实验六主成分分析报告
主成分分析报告

主成分分析报告第一点:主成分分析的定义与重要性主成分分析(Principal Component Analysis,PCA)是一种统计方法,它通过正交变换将一组可能相关的变量转换为一组线性不相关的变量,这组变量称为主成分。
这种方法在多变量数据分析中至关重要,尤其是在数据的降维和可视化方面。
在实际应用中,数据往往包含多个变量,这些变量可能存在一定的相关性。
这样的数据集很难直接进行分析和理解。
主成分分析通过提取数据中的主要特征,将原始的多维数据转化为少数几个互相独立的主成分,使得我们能够更加清晰地看到数据背后的结构和模式。
主成分分析的重要性体现在以下几个方面:1.降维:在数据集中存在大量变量时,通过PCA可以减少数据的维度,简化模型的复杂性,从而降低计算成本,并提高模型的预测速度。
2.去除相关性:PCA能够帮助我们识别和去除变量间的线性相关性,使得我们分析的是更加纯净的独立信息。
3.数据可视化:通过将多维数据映射到二维或三维空间中,PCA使得数据的可视化成为可能,有助于我们直观地理解数据的结构和模式。
4.特征提取:在机器学习中,PCA可以作为一种特征提取工具,提高模型的性能和泛化能力。
第二点:主成分分析的应用案例主成分分析在各个领域都有广泛的应用,下面列举几个典型的案例:1.图像处理:在图像处理领域,PCA被用于图像压缩和特征提取。
通过将图像转换到主成分空间,可以大幅度减少数据的存储空间,同时保留图像的主要信息。
2.金融市场分析:在金融领域,PCA可以用来分析股票或证券的价格动向,通过识别影响市场变化的主要因素,帮助投资者做出更明智的投资决策。
3.基因数据分析:在生物信息学领域,PCA被用于基因表达数据的分析。
通过识别和解释基因间的相关性,PCA有助于揭示生物过程中的关键基因和分子机制。
4.客户细分:在市场营销中,PCA可以用来分析客户的购买行为和偏好,通过识别不同客户群的主要特征,企业可以更有效地制定市场策略和个性化推荐。
主成分分析实验报告

项目名称实验4—主成分分析所属课程名称多元统计分析(英)项目类型综合性实验_____________ 实验(实训)日期2012年4 月15日二、实验(实训)容:【项目容】主成分分析。
【方案设计】题目:由原始数据求主成分。
【实验(实训)过程】(步骤、记录、数据、程序等)附后【结论】(结果、分析)附后三、指导教师评语及成绩:评语:成绩:指导教师签名:批阅日期:实验报告4主成分分析(综合性实验)(Prin cipal comp onent an alysis)实验原理:主成分分析利用指标之间的相关性,将多个指标转化为少数几个综合指标,从而达到降维和数据结构简化的目的。
这些综合指标反映了原始指标的绝大部分信息,通常表示为原始指标的某种线性组合,且综合指标间不相关。
利用矩阵代数的知识可求解主成分实验题目:下表中给出了不同国家及地区的男子径赛记录:(t8a6)Country 100m 200m 400m 800m 1500m 5000m 10,000m Marathon(s) (s) (s) (min) (min) (min) (min) (mins) Argentina 10.39 20.81 46.84 1.81 3.7 14.04 29.36 137.72 Australia 10.31 20.06 44.84 1.74 3.57 13.28 27.66 128.3 Austria 10.44 20.81 46.82 1.79 3.6 13.26 27.72 135.9 Belgium 10.34 20.68 45.04 1.73 3.6 13.22 27.45 129.95 Bermuda 10.28 20.58 45.91 1.8 3.75 14.68 30.55 146.62 Brazil 10.22 20.43 45.21 1.73 3.66 13.62 28.62 133.13 Burma 10.64 21.52 48.3 1.8 3.85 14.45 30.28 139.95 Canada 10.17 20.22 45.68 1.76 3.63 13.55 28.09 130.15 Chile 10.34 20.8 46.2 1.79 3.71 13.61 29.3 134.03 China 10.51 21.04 47.3 1.81 3.73 13.9 29.13 133.53 Columbia 10.43 21.05 46.1 1.82 3.74 13.49 27.88 131.35 Cook Islands 12.18 23.2 52.94 2.02 4.24 16.7 35.38 164.7 Costa Rica 10.94 21.9 48.66 1.87 3.84 14.03 28.81 136.58 Czechoslovakia 10.35 20.65 45.64 1.76 3.58 