spss操作独立样本T检验模板
SPSS—单样本T检验

一、被调查学生对“云窗的打分值”总体平均值的推断:1、以71个被调查学生为样本做T 检验由表a 可知,71个观测的平均值为71.21,标准差为15,120,均值标准误为1.794。
表b 中,第二列是t 统计量的观测值为0.675,第三列是自由度n-1=70,第四列是t 统计量观测值的双尾概率p 值,第五列是样本均值与检验值的差(1.211),即t 统计量的分子部分,他除以表a 的均值标准误(1.794)后得到t 统计量的观测值0.675,第六列和第七列是总体均值与检验值差的95%的置信区间,为(67.63,74.79)。
对于研究的问题应采用双尾检验,因此比较2α和2p,即比较α和p 。
由于p 大于α(0.05),因此不能拒绝零假设,认为被调查学生对“云窗的打分值”总体平均值没有显著差异。
有95%的把握认为总体均值在 67.63~74.79 分之间。
70分包含在置信区间内,也证实了上述推断。
2、被调查学生对“云窗的打分值”的重抽样自举表cBootstrap 指定采样方法简单箱图样本数1000置信区间度95.0%置信区间类型百分位由表c可知,自举过程执行1000次,随机数种子指定为默认值2000000,采样方法为简单箱图。
中均值的重抽样自举均值与实际样本均值的差为-0.12,1000个均值的标准差为1.82,由此得到的均值95%的置信区间为(67.18,74.46)表e中没有给出双尾检验的概率p值,但是从检验的结果可知有95%的把握认为总体均值在67.184~74.463之间。
70包含在置信区间内。
用更大的样本量再一次说明了被调查学生对“云窗的打分值”总体平均值没有显著差异。
SPSS统计分析教程独立样本T检验doc

SPSS统计分析教程-独立样本T检验.docSPSS统计分析教程:独立样本T检验一、简介独立样本T检验(Independent Sample T-test)是统计分析中常见的一种方法,主要用于比较两组数据的均值是否存在显著差异。
这种检验的前提假设是,两组数据来自正态分布的独立样本。
独立样本T检验在SPSS中的实现相对简单,下面将详细介绍其操作步骤和解读结果。
二、数据准备在进行独立样本T检验之前,需要准备好数据。
数据通常存储在Excel或SPSS数据文件中。
为了方便起见,我们将使用SPSS数据文件进行说明。
三、操作步骤1.打开SPSS软件,点击“分析”(Analyze)菜单,然后选择“比较均值”(Compare Means)中的“独立样本T检验”(Independent Sample T-test)。
2.在弹出的对话框中,将左侧的“组别”(Grouped By)字段设置为一组变量,如“性别”(Gender),将右侧的“组1”(Group 1)和“组2”(Group 2)字段设置为另一组变量,如“年龄”(Age)。
3.点击“确定”(OK)按钮开始进行独立样本T检验。
四、结果解读1.假设检验(Hypothesis Test):在结果中,可以看到假设检验的结果。
如果p值小于显著性水平(通常为0.05),则拒绝原假设(即两组数据的均值无显著差异),认为两组数据的均值存在显著差异。
反之,如果p值大于显著性水平,则接受原假设,认为两组数据的均值无显著差异。
2.均值(Mean):在结果中,可以看到每组数据的均值。
如果两组数据的均值存在显著差异,则可以通过均值的大小来判断哪组数据更好或更优。
3.标准差(Standard Deviation):在结果中,还可以看到每组数据的标准差。
标准差反映了数据分布的离散程度,标准差越大,说明数据分布越不集中。
4.t统计量(t-statistic):t统计量是用来衡量两组数据之间差异大小的一个指标。
t检验的SPSS过程

