaincopyprint?1. s u - hadoop2. s sh-keygen -trsa -P ""3. c p ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys第一条命令将当前用户切换为hadoop(如果当前用户就是hadoop,则无需输入),第二条命令将生成一个公钥和私钥对(即id_dsa和id_dsa.pub两个文件,位于~/.ssh文件夹下),第三条命令使得hadoop用户能够无需输入密码通过SSH访问localhost。
1.Hadoop集群搭建(单机伪分布式)

1.Hadoop集群搭建(单机伪分布式)>>>加磁盘1)⾸先先将虚拟机关机2)选中需要加硬盘的虚拟机:右键-->设置-->选中硬盘,点击添加-->默认选中硬盘,点击下⼀步-->默认硬盘类型SCSI(S),下⼀步-->默认创建新虚拟磁盘(V),下⼀步-->根据实际需求,指定磁盘容量(单个或多个⽂件⽆所谓,选哪个都⾏),下⼀步。
-->指定磁盘⽂件,选择浏览,找到现有虚拟机的位置(第⼀次出现.vmdk⽂件的⽂件夹),放到⼀起,便于管理。
点击完成。
-->点击确定。
3) 可以看到现在选中的虚拟机有两块硬盘,点击开启虚拟机。
这个加硬盘只是在VMWare中,实际⼯作中直接买了硬盘加上就可以了。
4)对/dev/sdb进⾏分区df -h 查看当前已⽤磁盘分区fdisk -l 查看所有磁盘情况磁盘利⽤情况,依次对磁盘命名的规范为,第⼀块磁盘sda,第⼆块为sdb,第三块为sdc。
可以看到下图的Disk /dev/sda以第⼀块磁盘为例,磁盘分区的命名规范依次为sda1,sda2,sda3。
同理也会有sdb1,sdb2,sdb3。
可以参照下图的/dev/sda1。
下⾯的含义代表sda盘有53.7GB,共分为6527个磁柱,每个磁柱单元Units的⼤⼩为16065*512=8225280 bytes。
sda1分区为1-26号磁柱,sda2分区为26-287号磁柱,sda3为287-6528号磁柱下⾯的图⽚可以看到,还未对sdb磁盘进⾏分区fdisk /dev/sdb 分区命令可以选择m查看帮助,显⽰命令列表p 显⽰磁盘分区,同fdisk -ln 新增分区d 删除分区w 写⼊并退出选w直接将分区表写⼊保存,并退出。
mkfs -t ext4 /dev/sdb1 格式化分区,ext4是⼀种格式mkdir /newdisk 在根⽬录下创建⼀个⽤于挂载的⽂件mount /dev/sdb1 /newdisk 挂载sdb1到/newdisk⽂件(这只是临时挂载的解决⽅案,重启机器就会发现失去挂载)blkid /dev/sdb1 通过blkid命令⽣成UUIDvi /etc/fstab 编辑fstab挂载⽂件,新建⼀⾏挂载记录,将上⾯⽣成的UUID替换muount -a 执⾏后⽴即⽣效,不然的话是重启以后才⽣效。
Win7安装Hadoop
作者:Windyqin 于2015/2/81、本人电脑是Win7 64位系统的:2、JDK 版本:3、Cygwin 版本:官网自行下载4、Hadoop 版本:官网自行下载,下载稳定版的吧下面就开始安装啦~~~~一、安装JDK,安装时注意,最好不要安装到带有空格的路径名下,例如:Programe Files,否则在配置Hadoop的配置文件时会找不到JDK。
我安装的路径为C:\Java\jdk1.7.0_21,安装完配置环境变量:①.安装完成后开始配置环境变量,右击我的电脑,点击属性②.在出现的对话框中选择高级系统设置,在出现的对话框中选择环境变量③.新建名为”JAVA_HOME“的变量名,变量值为之前安装jdk的目录,例如本人的为”C:\Java\jdk1.7.0_21“④.在已有的系统变量”path“的变量值加上”%JAVA_HOME%\bin;(注意,每个变量值是以”;“隔开,变量值开头的分号就起这个作用)自此配置完成。
二、安装Cygwin,下载地址:/,根据操作系统的需要下载32位或64的安装文件。