13.42 28.19 134.32 Denmark 10.56 20.52 45.89 1.78 3.61 13.5 28.11 130.78 Dominican Republic 10.14 20.65 46.8 1.82 3.82 14.91 31.45 154.12 Finland 10.43 20.69 45.49 1.74 3.61 13.27 27.52 130.87 France 10.11 20.38 45.28 1.73 3.57 13.34 27.97 132.3 German (D.R.) 10.12 20.33 44.87 1.73 3.56 13.17 27.42 129.92German (F.R.) 10.16 20.37 44.5 1.73 3.53 13.21 27.61 132.23 Great Brit.& N. Ireland 10.11 20.21 44.93 1.7 3.51 13.01 27.51 129.13Greece 10.22 20.71 46.56 1.78 3.64 14.59 28.45 134.6 Guatemala 10.98 21.82 48.4 1.89 3.8 14.16 30.11 139.33 Hungary 10.26 20.62 46.02 1.77 3.62 13.49 28.44 132.58 India 10.6 21.42 45.73 1.76 3.73 13.77 28.81 131.98 Indonesia 10.59 21.49 47.8 1.84 3.92 14.73 30.79 148.83 Ireland 10.61 20.96 46.3 1.79 3.56 13.32 27.81 132.35 Israel 10.71 21 47.8 1.77 3.72 13.66 28.93 137.55 Italy 10.01 19.72 45.26 1.73 3.6 13.23 27.52 131.08 Japan 10.34 20.81 45.86 1.79 3.64 13.41 27.72 128.63 Kenya 10.46 20.66 44.92 1.73 3.55 13.1 27.38 129.75 Korea 10.34 20.89 46.9 1.79 3.77 13.96 29.23 136.25 D.P.R Korea 10.91 21.94 47.3 1.85 3.77 14.13 29.67 130.87 Luxembourg 10.35 20.77 47.4 1.82 3.67 13.64 29.08 141.27 Malaysia 10.4 20.92 46.3 1.82 3.8 14.64 31.01 154.1 Mauritius 11.19 22.45 47.7 1.88 3.83 15.06 31.77 152.23 Mexico 10.42 21.3 46.1 1.8 3.65 13.46 27.95 129.2 Netherlands 10.52 20.95 45.1 1.74 3.62 13.36 27.61 129.02 New Zealand 10.51 20.88 46.1 1.74 3.54 13.21 27.7 128.98 Norway 10.55 21.16 46.71 1.76 3.62 13.34 27.69 131.48 Papua New Guinea 10.96 21.78 47.9 1.9 4.01 14.72 31.36 148.22 Philippines 10.78 21.64 46.24 1.81 3.83 14.74 30.64 145.27 Poland 10.16 20.24 45.36 1.76 3.6 13.29 27.89 131.58 Portugal 10.53 21.17 46.7 1.79 3.62 13.13 27.38 128.65 Rumania 10.41 20.98 45.87 1.76 3.64 13.25 27.67 132.5 Singapore 10.38 21.28 47.4 1.88 3.89 15.11 31.32 157.77 Spain 10.42 20.77 45.98 1.76 3.55 13.31 27.73 131.57 Sweden 10.25 20.61 45.63 1.77 3.61 13.29 27.94 130.63 Switzerland 10.37 20.46 45.78 1.78 3.55 13.22 27.91 131.2 Taipei 10.59 21.29 46.8 1.79 3.77 14.07 30.07 139.27Thailand 10.39 21.09 47.91 1.83 3.84 15.23 32.56 149.9 Turkey 10.71 21.43 47.6 1.79 3.67 13.56 28.58 131.5 USA 9.93 19.75 43.86 1.73 3.53 13.2 27.43 128.22 USSR10.07 20 44.6 1.75 3.59 13.2 27.53 130.55 Western Samoa10.8221.86492.024.2416.2834.71161.83(数据来源:1984年洛杉机奥运会IAAF/AFT 径赛与田赛统计手册) 实验要求: (1) 试用Princomp 过程求主成分;并对结果进行解释; (2) 试用方差累积贡献率和Scree 图确定主成分的个数; (3) 计算各国第一主成分的得分并排名; (4) 试对结果进行解。