教育学院 田青
t检验的SPSS过程 单样本t检验——(例5-1) 两独立样本t检验——(例5-2) 两相关相关的t检验——(例5-3)
2020年3月23日5时16分
一、单样本t检验
某教师对其所在学校的大一新生进行了心理 健康水平普查。从中随机抽取了40名学生的 测验得分如下。已知该校历届大一新生该项 心理测验的平均分是28分。试问:该40名新 生的平均分与该校大一新生的平均分有无显 著差异?——数据见例5-1数据
1.操作步骤
2.结果输出
班级2 88 65 68 87 56 78 83 69 70 90 75 79
1.数据输入
2.操作步骤
2.操作步骤
பைடு நூலகம்
3. 结果输出
三、两相关样本的t检验
例5-3:
某一小班教学实验班的18名学生接受了一项数 学教学实验,即接受新的学习方法的训练。在 训练前和训练后,均使用标准化的测试试卷测 试了他们的数学成绩。(结果见SPSS数据例53)。试问该学习方法训练效果是否显著?
单样本t检验——操作步骤1
操作步骤
结果输出
二、两独立样本t检验
例5-2:分布从两个班级随机抽取12名学生,分析他们某 一项心理能力测验分数的平均数是否存在显著性差异。 测验分数如下表。
表5-1 部分学生某心理能力测验分数
班级1 85 67 83 79 92 90 74 79 81 63 70 69
spss独立样本T检验

例题
比较两批电子器材的电阻,随机抽取的样本测量电阻如题表2所示,试比较两批电子器材的电阻是否相同?(提示:需考虑方差齐性问题)
分析步骤:
单击工具栏“分析”——>单击“比较均值”——>单击“单因素ANOVA检验”——>因变量列表置为电阻——>因子置为类别——>选项——>选中方差齐性检验
图1 单因素ANOVA检验
图2 统计
单击工具栏“分析”——>单击“比较均值”——>单击“独立样本T检验”——>检验变量置为电阻——>单击定义组——>填入A批、B批——>单击“确定”
图3 独立样本T检验结果展示:
表4:独立样本检验
结果分析:
假设A,B两批电阻相互独立且均服从正态分布。
H0:u1-u2=0,两批电阻器材的电阻相同
H1:u1-u2≠0,两批电阻器材的电阻不相同
1、查看表4莱文方差等同性检验(levene),假定等方差(显著性为0.435>0.05,代表方差是齐性的),我们看第一行数据。
t检验结果显示,t=1.648,v=12,P=0.125>0.05,按照检验水准,接受H0,拒绝H1,故两批电阻器材的电阻相同。
2、查看表4莱文方差等同性检验(levene),不假定等方差,我们看第二行数据。
t’检验结果显示,t=1.648,v=10.671,P=0.129>0.05,按照检验水准,接受H0,拒绝H1,故两批电阻器材的电阻相同。
spss操作独立样本T检验模板
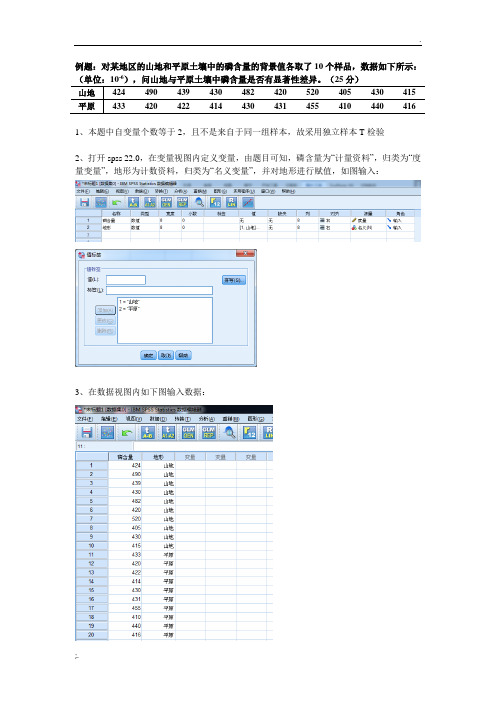
例题:对某地区的山地和平原土壤中的磷含量的背景值各取了10个样品,数据如下所示:-6山地424 490 439 430 482 420 520 405 430 415 平原433 420 422 414 430 431 455 410 440 4161、本题中自变量个数等于2,且不是来自于同一组样本,故采用独立样本T检验2、打开spss 22.0,在变量视图内定义变量,由题目可知,磷含量为“计量资料”,归类为“度量变量”,地形为计数资料,归类为“名义变量”,并对地形进行赋值,如图输入:3、在数据视图内如下图输入数据:4、独立样本T检验进行的假设:(1)数据必须为连续性数据;(2)方差齐性(可偏不齐,即σ12/σ22<3);(3)每组数据均服从正态分布5、进行验证:(1)由题目可以看出,数据为连续型数据,满足;(2)此检验可于结果中查看;(3)首先,新建spss视图,重新输入变量进行探索队列,如下图所示:将“山地”“平原”选入因变量列表,并于“绘图(T)”中勾选“带检验的正态图”,操作步骤如下图所示:根据正态性检验表的“K-S检验”结果,由于样本内数据数量<30,故看Shapiro-Wilk结果,由于两者的sig均大于0.05,故满足正态分布正态性检验Kolmogorov-Smirnov(K)a Shapiro-Wilk统计df 显著性统计df 显著性山地.268 10 .041 .856 10 .069平原.146 10 .200*.945 10 .608*. 这是真正显著性的下限。
a. Lilliefors 显著性校正6、进行独立样本T检验:(1)依次点击“分析”-“比较平均值”-“独立样本T检验”,调出独立样本T检验对话框:(2)将“磷含量”选入检验变量(T),将“地形”选入分组变量,然后定义组,于主页面中点击“确定”,输出结果:组统计地形数字平均值(E) 标准偏差标准误差平均值磷含量山地10 445.50 38.106 12.050 平原10 427.10 13.609 4.304独立样本检验列文方差相等性检验平均值相等性的t 检验F 显著性t自由度显著性(双尾)平均差标准误差差值差值的95%置信区间下限上限磷含量已假设方差齐性9.559 .006 1.438 18 .168 18.400 12.796 -8.482 45.282未假设方差齐性1.438 11.259 .178 18.400 12.796 -9.684 46.484根据独立样本检验表的方差方程的Levene检验,F统计量的sig值0.006<0.05,否认方差相等的假设,认为方差不齐性,故参考第二行的t检验结果;第二行t检验的双侧sig=0.178>0.05,即可认为在0.05的显著性水平上,山地与平原土壤中磷含量是否没有有显著性差异。
两独立样本T检验---SPSS操作详解

