两样本均数的比较
医学统计学第七章两样本均数比较的假设检验
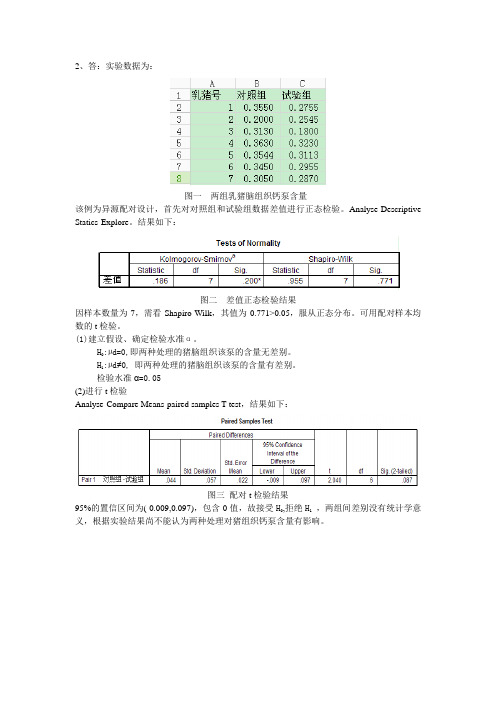
图一两组乳猪脑组织钙泵含量该例为异源配对设计,首先对对照组和试验组数据差值进行正态检验。
Analyse-Descriptive Statics-Explore。
结果如下:图二差值正态检验结果因样本数量为7,需看Shapiro-Wilk,其值为0.771>0.05,服从正态分布。
可用配对样本均数的t检验。
(1)建立假设、确定检验水准α。
H0:µd=0,即两种处理的猪脑组织该泵的含量无差别。
H1:µd≠0, 即两种处理的猪脑组织该泵的含量有差别。
检验水准α=0.05(2)进行t检验Analyse-Compare Means-paired samples T test,结果如下:图三配对t检验结果95%的置信区间为(-0.009,0.097),包含0值,故接受H0,拒绝H1,两组间差别没有统计学意义,根据实验结果尚不能认为两种处理对猪组织钙泵含量有影响。
图四A、B鼠肝中铁的含量该例为完全随机设计。
首先对A、B两组进行正态性检验。
Analyse-Descriptive Statics-Explore。
结果如下:图五A、B两组鼠肝中铁含量的正态检验因样本数量为10,需看Shapiro-Wilk,A组值为0.319>0.05,服从正态分布。
B组值为0.269>0.05,服从正态分布。
对两组进行两样本方差齐性检验,Analyse-Compare Means-Independent samples T test结果为:图六A、B两组的方差齐性检验和t检验由上图得该两组样本方差齐性检验不满足方差齐性(F=8.246,P<0.05)。
可用均数比较的t`检验。
(1)建立假设、确定检验水准α。
H0:µ1=µ2,即不同饲料对鼠肝中铁的含量无影响。
H1:µ1≠µ2,即不同饲料对鼠肝中铁的含量有影响。
检验水准α=0.05(2)进行t检验如上述图六所示,两组样本方差齐性检验不满足方差齐性时,其95%的置信区间为(-0.1674,1.64674),包含0值。
双样本均值比较分析假设检验

双样本均值比较分析假设检验在进行双样本均值比较分析假设检验之前,需要建立以下的假设:-零假设(H0):两个样本的均值相等,即差异为零。
-备择假设(H1):两个样本的均值不相等,即差异不为零。
接下来的步骤是计算样本的均值、标准差和样本容量,并且通过标准误差来计算检验统计量。
常用的检验统计量有t统计量和z统计量,选择哪种统计量取决于样本容量是否足够大。
如果样本容量足够大,通常使用z统计量进行假设检验。
计算z统计量的公式如下:z = (x1 - x2) / sqrt(s1^2 / n1 + s2^2 / n2)其中,x1和x2分别是两个样本的均值,s1和s2分别是两个样本的标准差,n1和n2分别是两个样本的容量。
如果样本容量较小,那么应该使用t统计量进行假设检验。
计算t统计量的公式如下:t = (x1 - x2) / sqrt(s1^2 / n1 + s2^2 / n2)在计算了检验统计量之后,需要根据显著性水平(通常为0.05)来确定拒绝域的边界。
拒绝域是指当检验统计量的取值落在这个区域之内时,拒绝零假设,即认为两个样本的均值存在显著差异。
最后,根据计算的检验统计量与拒绝域的比较结果,得出是否拒绝零假设的结论。
如果检验统计量的取值落在拒绝域之内,那么可以拒绝零假设,认为两个样本的均值存在显著差异。
需要注意的是,这种假设检验只能提供统计显著性的结论,而不是实际意义的差异。
所以在进行假设检验之前,需要对样本差异的实际意义进行考量。