应用多元统计分析实验报告之主成分分析
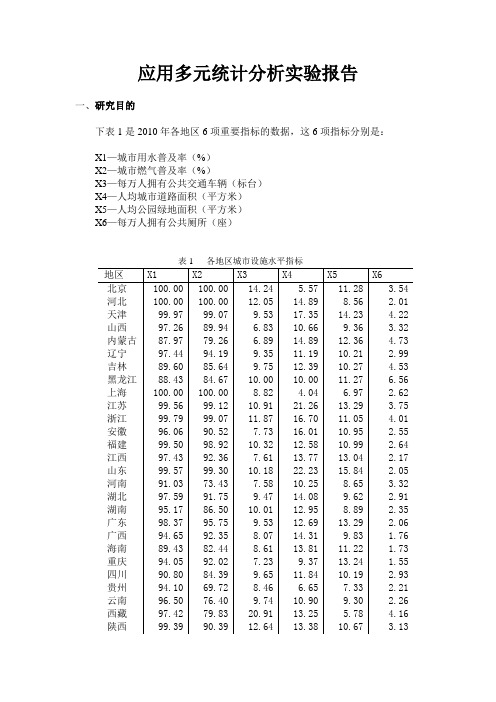
应用多元统计分析实验报告一、研究目的下表1是2010年各地区6项重要指标的数据,这6项指标分别是:X1—城市用水普及率(%)X2—城市燃气普及率(%)X3—每万人拥有公共交通车辆(标台)X4—人均城市道路面积(平方米)X5—人均公园绿地面积(平方米)X6—每万人拥有公共厕所(座)表1 各地区城市设施水平指标本次实验的研究目的是根据这些指标用主成分分析法对各地区城市设施水平进行综合评价和排序,得出结论并提出建议。
二、研究过程从标准化数据出发,首先计算这些指标的主成分,然后通过主成分的大小进行排序。
1.利用SPSS进行因子分析表2和表3分别是特征根(方差贡献率)和因子载荷阵的信息。
表3 因子载荷阵2.利用因子分析结果进行主成分分析 ⑴.表4是特征向量的信息表4 特征向量矩阵 z1 z2 z3 z4 z5 z6 x1 0.52 0.35 (0.31) (0.00) 0.08 0.70 x2 0.58 0.09 (0.19) 0.45 (0.37) (0.53) x3 0.17 0.67 0.26 (0.36) 0.41 (0.39) x4 0.43 (0.32) 0.32 (0.66) (0.41) 0.03 x5 0.41 (0.51) 0.25 0.21 0.68 (0.01) x6 (0.01) 0.23 0.79 0.43 (0.24) 0.28⑵.利用主成分得分进行综合评价时,从特征向量可以写出所有6个主成分的具体形式:Y1=0.52X1+0.68X2+0.17X3+0.43X4+0.41X5-0.01X6Y2=0.35X1+0.09X2+0.67X3-0.32X4-0.51X5+0.23X6 Y3=-0.31X1-0.19X2+0.26X3+0.32X4+0.25X5+0.79X6 Y4=0.00X1+0.45X2-0.36X3-0.66X4+0.21X5+0.43X6 Y5=0.08X1-0.37X2+0.41X3-0.41X4+0.68X5-0.24X6 Y6=0.70X1-0.53X2-0.39X3+0.03X4-0.01X5+0.28X6⑶.以特征根为权,对6个主成分进行加权综合,得出各地区的综合得分及排序,具体数据见表5.综合得分的计算公式是6161Y Y Y ii ∑∑+⋯+=λλλλ三、结果说明从表5可以看出,北京、天津。
主成分分析报告

主成分分析报告在当今的数据驱动的世界中,我们经常面临着处理大量复杂数据的挑战。
如何从这些海量的数据中提取有价值的信息,简化数据结构,发现潜在的模式和趋势,成为了数据分析领域的重要课题。
主成分分析(Principal Component Analysis,简称 PCA)作为一种强大的数据分析工具,为我们提供了一种有效的解决方案。
主成分分析是一种多元统计分析方法,其主要目的是通过对原始变量的线性组合,构建一组新的不相关的综合变量,即主成分。
这些主成分能够尽可能多地保留原始数据的信息,同时实现数据的降维。
让我们先来了解一下主成分分析的基本原理。
假设我们有一组观测数据,每个观测包含多个变量。
主成分分析的核心思想是找到一组新的坐标轴,使得数据在这些坐标轴上的投影具有最大的方差。
第一个主成分就是数据在方差最大方向上的投影,第二个主成分则是在与第一个主成分正交的方向上,具有次大方差的投影,以此类推。
为什么要进行主成分分析呢?首先,它能够帮助我们简化数据结构。
当我们面对众多相关的变量时,通过主成分分析可以将其归结为少数几个综合变量,从而减少数据的复杂性,便于后续的分析和处理。
其次,主成分分析可以去除数据中的噪声和冗余信息,突出数据的主要特征,有助于发现数据中的隐藏模式和关系。
此外,它还可以用于数据压缩和可视化,使得我们能够更直观地理解数据。
在实际应用中,主成分分析有着广泛的用途。
在图像处理领域,它可以用于图像压缩和特征提取,减少图像数据的存储空间,同时保留图像的主要特征。
在金融领域,主成分分析可以用于构建投资组合,通过对多个金融资产的分析,找出主要的影响因素,从而优化投资组合。