①. 双击下载好的安装文件,点击下一步,选择install from internet②选择安装路径,下一步,点下一步,选择合适的安装源,点击下一步③在Select Packages界面里,Category展开net,选择如下openssh和openssl两项④如果要在Eclipe上编译Hadoop,需要安装Category为Base下的sed⑤如果想在Cygwin上直接修改hadoop的配置文件,可以安装Editors下的vim⑥.点击“下一步”,等待安装完成。
三、配置环境变量,在“我的电脑”上点击右键,选择菜单中的“属性",点击属性对话框上的高级页签,点击”环境变量"按钮,在系统变量列表里双击“Path”变量,在变量值后输入安装的Cygwin的bin目录,例如:D:\cygwin64\bin四、安装sshd服务,双击桌面上的Cygwin图标,启动Cygwin,执行ssh-host-config -y命令五、执行后,会提示输入密码,否则会退出该配置,此时输入密码和确认密码,回车。
linuxxshelljdkhadoop(环境搭建)虚拟机安装(大数据搭建环境)
linuxxshelljdkhadoop(环境搭建)虚拟机安装(⼤数据搭建环境)【hadoop是2.6.5版本xshell是6版本jdk是1.8.0.131 虚拟机是CentOS-6.9-x86_64-bin-DVD1.iso vmware10】1.创建虚拟机第⼀步:在VMware中创建⼀台新的虚拟机。
如图2.2所⽰。
图2.2第⼆步:选择“⾃定义安装”,然后单击“下⼀步”按钮,如图2.3所⽰。
图2.3第三步:单击“下⼀步” 按钮,如图2.4所⽰。
图2.4第四步:选择“稍后安装操作系统”,然后单击“下⼀步” 按钮,如图2.5所⽰。
图2.5第五步:客户机操作系统选择Linux,版本选择“CentOS 64位”,然后单击“下⼀步” 按钮,如图2.6所⽰。
图2.6第六步:在这⾥可以选择“修改虚拟机名称”和“虚拟机存储的物理地址”,如图2.7所⽰。
图2.7第七步:根据本机电脑情况给Linux虚拟机分配“处理器个数”和每个处理器的“核⼼数量”。
注意不能超过⾃⼰电脑的核数,推荐处理数量为1,每个处理器的核⼼数量为1,如图2.8所⽰。
图2.8第⼋步:给Linux虚拟机分配内存。
分配的内存⼤⼩不能超过⾃⼰本机的内存⼤⼩,多台运⾏的虚拟机的内存总合不能超过⾃⼰本机的内存⼤⼩,如图2.9所⽰。
图2.9第九步:使⽤NAT⽅式为客户机操作系统提供主机IP地址访问主机拨号或外部以太⽹⽹络连接,如图2.10所⽰。
图2.10第⼗步:选择“SCSI控制器为LSI Logic(L)”,然后单击“下⼀步” 按钮,如图2.11所⽰。
图2.11第⼗⼀步:选择“虚拟磁盘类型为SCSI(S)”,然后单击“下⼀步” 按钮,如图2.12所⽰。
图2.12第⼗⼆步:选择“创建新虚拟磁盘”,然后单击“下⼀步” 按钮,如图2.13所⽰。
图2.13第⼗三步:根据本机的磁盘⼤⼩给Linux虚拟机分配磁盘,并选择“将虚拟机磁盘拆分为多个⽂件”,然后单击“下⼀步”按钮,如图2.14所⽰。
大数据--Hadoop集群环境搭建
⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
Hadoop大数据平台安装实验(详细步骤)(虚拟机linux)
大数据技术实验报告大数据技术实验一Hadoop大数据平台安装实验1实验目的在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建Hadoop(HDFS、MapReduce、HBase、Hive)、Spark、Scala、Storm、Kafka、JDK、MySQL、ZooKeeper等的大数据采集、处理分析技术环境。
2实验环境个人笔记本电脑Win10、Oracle VM VirtualBox 5.2.44、CentOS-7-x86_64-Minimal-1511.iso3实验步骤首先安装虚拟机管理程序,然后创建三台虚拟服务器,最后在虚拟服务器上搭建以Hadoop 集群为核心的大数据平台。
3.1快速热身,熟悉并操作下列Linux命令·创建一个初始文件夹,以自己的姓名(英文)命名;进入该文件夹,在这个文件夹下创建一个文件,命名为Hadoop.txt。
·查看这个文件夹下的文件列表。
·在Hadoop.txt中写入“Hello Hadoop!”,并保存·在该文件夹中创建子文件夹”Sub”,随后将Hadoop.txt文件移动到子文件夹中。