总之,双样本均值比较分析假设检验是一种常用的统计方法,可以用于比较两个独立样本的均值是否存在显著差异。
通过计算检验统计量和拒绝域的比较,可以得出是否拒绝零假设的结论。
由两个独立样本计算的两个总体均数的可信区间

一、概述两个总体均数的可信区间是用来衡量两个独立样本的均值之间的差异程度的重要工具。
在许多研究和实验中,我们常常需要对两个总体的均值进行比较,而两个总体均数的可信区间可以帮助我们对这种比较进行量化和解释。
本文将介绍如何根据两个独立样本来计算两个总体均数的可信区间,并探讨其在实际应用中的意义和局限性。
二、概念解释1.总体均数:总体是指研究对象的全体,而总体均数则是对这一全体的均值进行描述的统计量。
总体均数通常用μ表示。
2.可信区间:在统计学中,可信区间是用来估计总体参数(如均数)的区间估计。
它提供了一个区间,使得我们可以以一定的置信水平来推断总体参数的值。
3.独立样本:在统计学中,独立样本是指来自各自总体的样本,在处理过程中彼此之间相互独立。
独立样本通常用于比较两个或多个总体的均值。
三、两个总体均数的可信区间的计算方法要计算两个总体均数的可信区间,我们首先需要计算两个独立样本的均值和标准差,然后结合样本量和置信水平进行计算。
1.计算两个独立样本的均值:分别对两个样本中的观测值求均值,得到样本均值x̄1和x̄2。
2.计算两个独立样本的标准差:分别对两个样本中的观测值求标准差,得到样本标准差s1和s2。
3.计算置信水平对应的Z值:根据所选的置信水平,查找标准正态分布表,找到相应的Z值。
4.计算两个总体均数的可信区间:利用样本均值和标准差,以及Z 值,使用下式计算可信区间:(x̄1 - x̄2) ± Z * √(s1²/n1 + s2²/n2)其中,x̄1和x̄2分别为两个样本的均值,s1和s2分别为两个样本的标准差,n1和n2分别为两个样本的样本量,Z为对应于所选置信水平的Z值。
四、两个总体均数的可信区间的应用两个总体均数的可信区间在许多领域都有着广泛的应用。
比如在医学研究中,我们常常需要比较两种治疗方法的有效性,而两个总体均数的可信区间可以帮助我们对两种治疗方法的效果进行量化和解释。
两组样本均数比较的样本含量计算公式

两组样本均数比较的样本含量计算公式在我们的统计学世界里,有一个很重要的工具,那就是两组样本均数比较的样本含量计算公式。
这可不像听起来那么枯燥无聊哦,其实它就像是我们解决问题的一把神奇钥匙。
想象一下,咱们正在研究一种新的教学方法,想看看它是不是真的能提高学生的数学成绩。
一组学生用传统方法学习,另一组用新方法。
这时候,我们怎么知道要找多少学生来做这个实验,才能得出可靠的结论呢?这就要用到咱们的样本含量计算公式啦。
这个公式看起来可能有点复杂,一堆字母和符号。
但是别担心,咱们慢慢捋一捋。
比如说,这里面有个叫“标准差”的家伙,它其实就是反映数据离散程度的。
如果成绩波动很大,标准差就大;要是大家成绩都差不多,标准差就小。
还有个“检验水准”,简单说就是我们能接受犯错误的概率。
比如说,我们把检验水准设为0.05,那就意味着我们最多能容忍5%的犯错机会。
我之前就遇到过这么个事儿。
学校要比较两个班级的语文平均成绩,看看不同的教学方式有没有效果。
我一开始没太在意样本含量的计算,随便选了一些学生。
结果呢,得出来的结论模棱两可,根本没法说明哪种教学方式更好。
这可把我愁坏了!后来我仔细研究了这个样本含量计算公式,重新规划了样本,才得到了比较准确和有意义的结果。
再说说“功效”这个概念。
它就像是我们的目标,我们希望有多大的把握能发现真正的差异。
比如说,我们希望有 80%的把握能检测出两种教学方法导致的成绩差异,那在计算样本含量的时候就得把这个考虑进去。