在生物学研究中,主成分分析可以用于分析基因表达数据,发现不同样本之间的差异和相似性。
接下来,我们来看看如何进行主成分分析。
首先,需要对原始数据进行标准化处理,以消除量纲的影响。
然后,计算数据的协方差矩阵或相关矩阵。
接着,通过求解特征值和特征向量,确定主成分的方向和权重。
主成份分析报告(包含sas程序)
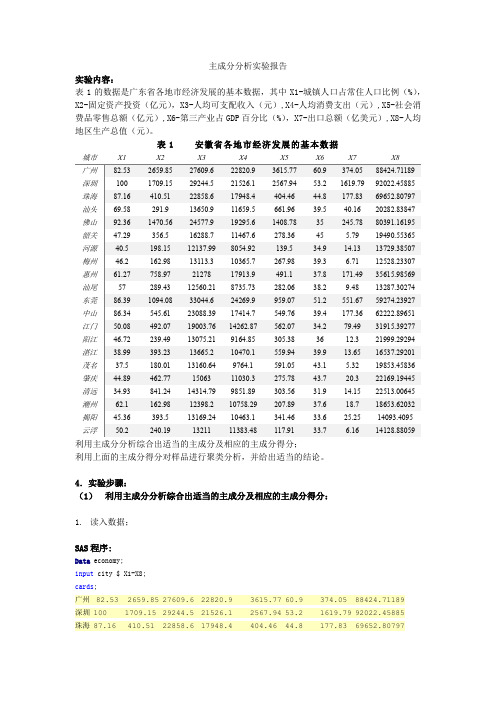
主成分分析实验报告实验内容:表1的数据是广东省各地市经济发展的基本数据,其中X1-城镇人口占常住人口比例(%),X2-固定资产投资(亿元),X3-人均可支配收入(元),X4-人均消费支出(元),X5-社会消费品零售总额(亿元),X6-第三产业占GDP百分比(%),X7-出口总额(亿美元),X8-人均地区生产总值(元)。
表1 安徽省各地市经济发展的基本数据城市X1X2X3X4X5X6X7X8广州82.532659.8527609.622820.93615.7760.9374.0588424.71189深圳1001709.1529244.521526.12567.9453.21619.7992022.45885珠海87.16410.5122858.617948.4404.4644.8177.8369652.80797汕头69.58291.913650.911659.5661.9639.540.1620282.83847佛山92.361470.5624577.919295.61408.7835245.7880391.16195韶关47.29356.516288.711467.6278.3645 5.7919490.55365河源40.5198.1512137.998054.92139.534.914.1313729.38507梅州46.2162.9813113.310365.7267.9839.3 6.7112528.23307惠州61.27758.972127817913.9491.137.8171.4935615.98569汕尾57289.4312560.218735.73282.0638.29.4813287.30274东莞86.391094.0833044.624269.9959.0751.2551.6759274.23927中山86.34545.6123088.3917414.7549.7639.4177.3662222.89651江门50.08492.0719003.7614262.87562.0734.279.4931915.39277阳江46.72239.4913075.219164.85305.383612.321999.29294湛江38.99393.2313665.210470.1559.9439.913.6516537.29201茂名37.5180.0113160.649764.1591.0543.1 5.3219853.45836肇庆44.89462.771506311030.3275.7843.720.322169.19445清远34.93841.2414314.799851.89303.5631.914.1522513.00645潮州62.1162.9812398.210758.29207.8937.618.718653.62032揭阳45.36393.513169.2410463.1341.4633.625.2514093.4095云浮50.2240.191321111383.48117.9133.7 6.1614128.88059利用主成分分析综合出适当的主成分及相应的主成分得分;利用上面的主成分得分对样品进行聚类分析,并给出适当的结论。
主成分分析实验报告

一、实验目的本次实验旨在通过主成分分析(PCA)方法,对给定的数据集进行降维处理,从而简化数据结构,提高数据可解释性,并分析主成分对原始数据的代表性。
二、实验背景在许多实际问题中,数据集往往包含大量的变量,这些变量之间可能存在高度相关性,导致数据分析困难。
主成分分析(PCA)是一种常用的降维技术,通过提取原始数据中的主要特征,将数据投影到低维空间,从而简化数据结构。
三、实验数据本次实验采用的数据集为某电商平台用户购买行为的调查数据,包含用户年龄、性别、收入、职业、购买商品种类、购买次数等10个变量。
四、实验步骤1. 数据预处理首先,对数据进行标准化处理,消除不同变量之间的量纲影响。
然后,进行缺失值处理,删除含有缺失值的样本。
2. 计算协方差矩阵计算标准化后的数据集的协方差矩阵,以了解变量之间的相关性。
3. 计算特征值和特征向量求解协方差矩阵的特征值和特征向量,特征值表示对应特征向量的方差,特征向量表示数据在对应特征方向上的分布。
4. 选择主成分根据特征值的大小,选择前几个特征值对应特征向量作为主成分,通常选择特征值大于1的主成分。
5. 构建主成分空间将选定的主成分进行线性组合,构建主成分空间。
6. 降维与可视化将原始数据投影到主成分空间,得到降维后的数据,并进行可视化分析。