·递归的删除整个初始文件夹。
3.2安装虚拟机并做一些准备工作3.2.1安装虚拟机下载系统镜像,CentOS-7-x86_64-Minimal-1511.iso。
虚拟机软件使用Oracle VM VirtualBox 5.2.44。
3.2.2准备工作关闭防火墙和Selinux,其次要安装perl 、libaio、ntpdate 和screen。
然后检查网卡是否开机自启,之后修改hosts,检查网络是否正常如图:然后要创建hadoop用户,之后多次用,并且生成ssh 密钥并分发。
最后安装NTP 服务。
3.3安装MYSQL 3.3.1安装3.3.2测试3.4安装ZooKeeper。
Hadoop环境搭建
Hadoop环境搭建啥是⼤数据?问啥要学⼤数据?在我看来⼤数据就很多的数据,超级多,咱们⽇常⽣活中的数据会和历史⼀样,越来越多⼤数据有四个特点(4V):⼤多样快价值学完⼤数据我们可以做很多事,⽐如可以对许多单词进⾏次数查询(本节最后的实验),可以对股市进⾏分析,所有的学习都是为了赚⼤钱!(因为是在Linux下操作,所以⽤到的全是Linux命令,不懂可以百度,这篇⽂章有⼀些简单命令。
常⽤)第⼀步安装虚拟机配置环境1.下载虚拟机,可以⽤⾃⼰的,没有的可以下载这个 passowrd:u8lt2.导⼊镜像,可以⽤这个 password:iqww (不会创建虚拟机的可以看看,不过没有这个复杂,因为导⼊就能⽤)3.更换主机名,vi /etc/sysconfig/network 改HOSTNAME=hadoop01 (你这想改啥改啥,主要是为了清晰,否则后⾯容易懵)注:在这⾥打开终端4.查看⽹段,从编辑-虚拟⽹络编辑器查看,改虚拟机⽹段,我的是192.168.189.128-254(这个你根据⾃⼰的虚拟机配置就⾏,不⽤和我⼀样,只要记住189.128这个段就⾏)5.添加映射关系,输⼊:vim /etc/hosts打开⽂件后下⾯添加 192.168.189.128 hadoop01(红⾊部分就是你们上⾯知道的IP)(这⾥必须是hadoop01,为了⽅便后⾯直接映射不⽤敲IP)6.在配置⽂件中将IP配置成静态IP 输⼊: vim /etc/sysconfig/network-scripts/ifcfg-eth0 (物理地址也要⼀样哦!不知道IP的可以输⼊:ifconfig 查看⼀下)7.重启虚拟机输⼊:reboot (重启后输⼊ ping 能通就说明没问题)第⼆步克隆第⼀台虚拟机,完成第⼆第三虚拟机的配置1.⾸先把第⼀台虚拟机关闭,在右击虚拟机选项卡,管理-克隆即可(克隆两台⼀台hadoop02 ⼀台hadoop03)2.克隆完事后,操作和第⼀部基本相同唯⼀不同的地⽅是克隆完的虚拟机有两块⽹卡,我们把其中⼀个⽹卡注释就好(⼀定牢记!通过这⾥的物理地址⼀定要和配置⽂件中的物理地址相同)输⼊:vi /etc/udev/rules.d/70-persistent-net.rules 在第⼀块⽹卡前加# 将第⼆块⽹卡改为eth03.当三台机器全部配置完之后,再次在hosts⽂件中加⼊映射达到能够通过名称互相访问的⽬的输⼊:vim /etc/hosts (三台都要如此设置)(改完之后记得reboot重启)第三步使三台虚拟机能够通过SHELL免密登录1.查看SSH是否安装 rmp -qa | grep ssh (如果没有安装,输⼊sudo apt-get install openssh-server)2.查看SSH是否启动 ps -e | grep sshd (如果没有启动,输⼊sudo /etc/init.d/ssh start)3.该虚拟机⽣成密钥 ssh-keygen -t rsa(连续按下四次回车就可以了)4.将密钥复制到另外⼀台虚拟机⽂件夹中并完成免密登录输⼊:ssh-copy-id -i ~/.ssh/id_rsa.pub 2 (同样把秘钥给hadoop03和⾃⼰)(输⼊完后直接下⼀步,如果下⼀步失败再来试试改这个修改/etc/ssh/ssh_config中的StrictHostKeyCheck ask )5.