而且啊,样本含量的计算还得考虑很多实际情况。
比如研究的成本、时间和可行性。
要是算出来需要几百个样本,可我们没那么多资源,那就得重新调整研究方案。
总之,两组样本均数比较的样本含量计算公式虽然有点复杂,但只要我们用心去理解,结合实际情况灵活运用,就能在研究中少走很多弯路,得到更可靠、更有价值的结论。
就像我们在学习和生活中,遇到难题别害怕,多琢磨琢磨,总能找到解决办法的!希望大家以后再碰到类似的问题,都能轻松应对,用这个神奇的公式打开科学研究的大门,发现更多有趣的知识和真理!。
统计学第四讲两组资料均数比较2

特点:资料成对,每对数据不可拆分。
计算出各对子差值d 的均数d 。当比较组间效果相同时, d 的总体均数 d =0,故可将配对设计资料的假设检验视为样 本均数d 与总体均数 d =0 的比较,所用方法称为配对 t 检验 (paired t-test)方法。 t | d d | | d | , n 1
或50)时,可采用u检验;但只是近似方法。 优点:简单,u界值与自由度无关, u0.05=1.96, u0.01=2.58
u X1 X2 S
X1 X 2
X1 X2 S12 S22 n1 n2
X1 X2
S 2S 2
X1
X2
第四军医大学卫生统计学教研室 2020年3月28日
五、正态性检验与两方差齐性检验
义
第四军医大学卫生统计学教研室 2020年3月28日
假设检验的步骤
1、建立假设与确定检验水准(α)
H0: μ1=μ2 无效假设(null hypothesis) H1: μ1≠μ2 备择假设(alternative hypothesis)
检验水准(level of a test):α=0.05(双侧)
今 F 1.484 F0.05 / 2,6,6 ,P>0.05 ,按α=0.05 水准,不拒绝 H0,两组总体
方差的差别无统计学意义,尚不能认为两组总体方差不等。
若两总体方差不等,即
2 1
2 2
时,
1. 近似 t 检验(separate variance estimation t-test) t'检验
n1
2.6314 1.342 / 12 0.475 12 1
t | d | 0.112 0.817, n 1 12 1 11
成组设计两样本均数的比较.

X1 X 2 (n1 1) s (n2 1) s2 2 1 1 ( ) n1 n2 2 n1 n1
2 1
两样本进行t检验举例
• 两样本标准误 sX1 X 2与H0是否为真无关 • X1 X2 是两个总体均数之差的点估计, 因此当H0: µ1=µ2成立时, X1 X2 在大 多数情况下非常小或较小,故t检验统 计量较小或比较小。 • 反之,当H1:µ1µ2,在大多数情况下 较大或很大,所以 t检验统计量比较大 X1 X2 或很大。
两个独立样本平均水平的比较
• 两个独立样本平均水平的比较可以是两 样本 t检验,也可以两样本秩和检验。考 虑到检验效能的原因,一般采用下列统 计分析策略: • 如果满足每组资料近似呈正态分布(或 大样本)并且方差齐性,则可用两样本 t 检验;
两个独立样本平均水平比较
• 如果满足每组资料近似呈正态分布 (或大样本)但方差不齐,则可用 两样本t’检验; • 否则可以用两样本的Wilcoxon秩和 检验
对于方差不齐的情况
• 如果每组资料服从正态分布,但方差不齐,则可以 用t’检验 • t’检验
t
X1 X 2 X1 X 2 X1 X 2 ห้องสมุดไป่ตู้ 2 2 2 sx x s x s x s1 / n1 s2 2 / n2 1 2
1 2
• 但要根据方差不齐的严重程度调整自由度 (见教 材),其它与t检验相同。