五、实验结果与分析1. 主成分分析结果根据特征值大小,选取前三个主成分,其累计贡献率达到85%,说明这三个主成分能够较好地反映原始数据的信息。
2. 主成分空间可视化将原始数据投影到主成分空间,绘制散点图,可以看出用户在主成分空间中的分布情况。
3. 主成分解释根据主成分的系数,可以解释主成分所代表的原始数据特征。
例如,第一个主成分可能主要反映了用户的购买次数和购买商品种类,第二个主成分可能反映了用户的年龄和性别,第三个主成分可能反映了用户的收入和职业。
六、实验结论通过本次实验,我们成功运用主成分分析(PCA)方法对数据进行了降维处理,提高了数据可解释性,并揭示了数据在主成分空间中的分布规律。
成分检验分析实验报告
成分检验分析实验报告实验目的:进行成分检验分析,确定样品中的成分组成。
实验原理:成分检验分析主要通过物化性质分析和化学反应分析进行。
物化性质分析主要包括密度测定、溶解性测试、熔点测定等;化学反应分析主要包括酸碱反应、沉淀反应、氧化还原反应等。
实验步骤:1. 密度测定:将一定量的样品称取入一个瓶中,用天平称量,然后将瓶子放入容器中放置,测量其质量,并记录下来。
然后倒入一定量的水,并再次记录下质量。
根据两次测量结果计算密度。
2. 溶解性测试:取一小部分样品,放入试管中,加入适量的溶剂,如水、乙醇等,搅拌溶解至饱和后观察是否完全溶解,记录下结果。
3. 熔点测定:将一小部分样品取出,放入熔点仪中,加热至样品完全熔化时记录下温度。
4. 酸碱反应:取一小部分样品,加入酸性溶液(如盐酸、硫酸等),观察是否发生气体生成、沉淀生成等反应,记录下结果。
5. 沉淀反应:取一小部分样品,加入沉淀试剂(如硫酸铜、氯化钡等),观察是否生成沉淀,并记录下结果。
6. 氧化还原反应:将一小部分样品与酸性溶液混合,加入适量的还原剂(如亚硫酸钠、氢氧化钠等),观察是否发生颜色的变化等反应,记录下结果。
实验结果与分析:1. 密度测定结果:样品的质量为X克,质量测量的水量为Y克,根据公式计算得到样品的密度为X/Y。
2. 溶解性测试结果:样品完全溶解于水/乙醇等溶剂中,表明样品是可以溶解于水/乙醇等溶剂的。
3. 熔点测定结果:样品的熔点为X,与文献值进行对比,如果两者一致,则表明样品的纯度较高;如果不一致,则可能存在杂质。
4. 酸碱反应结果:样品与酸性溶液发生反应生成了气体/沉淀等,根据反应类型可以初步判断样品中可能含有酸性物质/碱性物质。
5. 沉淀反应结果:样品与沉淀试剂反应生成了沉淀,根据沉淀的颜色、形状等可以进一步判断样品中可能含有的物质。
6. 氧化还原反应结果:样品与酸性溶液和还原剂发生反应,观察到颜色的变化,可以根据这个颜色变化进一步判断样品中可能含有的物质。
主成分分析报告
主成分分析报告1. 简介主成分分析(Principal Component Analysis, PCA)是一种常用的数据降维技术,用于将高维数据集映射到低维子空间。
主成分分析主要通过计算数据集中的主成分,来捕捉数据中的主要变化方向和模式。
本报告将介绍主成分分析的原理、应用、算法实现以及使用注意事项。
2. 主成分分析原理主成分分析旨在将高维数据投影到低维空间,并保留尽可能多的有用信息。
其基本思想是通过线性变换,将原始数据映射到新的坐标系中,其中新坐标系的轴是原始数据的主成分方向。
主成分分析的步骤如下:1.计算原始数据的协方差矩阵;2.对协方差矩阵进行特征值分解,得到特征向量和特征值;3.选择最大的k个特征值对应的特征向量,构成变换矩阵;4.将原始数据通过变换矩阵进行映射,得到降维后的数据。
3. 主成分分析的应用主成分分析在数据处理和分析中有很多应用,其中包括:1.数据降维:主成分分析可以将高维数据集投影到低维空间,从而减少数据的维度。
这对于处理大规模数据、可视化和提高计算效率都非常有用。
2.数据可视化:通过将高维数据映射到二维或三维空间,可以更直观地展示数据的结构和模式。
3.噪声过滤:主成分分析可以过滤掉数据中的噪声,保留主要的信号。
4.特征提取:通过提取数据的主成分,可以捕捉到数据的主要变化模式,便于后续分析。
4. 主成分分析算法实现以下是使用Python进行主成分分析的示例代码:import numpy as npfrom sklearn.decomposition import PCA# 创建一个样本矩阵X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 创建PCA对象并指定主成分的数量pca = PCA(n_components=2)# 执行主成分分析X_pca = pca.fit_transform(X)# 输出降维后的数据print(X_pca)在上述代码中,首先创建了一个样本矩阵X,然后创建了一个PCA对象,并指定要保留的主成分数量为2。
主成分分析实验报告剖析