之后输⼊ ssh hadoop02就可以正常访问第⼆台虚拟机啦注:可能你不太理解这是怎么回事,我这样解释⼀下,免密登录是为了后⾯进⾏集群操作时⽅便,⽣成秘钥就像是⽣成⼀个钥匙,这个钥匙是公钥,公钥可以打开所有门,之后把这个钥匙配两把,⼀把放在hadoop02的那⾥,⼀把放在hadoop03的那⾥,这样hadoop01可以对hadoop02和hadoop03进⾏访问。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop安装配置 一、软件 Java:jdk-8u45-linux-x64.gz Hadoop:hadoop-2.6.0.tar.gz 虚拟机:VMware-workstation-full-11.1.0-2496824.exe Linux系统:CentOS-7-x86_64-DVD-1503-01.iso Linux远程登录软件:Xmanager-v5.0.0547
二、集群说明 Hadoop环境搭建使用1个Namenode和2个Datanode,说明如下 hostname IP 角色 server 192.168.1.130 Namenode slave1 192.168.1.131 Datanode slave2 192.168.1.132 Datanode
三、安装与配置 *说明:若hadoop用户权限不够,在命令前添加sudo,系统提示输入密码后即可
(1) 安装Vmware Workstation (2) 安装Linux系统 先安装一个Linux系统,在Vmware Workstation选择自定义安装,使用ISO镜像,虚拟机设置如下: 项目 设置 说明 Linux全名 hadoop 计算机名,自定义 用户名 hadoop 自定义 密码 hadoop 自定义 处理器数量 2 自定义 每个处理器核心数量 2 自定义 内存 1G 自定义 网络连接 使用桥接网络 I/O控制 LSI Logic 选择默认 虚拟磁盘类型 SCSI 选择默认 磁盘 创建新虚拟磁盘 最大磁盘大小 30G 自定义,一般不低于推荐值 存储模式 存储为单个文件 (3) 使当前用户获得sudo权限 进入超级用户模式,输入"su -",输入超级用户密码(hadoop) 添加文件的写权限,输入命令“chmod u+w /etc/sudoers” 编辑/etc/sudoers文件,找到“root ALL=(ALL) ALL”,在其下添加“hadoop ALL=(ALL) ALL ”(hadoop为用户名),保存退出 如果撤销文件的写权限,输入命令"chmod u-w /etc/sudoers",此处不需要 使用 su hadoop命令切换为hadoop用户,以后操作均使用hadoop身份 (4) 配置静态IP 编辑/etc/sysconfig/network-scripts/ifcfg-eno16777736 文件,如下所示,带#号的为修改或添加项 TYPE=Ethernet BOOTPROTO=static #改为静态 DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_PEERDNS=yes IPV6_PEERROUTES=yes IPV6_FAILURE_FATAL=no NAME="Auto Ethernet" UUID=76304098-8f46-4185-8337-bb7f0d90423e #随系统而不同,不用修改 ONBOOT=yes #改为yes,开机启动网卡 #以下为添加项,可在路由器中查找 IPADDR0=192.168.1.130 #自己要设置的ip地址 GATEWAY0=192.168.1.1 #网关 PREFIXO0=24 #子网掩码,24即255.255.255.0 DNS1=202.114.64.2 #DNS服务器地址 DNS2=202.114.96.2 #备用DNS服务器地址