两独立样本T检验-SPSS操作详解
为了解某一新药降血压的效果,将28名高血压患者随机分为实验组和对照组,实验组采用新药,对照组采用常规药,测得治疗前后的血压变化,问新药是否优于常规药?
1 打开SPSS软件,定义变量。
变量1设置:name-group , decimals-0 , label-分组, value-(1=新药,2=常规药) 变量2设置:name-value , decimals-0 , label-血压下降值
2 输入数据---血压差=用药前血压-用药后血压
3 单击菜单栏analyze/compare means/independent-samples t test
4 将血压下降值调入test variables下矩形框
5 将分组(group)调入grouping variable 下矩形框
6单击define groups…定义分组group1为1 定义group2为2 单击continue
7 options选项默认
8 bootstrap选项默认
9 单击OK 输出结果
10 结果界面
11 结果解释
表1表示两独立样本t检验基本统计量-group statistics
表2表示两独立样本t检验结果,方差方程的levene检验(Levene’s Test for Equality of Variances 方差齐性检验)F=3.115,P=0.93,认为两样本来自的总体方差齐。
T检验中t=3.18,P=0.005。
按α=0.05水准拒绝H0
,差异有统计学意义。
可认为新药组的降压效果优于常规药。
2017/06/06于深圳
随时交流:ammomeng@。
SPSS-t检验

数据输入
1)启动SPSS,进入定义变量工作表,分别命名 两变量:组别、鱼产量。其中组别1表示A料,组 别2表示B料。
2)进入数据视图工作表,输入数据
统计பைடு நூலகம்析
Analyze---compare mean----indendent samples T test
Test variable(输入):产鱼量
2、选择检验方法和计算检验统计量 因为总体标准差σ未知,所以采用t检验。 Analyze →Compare Means→One-Sample T Test出现如下对话框:
•把x移入到Test Variable(s) 的变量列表; •在Test Value后输入需要 比较的总体均数20; •OK
3、根据检验统计量的结果做出统计推断 基本统计量信息:
T检验
(一)单个总体均数的t检验 (二)独立样本成组t检验 (三)成对样本t检验
(一)单个总体均数的t检验
计算公式
样本平均数与总体平均数差异显著性检验
例:成虾的平均体重为21克,在配合饲料中添加 0.5%的酵母培养物饲养成虾时,随机抽取16只对 虾,体重为20.1、21.6、22.2、23.1、20.7、19.9、 21.3、21.4、22.6、22.3、20.9、21.7、22.8、 21.7、21.3、20.7。试检验添加添加0.5%的酵母 培养物是否提高了成虾体重。
从结果中可以看出,统计量t=3.056,P=0.012<α=0.05,因此拒 绝H0,接收H1,即用该方法测量所得结果与标准浓度值有所不 同。认为该方法测量结果所对应总体均数μ与标准浓度μ0间的差 异有统计学意义。
(二)独立样本成组t检验
独立样本:又称非配对样本或成组样本。是指一组数据与另一 组数据没有任何关系,也就是说,两样本资料是相互独立的。 两组的样本容量尽可能相同,可以提高检验的精确度。其均 数差异显著性的t检验,又分为两总体方差相等(方差齐性)和 方差不等两种检验方法。
spss均值检验(均数分析单样本t检验独立样本t检验)