一、引言主成分分析(PCA)是一种常用的数据降维方法,通过对原始数据进行线性变换,将高维数据投影到低维空间,从而简化数据结构,提高计算效率。
本文通过对主成分分析实验的剖析,详细介绍了PCA的基本原理、实验步骤以及在实际应用中的注意事项。
二、实验背景随着数据量的不断增长,高维数据在各个领域变得越来越普遍。
高维数据不仅增加了计算难度,还可能导致信息过载,影响模型的性能。
因此,数据降维成为数据分析和机器学习中的关键步骤。
PCA作为一种有效的降维方法,在众多领域得到了广泛应用。
三、实验目的1. 理解主成分分析的基本原理;2. 掌握PCA的实验步骤;3. 分析PCA在实际应用中的优缺点;4. 提高数据降维的技能。
四、实验原理主成分分析的基本原理是将原始数据投影到新的坐标系中,该坐标系由主成分构成。
主成分是原始数据中方差最大的方向,可以看作是数据的主要特征。
通过选择合适的主成分,可以将高维数据降维到低维空间,同时保留大部分信息。
五、实验步骤1. 数据准备:选择一个高维数据集,例如鸢尾花数据集。
2. 数据标准化:将数据集中的每个特征缩放到均值为0、标准差为1的范围,以便消除不同特征之间的尺度差异。
3. 计算协方差矩阵:计算标准化数据集的协方差矩阵,以衡量不同特征之间的相关性。
4. 特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
5. 选择主成分:根据特征值的大小选择前k个特征向量,这些向量对应的主成分代表数据的主要特征。
6. 数据投影:将原始数据投影到选择的主成分上,得到降维后的数据。
六、实验结果与分析1. 实验结果:通过实验,我们得到了降维后的数据集,并与原始数据集进行了比较。
结果表明,降维后的数据集保留了大部分原始数据的信息,同时降低了数据的维度。
2. 结果分析:实验结果表明,PCA在数据降维方面具有良好的效果。
然而,PCA也存在一些局限性,例如:(1)PCA假设数据服从正态分布,对于非正态分布的数据,PCA的效果可能不理想;(2)PCA降维后,部分信息可能丢失,尤其是在选择主成分时,需要权衡保留信息量和降低维度之间的关系;(3)PCA降维后的数据可能存在线性关系,导致模型难以捕捉数据中的非线性关系。
主成分分析和因子分析实验报告
主成分分析和因子分析实验报告目录主成分分析和因子分析实验报告 (1)引言 (1)研究背景 (1)研究目的 (2)研究意义 (3)主成分分析 (4)主成分分析的概念 (4)主成分分析的原理 (5)主成分分析的步骤 (6)因子分析 (7)因子分析的概念 (7)因子分析的原理 (8)因子分析的步骤 (8)实验设计 (9)数据收集 (9)数据预处理 (11)主成分分析实验 (11)因子分析实验 (13)实验结果与分析 (14)主成分分析结果 (14)因子分析结果 (15)结果对比与讨论 (16)结论与展望 (17)实验结论 (17)实验不足与改进方向 (17)后续研究建议 (18)参考文献 (19)引言研究背景主成分分析(Principal Component Analysis,简称PCA)和因子分析(Factor Analysis,简称FA)是多元统计分析中常用的降维技术,广泛应用于数据挖掘、模式识别、图像处理、金融风险评估等领域。
这两种方法可以帮助我们从大量的变量中提取出最为重要的信息,简化数据集,减少冗余信息,同时保留原始数据的主要特征。
随着信息技术的迅速发展,数据的规模和复杂性不断增加,传统的统计分析方法已经无法满足对大规模数据的处理需求。
在这种背景下,主成分分析和因子分析成为了研究者们的关注焦点。
它们能够对高维数据进行降维处理,提取出最为重要的特征,从而更好地理解和解释数据。
主成分分析是一种无监督学习方法,通过线性变换将原始数据映射到一个新的坐标系中,使得新坐标系下的变量之间不相关。
这样做的好处是可以减少数据的维度,同时保留了原始数据的主要信息。
主成分分析的基本思想是找到能够最大程度解释数据方差的投影方向,即找到一组新的变量,使得它们之间的协方差为零。
这些新的变量被称为主成分,它们按照解释方差的大小排序,前几个主成分能够解释原始数据中大部分的方差。
因子分析是一种潜变量模型,它假设观测数据是由一组潜在因子和测量误差共同决定的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验六 主成分分析一、实验目的通过本次实验,掌握SPSS 及ENVI 的主成分分析方法。
二、有关概念1. 主成分分析的概念主成分分析(又称因子分析),是将多个实测变量转换为少数几个不相关的综合指标的多元统计分析方法。
代表各类信息的综合指标就称为因子或主成份。
主成分分析的数学模型可写为:m m x a x a x a x a z 131********++++=m m x a x a x a x a z 23232221212++++=m m x a x a x a x a z 33332321313++++=………m nm n n n n x a x a x a x a z ++++= 332211其中,x 1、x 2、 x 3、 x 4 …x m 为原始变量;z 1、 z 2、 z 3、 z 4 …z n 为主成份,且有m≥n 。