*网络配置一般可在路由器中查到 使用service network restart命令重启网络服务 使用ip addr命令查询ip是否为所设置的静态ip成功 (5) 修改系统hostname 编辑文件/etc/hostname,将原hostname改为server(可自定义),保存退出 (6) 修改hosts文件 编辑/etc/hosts,在文件末尾添加所有节点的IP和hostname,如下 192.168.1.130 server 192.168.1.131 slave1 192.168.1.132 slave2 (7) 建立Windows对Linux的远程连接 安装Xmanager,使用Xshell新建对server的远程连接,连接设置如下: 项目 设置 名称 server 协议 SSH 主机 192.168.1.130 连接异常关闭时自动连接 间隔30秒,限制0分钟 开启连接时要输入用户名和密码,此后可以用此操纵Linux,当然也可直接使用Linux的Terminal。 (8) 传输安装文件 建立(7)的连接成功后,打开Xshell菜单栏—窗口—传输新建文件,打开Xftp,此后可通过Xftp操作Linux文件夹/文件。将Java和hadoop的gz文件直接拖入到Linux的/home/hadoop文件夹下(可自行选择文件夹),完成传输。 (9) 安装Java和Hadoop,配置环境变量 在Terminal中,进入/home/hadoop文件夹,使用tar –zxf jdk-8u45-linux-x64.tar.gz命令解压缩Java jdk文件,得到jdk1.8.0_45文件夹,为之后使用方便,使用mv jdk1.8.0_45 jdk18命令重命名文件夹为jdk18。也可以在Xftp中直接右键重命名文件夹。按照同样方法安装hadoop,重命名文件夹为hadoop。 编辑/etc/profile文件,在文件末尾添加 export JAVA_HOME=/home/hadoop/jdk18 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/home/hadoop/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/SBIN:$PATH 保存退出,使用source /etc/profile命令让文件修改后立即生效。 使用java –version和hadoop version命令,若能正确显示软件版本号,说明安装成功 (10) 配置hadoop文件 首先在/home/hadoop下新建文件夹: mkdir –p /home/hadoop/tmp mkdir -p /home/hadoop/dfs/name mkdir -p /home/hadoop/dfs/name 然后进入/home/hadoop/hadoop/etc/hadoop文件夹,编辑文件中的段 编辑core-site.xml hadoop.tmp.dir /usr/hadoop/tmp A base for other temporary directories. fs.defaultFS hdfs://server:9000 io.file.buffer.size 4096 编辑hadoop-env.sh和yarn-env.sh,在开头添加 export JAVA_HOME=/home/hadoop/jdk18 编辑hdfs-site.xml dfs.namenode.name.dir file:/home/hadoop/dfs/name dfs.datanode.data.dir file:/home/hadoop/dfs/data dfs.replication 2 dfs.nameservices hadoop-cluster1 dfs.namenode.secondary.http-address server:50090 dfs.webhdfs.enabled true 其中dfs.replication配置了文件块的副本数,一般不大于Datanode的个数,根据实际情况设置。 编辑mapred-site.xml,由于文件夹中只有mapred-site.xml.template文件,使用cp mapred-site.xml.template mapred-site.xml命令得到mapred-site.xml文件后进行编辑 mapreduce.framework.name yarn true mapreduce.jobtracker.http.address server:50030 mapreduce.jobhistory.address server:10020