[计算机]算法分析与设计课程综合实验
实验报告算法分析

实验报告算法分析实验报告:算法分析引言在计算机科学领域中,算法是解决问题的一种方法或步骤的描述。
通过对算法的分析,我们可以评估其效率和性能,从而选择最优的算法来解决特定的问题。
本实验报告旨在介绍算法分析的基本概念和方法,并通过实例来说明其应用。
一、算法分析的背景算法分析是计算机科学中的重要研究领域,它关注如何评估算法的效率和性能。
在实际应用中,我们经常面临着需要在有限的时间内解决大规模问题的挑战。
因此,选择一个高效的算法是至关重要的。
算法分析的目标是通过定量分析算法的时间复杂度和空间复杂度,为选择最佳算法提供依据。
二、算法分析的方法1. 时间复杂度分析时间复杂度是衡量算法执行时间的一种指标。
通常使用大O表示法来表示时间复杂度。
通过计算算法执行所需的基本操作次数,可以得到算法的时间复杂度。
常见的时间复杂度有O(1)、O(log n)、O(n)、O(n log n)和O(n^2)等。
时间复杂度越低,算法执行所需的时间越短。
2. 空间复杂度分析空间复杂度是衡量算法内存使用的一种指标。
通过计算算法执行所需的额外空间大小,可以得到算法的空间复杂度。
常见的空间复杂度有O(1)、O(n)和O(n^2)等。
空间复杂度越低,算法所需的内存空间越小。
三、算法分析的应用算法分析在计算机科学的各个领域都有广泛的应用。
以下是几个常见的应用示例:1. 排序算法排序算法是计算机科学中的经典问题之一。
通过对不同排序算法的时间复杂度进行分析,可以选择最适合特定需求的排序算法。
例如,快速排序算法的平均时间复杂度为O(n log n),在大规模数据排序中表现出色。
2. 图算法图算法是解决图结构相关问题的一种方法。
通过对图算法的时间复杂度和空间复杂度进行分析,可以选择最适合解决特定图问题的算法。
例如,广度优先搜索算法的时间复杂度为O(V+E),其中V和E分别表示图的顶点数和边数。
3. 动态规划算法动态规划算法是解决具有重叠子问题性质的问题的一种方法。
算法设计与分析课程的教学探索与实践

领域的最新进展 , 比如神经网络算法 、 遗传算法等。 本课程 的教学可以尝试从以下四部分展开 , 不同层次的学生可 以 进行相应的调整和取舍 : ( 1 ) 介绍算法的基本概念 、 算法的 数学基础以及算法复杂度分析 ; ( 2 )分别针对排序问题和 组合优化问题 , 讨论各种已有的算法 , 并介绍常用 的算法
况, 我们选择王红梅编写的《 算法设计与分析》 作为教材 , 该教材的特点是不深入讲解高深的理论 , 以易懂的方式阐 述各种经典算法[ 3 1 。建议算法设计与分析课程学时数大约 7 2 学时左右 , 其中课堂教学为4 8 学时 , 实验2 4 学时。 实验学 时要 占到总课时的3 0 %以上, 坚持“ 实践 、 实际 、 实用” 的原 则, 坚持实战教学 , 培养学生的实践能力和创新能力。
文章 编 号 : 1 6 7 4 — 9 3 2 4 ( 2 0 1 3 ) 1 3 - 0 2 1 8 — 0 2
算法设计与分析是计算机专业 的专业基础课 , 是计算
机专业 课 中一 门处 于 核心 地位 的课 程 。 该 课 程 的主要 目的
具有 重要 意 义 。
对于如何解决上述问题以更好地进行教学 , 本文根据 实际的教学经验 , 从教学内容 、 教学方法 、 实践环节和考核 方式等方面来探讨如何对这门课程进行适当的教学改革 。
方 面 的理论 研究 , 如 计算 模 型 、 N P 完 全 问题 和 问题 复 杂 度 等理论 ; ( 3 ) 近年来在并行算法 、 随机算法 、 近似算法 、 加密
算法 、 智能优化算法 、 模式识别算法 、 神经网络算法 、 遗传 算法 以及其他算法领域方面的最新研究成果 。 作为面向计 算机科学与技术专业和软件工程专业的课程 , 算法分析与 设计在 内容组织上应该体现理论与实际应用并重的原则 , 兼顾 串行算法和并行算法两大部分 , 同时介绍一些本学科
算法分析与设计实验报告