写成矩阵形式为:Z=AX 。
Z 为主成份向量,A 为主成份变换矩阵,X 为原始变量向量。
主成份分析的目的是把系数矩阵A 求出,主成份Z1、Z2、Z3…在总方差中所占比重依次递减。
从理论上讲m=n 即有多少原始变量就有多少主成份,但实际上前面几个主成份集中了大部分方差,因此取主成份数目远远小于原始变量的数目,但信息损失很小。
因子分析的一个重要目的还在于对原始变量进行分门别类的综合评价。
如果因子分析结果保证了因子之间的正交性(不相关)但对因子不易命名,还可以通过对因子模型的旋转变换使公因子负荷系数向更大(向1)或更小(向0)方向变化,使得对公因子的命名和解释变得更加容易。
进行正交变换可以保证变换后各因子仍正交,这是比较理想的情况。
如果经过正交变换后对公因子仍然不易解释,也可进行斜交旋转。
2. 因子提取方法SPSS 提供的因子提取方法有:①Principal components 主成份法。
该方法假设变量是因子的纯线性组合。
这是SPSS最通用的因子提取方法,故因子分析有时又称为主成份分析。
②Unweighted least square不加权最小平方法。
该方法使观测的和再生的相关阵之差的平方最小。
③Generalized least square 用变量的单值加权,使观测的和再生的相关阵之差的平方最小。
④Maximum likelihood 最大似然法。
此方法不要求多元正态分布。
给出参数估计,如果样本来自多元正态总体它们与原始变量的相关阵极为相似。
⑤Principal axis factoring 使用多元相关的平方作为对公因子方差的初始估计。
⑥Alpha factoring α因子提取法3.因子旋转方法SPSS提供的因子旋转方法有:①None 不进行旋转。
此为系统默认的选择项。
②Varimax方差最大旋转。
③Equamax 平均正交旋转。
④Quartmax四次方最大正交旋转。
⑤Direct Oblimin 斜交旋转,指定此项可以在下面的矩形框中键入Delta 值,该值应该在0~-1之间,是因子映象自相关的范围。
0值产生最高相关因子,大负数产生旋转的结果与正交接近。
三、实验内容1. 在上海市宝山、吴淞地区的环境质量综合评价中,对20个监测点的大气、地面水和土壤要素进行监测,得到三种要素的实测超标倍数数据。
本实验对这批资料进行主成份分析,为进一步进行环境综合分析作准备。
2. 对2009年钱塘江湾TM影像进行主成分分析四、实验步骤(一)SPSS主成分分析1.主成分分析的基本步骤(1)打开“d:\SPSS实习\主成份分析.sav”文件,选择Analyze菜单下的Data Reduction的Factor项,展开主对话框。
(2)在左侧源变量框中选取“大气超标倍数”、“地面水超标倍数”“土壤超标倍数”变量,进入Variables框中,作为参与因子分析的变量。
(3)单击Descriptives按钮,展开相应的子对话框。
在Statistics组中选取Initial solution 选择项,显示初始分析结果,给出原始变量的公因子方差、与变量数目相等的因子、各因子的特征值、各因子特征占总方差的百分比以及累积百分比。
在Correlation Matrix组中选取Coefficients,显示原始变量相关系数矩阵。
按Continue返回主对话框。
(Statistics组中的Univariate descriptive项要求给出各变量的均数和标准差;Correlation Matrix组提供以下几种检验变量是否适合作因子分析的方法:(4)单击Extraction按钮,展开相应的子对话框。
在Method组中选择Principal components主成份法作为提取公因子的方法;在Extract组中选取Number of factors,并在其右侧框中输入“2”,指定提取公因子的数目为2;在Display组中选取Unrotated factor solution及Screen plot选项,要求显示未经旋转的因子提取结果因了载荷碎石图;Maximum iterations for convergence为因子分析收敛的最大迭代次数,系统默认为25;按Continue返回主对话框。
(5)单击Scores按钮,展开相应的子对话框。