两样本进行t检验举例
• 可以证明:当H0为真时,t检验统计量服 从自由度为n1+n2-2的t分布。故当t检验统 计量出现|t|>t0.05/2,n1+n2-2,则这是一个小 概率事件,一次随机抽样一般不会出现的, 故有理由怀疑H0非真所致,古可以拒绝H0。 • 本例t=3.5872>>临界值t0.05/2,n1+n2-2
统计学两样本均数比较的t检验

处理方式
对于异常值,可以采用删除、替换或用中位数修正等方式进行处理。具体处理方式应根 据实际情况和数据分布特点进行选择,并确保处理后的数据仍然能够反映总体情况。
实验设计和伦理考虑
实验设计
在进行t检验之前,应进行充分的实验设计, 确保实验的合理性和科学性。实验设计应考 虑各种因素对实验结果的影响,并尽量减小 误差和干扰因素。
确定p值:根据t统计量和自由 度,查表或使用统计软件计算 p值。
步骤1
收集数据:分别从两个独立样 本中收集数据,并记录在表格 中。
步骤3
计算t统计量:根据两组样本的 均数和标准差,计算t统计量。
步骤5
结果解读:根据p值判断两组 样本均数之间的差异是否具有 统计学上的显著性。
结果解读
• 结果解读:根据p值的大小来判断两 组样本均数之间的差异是否具有统计 学上的显著性。通常,如果p值小于 0.05,则认为两组样本均数之间存在 显著差异;如果p值大于0.05,则认 为两组样本均数之间无显著差异。
对差值数据进行描述性统计分析, 计算差值的均值和标准差。
计算t统计量
根据差值的均值、标准差以及自 由度,计算t统计量。
收集两个配对样本的数据
确保两个样本具有相同的样本量, 且每个样本中的数值都是配对的。
判断显著性
பைடு நூலகம்根据t分布表或使用统计软件,查 找对应的p值,判断两个配对样本 均数是否存在显著差异。
结果解读
伦理考虑
在实验设计过程中,还应考虑伦理问题。应 尊重受试者的权益和尊严,确保受试者的安 全和隐私。同时,应遵循国际公认的伦理准 则和法律法规,如《赫尔辛基宣言》等。
06 案例分析
两样本均数比较的估算公式

两样本均数比较的估算公式在咱们的数学世界里,两样本均数比较的估算公式就像是一把神奇的钥匙,能帮我们打开很多知识的大门。
咱先来说说啥是两样本均数比较。
比如说,有两个班级,一班的数学平均成绩是 85 分,二班的数学平均成绩是 90 分。
这时候,咱们就想知道,这两个班的成绩差异是偶然的呢,还是真的有明显不同。
这就用到两样本均数比较啦。
那估算公式到底是啥呢?它就像是一个数学小精灵,能告诉我们这两个样本的均数之间有没有显著的差别。
这个公式看起来可能有点复杂,一堆字母和符号,但别害怕,咱们一点点来。
我记得有一次,我在给学生们讲这个知识点的时候,有个特别可爱的小同学,瞪着大眼睛,一脸困惑地问我:“老师,这公式到底有啥用啊?感觉好难哦!”我笑着跟他说:“你想想啊,假如咱们要比较两个城市小学生的身高平均值,通过这个公式就能知道是不是一个城市的孩子普遍比另一个城市的孩子高,这多有趣啊!”咱们来具体看看这个公式。
它里面涉及到样本的大小、均数、标准差等等。
这些东西就像是一块块拼图,拼在一起就能得出咱们想要的答案。
比如说,样本大小决定了我们这个比较的可靠性,样本越大,结果就越可靠。
再说说均数,它就像是一个班级成绩的代表,能让我们大概了解整体的水平。
而标准差呢,能告诉我们数据的离散程度,也就是大家的成绩是不是相差很大。
在实际运用中,咱们得小心一些常见的错误。
可别把数据弄错了,或者忘了公式的使用条件。
这就好比做饭的时候,盐放多了或者火候没掌握好,那这道菜可就不美味啦。
还有啊,这个公式可不只是在数学考试里有用。