在统计学中,我们往往从样本的特性推知随机变量总体的特性。
但由于总体中个体之间存在差异,样本的统计量和总体的参数之间往往会有误差。
因此,均值不相等的样本未必来自不同分布的总体,而均值相等的样本未必来自有相同分布的总体。
也就是说,如何从样本均值的差异推知总体的差异,这就是均值比较的内容。
SPSS提供了均值比较过程,在主菜单栏单击“Analyze”菜单下的“Compare Means”项,该项下有5个过程,如图4-1。
平均数比较Means过程用于统计分组变量的的基本统计量。
这些基本统计量包括:均值(Mean)、标准差(Standard Deviation)、观察量数目(Number of Cases)、方差(Variance)。
Means过程还可以列出方差表和线性检验结果。
[例子]调查了棉铃虫百株卵量在暴雨前后的数量变化,统计暴雨前和暴雨后的统计量,其数据如下:暴雨前 110 115 133 133 128 108 110 110 140 104 160 120 120暴雨后 90 116 101 131 110 88 92 104 126 86 114 88 112该数据保存在“DATA4-1.SAV”文件中。
1)准备分析数据在数据编辑窗口输入分析的数据,如图4-2所示。
或者打开需要分析的数据文件“DATA4-1.SAV”。
图4-2 数据窗口2)启动分析过程在SPSS主菜单中依次选择“Analyze→Compare Means→Means”。
出现对话框如图4-3。
图4-3 Means设置窗口3)设置分析变量从左边的变量列表中选中“百株卵量”变量后,点击变量选择右拉按钮,该变量就进入到因子变量列表“Dependent List:”框里,用户可以从左边变量列表里选择一个或多个变量进行统计。
从左边的变量列表中选中“调查时候”变量,点击“Independent List”框左边的右拉按钮,该变量就进入分组变量“IndependentList”框里,用户可以从左边变量列表里选择一个或多个分组变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
例题:对某地区的山地和平原土壤中的磷含量的背景值各取了10个样品,数据如下所示:(单位:10-6),问山地与平原土壤中磷含量是否有显着性差异。
(25分)
1、本题中自变量个数等于2,且不是来自于同一组样本,故采用独立样本T 检验
2、打开spss 22.0,在变量视图内定义变量,由题目可知,磷含量为“计量资料”,归类为“度量变量”,地形为计数资料,归类为“名义变量”,并对地形进行赋值,如图输入:
3、在数据视图内如下图输入数据:
4、独立样本T检验进行的假设:
(1)数据必须为连续性数据;
(2)方差齐性(可偏不齐,即σ12/σ22<3);
(3)每组数据均服从正态分布
5、进行验证:
(1)由题目可以看出,数据为连续型数据,满足;
(2)此检验可于结果中查看;
(3)首先,新建spss视图,重新输入变量进行探索队列,如下图所示:
将“山地”“平原”选入因变量列表,并于“绘图(T)”中勾选“带检验的正态图”,操作步骤如下图所示:
根据正态性检验表的“K-S检验”结果,由于样本内数据数量<30,故看Shapiro-Wilk结果,由于两者的sig均大于0.05,故满足正态分布
6、进行独立样本T检验:
(1)依次点击“分析”-“比较平均值”-“独立样本T检验”,调出独立样本T检验对话框:
(2)将“磷含量”选入检验变量(T),将“地形”选入分组变量,然后定义组,于主页面中点击“确定”,输出结果:
7、结果分析:
组统计
地形数字平均值(E) 标准偏差标准误差平均值
磷含量山地10 445.50 38.106 12.050
平原10 427.10 13.609 4.304。