选取Save as variables 选项,即要求将因子得分作为新变量保存在数据文件中;在Method组选取Regression选项,即因子的得分用回归法,其因子得分的均值为0(Regression Method: A method for estimating factor score coefficients. The scores that are produced have a mean of 0 and a variance equal to the squared multiple correlation between the estimated factor scores and the true factor values. The scores may be correlated even when factors are orthogonal.);选取Display factor score coeffient matrix,显示因子得分系数矩阵;按Continue返回主对话框(6)单击OK,提交运行。
(7)输出结果分析。
2.主成分分析结果分析输出结果分析如下列表6.1~表6.6所示:表6.1给出了三个原始变量的相关系数矩阵。
表 6.1表6.2第二列给出原始变量的公因子方差,三个均为1,三个变量的公因子方差之总和为3;第三列给出的是使用两个因子代替原始变量后对各原始变量方差解释的百分比。
表 6.2表6.3为方差解释表。
第一列为主成份名,第二、三、四列分别为第一、二、三主成份的特征值、方差百分比、方差累积百分比;后三列为选用两个主成份时的特征值、方差百分比、方差累积百分比。
表 6.3表6.4为因子矩阵表。
给出原始变量对第一、第二主成份的贡献。
表 6.4a 2 components extracted.表6.5为因子得分系数矩阵。
给出第一、第二主成份与原始变量的关系。
根据该矩阵可以写出因子的表达式为:Factor1=0.281*x1*+0.484*x2*+0.516*x3* Factor2=0.955*x1*-0.414*x2*-0.131*x3*可以说,用这两个因子代替三个原始变量,可以概括原始变量所包含信息的87.806%。
表 6.5Component Score Coefficient MatrixComponent1 2大气超标倍数.281 .955地面水超标倍数.484 -.414土壤超标倍数.516 -.131Extraction Method: Principal ComponentAnalysis.Component Scores.表6.6给出了两主成份间的协方差矩阵。
表 6.6Component Score Covariance MatrixComponent 1 21 1.000 .0002 .000 1.000Extraction Method: Principal ComponentAnalysis.Component Scores.图6.1可以看出因子1与因子2,以及因子2与因子3之间的特征值之差值比较大,可以初步得出提取两个因子将能概括绝大部分信息。
图 6.1注:在“Factor1=0.281*x1*+0.484*x2*+0.516*x3*及Factor2=0.955*x1*-0.414*x2*-0.131*x3*”中的x1* \x2*\x3*\变量是原始变量做了均值为0处理后的新变量。
(二)ENVI主成分分析1. 打开LT51180392009262BJC00下的B1-6及B7, 用Basic Tools下的Layer Stacking进行6波段叠合(如图6-2,拾取Import File选择叠合的波段,拾取Reorder Files对波段进行排序,建议按B1—B7顺序),并选择Output Result to File,将结果输出到QT_River文件。
图6-22. 用ROI TOOLS选择一块感兴趣区(建议选择地类比较全的部分),并将子集存为subset文件。
3. ENVI 【Transform】->【Principal Components】->【Forward PC Rotate 正向PC旋转】->【Compute New Statistics and Rotate】,展开如图所示对话框,选中文件,并进行空间子集、光谱子集以及掩膜设置后,按OK,进入如图6-3所示对话框。
图6-3图6-44. 在图6-4对话框的Stats Subset中,输入小于1如0.1的值,表示在统计计算时只用到十分之一像元(也可保持缺省值不变,表示统计全部像元),在Output Stats Filename 中输入PC_stats,即将统计结果放入该文件,并在“Select Subset from Eigenvalues”中选择Yes, 统计信息将被计算,并出现如图6-5 Select Output PC Bands 对话框。
该对话框中列出每个波段和其相应的特征值,同时也列出每个主成分波段中包含的数据方差的累积百分比。
在“Number of Output PC Bands”文本框中,键入一个数字或点击箭头按钮,确定要输出的波段数,此处可选3,也可保持6不变,看主成份结果图。
可以看出,前三个主成份占了原始6个波段信息的98%以上,因此完全可以用前三个主成份来代替原始6个波段来进行后续的分类处理。