比如说,在医学研究中,医生们想比较两种药物的疗效;在市场调查中,想看看不同地区消费者的平均消费金额。
它都能发挥大作用。
总之,两样本均数比较的估算公式虽然有点复杂,但只要咱们耐心琢磨,多做练习,就能把它变成我们的好帮手,让我们在数学的海洋里畅游得更欢快!就像那个可爱的小同学,后来他通过努力,终于掌握了这个公式,那开心的样子,让我也特别有成就感。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
两样本均数的比较
在统计学中,比较两个样本的均数是一种常见的分析方法。
通过比较两个不同样本的均数,我们可以了解它们是否具有显著差异,以及这些差异是否具有统计学意义。
本文将介绍两个样本均数比较的基本原理和常用方法。
一、基本原理
在进行两个样本均数的比较之前,我们首先需要了解一些基本的统计学知识。
均数是一个样本或总体数据的平均值,它可以帮助我们了解数据的集中趋势。
对于一个样本或总体而言,均数是一个重要的描述性统计量。
当我们比较两个样本的均数时,我们关注的是它们之间的差异是否显著。
如果两个样本的均数差异很大,那么我们可以认为它们之间存在显著的差异。
但是,仅凭均数的差异并不能确定这个差异是否具有统计学意义,因为样本的均数差异可能仅仅是由于抽样误差导致的。
因此,在进行两个样本均数的比较时,我们需要进行假设检验。
假设检验是一种用于确定样本均数差异是否具有统计学意义的方法。
通常,我们会提出一个原假设(H0)和一个备择假设(H1)。
原假设通常是指两个样本均数没有显著差异,备择假设则是指两个样本均数存在显著差异。
二、常用方法
常用的两个样本均数比较的方法包括独立样本t检验和配对样本t 检验。
1. 独立样本t检验
独立样本t检验用于比较两个独立的样本均数是否具有显著差异。
在进行独立样本t检验之前,我们需要确保两个样本是独立抽取的,并且满足正态分布和方差齐性的假设。
独立样本t检验的步骤如下:
(1)建立假设:原假设(H0)为两个样本均数没有显著差异,备择假设(H1)为两个样本均数存在显著差异。
(2)计算检验统计量:根据两个样本的均数和方差,计算出独立样本t检验的检验统计量。
(3)确定显著性水平:通常,我们会将显著性水平设定为0.05或0.01。
(4)做出决策:根据检验统计量和显著性水平,做出接受或拒绝原假设的决策。
2. 配对样本t检验
配对样本t检验用于比较同一组样本在不同条件下的均数是否存在显著差异。
在进行配对样本t检验之前,我们需要确保配对样本是从同一总体中抽取的,并且满足正态分布和方差齐性的假设。
配对样本t检验的步骤如下:
(1)建立假设:原假设(H0)为配对样本均数没有显著差异,备择假设(H1)为配对样本均数存在显著差异。
(2)计算检验统计量:根据配对样本的均数差值和方差,计算出配对样本t检验的检验统计量。
(3)确定显著性水平:同样,我们需要设定显著性水平。
(4)做出决策:根据检验统计量和显著性水平,做出接受或拒绝原假设的决策。
三、结论
通过对两个样本均数的比较,我们可以得出结论:两个样本的均数存在显著差异或者不存在显著差异。
这个结论是基于假设检验的结果得出的。
需要注意的是,两个样本均数的比较并不能确定它们之间的因果关系。
均数的差异只能说明它们在某个方面上的差异,但不能推断其中一个样本的变化是否会导致另一个样本的变化。
综上所述,两个样本的均数比较是一种常用的统计学分析方法。
通过假设检验,我们可以确定两个样本均数是否具有显著差异。
独立样本t检验和配对样本t检验是常用的两种方法。
然而,在进行两个样本均数比较之前,我们需要确保样本满足一定的假设前提。
只有在确定这些前提成立的情况下,我们才能正确地进行统计推断,得出准确的结论。