算法分析与设计实验报告算法分析与设计实验报告一、引言算法是计算机科学的核心,它们是解决问题的有效工具。
算法分析与设计是计算机科学中的重要课题,通过对算法的分析与设计,我们可以优化计算机程序的效率,提高计算机系统的性能。
本实验报告旨在介绍算法分析与设计的基本概念和方法,并通过实验验证这些方法的有效性。
二、算法分析算法分析是评估算法性能的过程。
在实际应用中,我们常常需要比较不同算法的效率和资源消耗,以选择最适合的算法。
常用的算法分析方法包括时间复杂度和空间复杂度。
1. 时间复杂度时间复杂度衡量了算法执行所需的时间。
通常用大O表示法表示时间复杂度,表示算法的最坏情况下的运行时间。
常见的时间复杂度有O(1)、O(log n)、O(n)、O(n log n)和O(n^2)等。
其中,O(1)表示常数时间复杂度,O(log n)表示对数时间复杂度,O(n)表示线性时间复杂度,O(n log n)表示线性对数时间复杂度,O(n^2)表示平方时间复杂度。
2. 空间复杂度空间复杂度衡量了算法执行所需的存储空间。
通常用大O表示法表示空间复杂度,表示算法所需的额外存储空间。
常见的空间复杂度有O(1)、O(n)和O(n^2)等。
其中,O(1)表示常数空间复杂度,O(n)表示线性空间复杂度,O(n^2)表示平方空间复杂度。
三、算法设计算法设计是构思和实现算法的过程。
好的算法设计能够提高算法的效率和可靠性。
常用的算法设计方法包括贪心算法、动态规划、分治法和回溯法等。
1. 贪心算法贪心算法是一种简单而高效的算法设计方法。
它通过每一步选择局部最优解,最终得到全局最优解。
贪心算法的时间复杂度通常较低,但不能保证得到最优解。
2. 动态规划动态规划是一种将问题分解为子问题并以自底向上的方式求解的算法设计方法。
它通过保存子问题的解,避免重复计算,提高算法的效率。
动态规划适用于具有重叠子问题和最优子结构的问题。
3. 分治法分治法是一种将问题分解为更小规模的子问题并以递归的方式求解的算法设计方法。
算法分析实验指导书(王红梅)

《算法设计与分析》实验指导书计算机科学与技术学院石少俭实验一分治法1、实验目的(1)掌握设计有效算法的分治策略。
(2)通过快速排序学习分治策略设计技巧2、实验要求(1)熟练掌握分治法的基本思想及其应用实现。
(2)理解所给出的算法,并对其加以改进。
3、分治法的介绍任何一个可以用计算机求解的问题所需的计算时间都与其规模有关。
问题的规模越小,越容易直接求解,解题所需的计算时间也越少。
而当n较大时,问题就不那么容易处理了。
要想直接解决一个规模较大的问题,有时是相当困难的。
分治法的设计思想是,将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
如果原问题可分割成k个子问题,1<k≤n ,且这些子问题都可解,并可利用这些子问题的解求出原问题的解,那么这种分治法就是可行的。
由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。
在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。
这自然导致递归过程的产生。
分治与递归像一对孪生兄弟,经常同时应用在算法设计之中,并由此产生许多高效算法。
分治法的适用条件(1)该问题的规模缩小到一定的程度就可以容易地解决;(2)该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
(3)利用该问题分解出的子问题的解可以合并为该问题的解;(4)该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
上述的第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加;第二条特征是应用分治法的前提,它也是大多数问题可以满足的,此特征反映了递归思想的应用;第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑贪心法或动态规划法。
第四条特征涉及到分治法的效率,如果各子问题是不独立的,则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
《计算机算法设计与分析》课程设计

《计算机算法设计与分析》课程设计用分治法解决快速排序问题及用动态规划法解决最优二叉搜索树问题及用回溯法解决图的着色问题一、课程设计目的:《计算机算法设计与分析》这门课程是一门实践性非常强的课程,要求我们能够将所学的算法应用到实际中,灵活解决实际问题。
通过这次课程设计,能够培养我们独立思考、综合分析与动手的能力,并能加深对课堂所学理论和概念的理解,可以训练我们算法设计的思维和培养算法的分析能力。
二、课程设计内容:1、分治法:(2)快速排序;2、动态规划:(4)最优二叉搜索树;3、回溯法:(2)图的着色。
三、概要设计:分治法—快速排序:分治法的基本思想是将一个规模为n的问题分解为k个规模较小的子问题,这些子问题互相独立且与原问题相同。
递归地解这些子问题,然后将各个子问题的解合并得到原问题的解。
分治法的条件:(1) 该问题的规模缩小到一定的程度就可以容易地解决;(2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质;(3) 利用该问题分解出的子问题的解可以合并为该问题的解;(4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
抽象的讲,分治法有两个重要步骤:(1)将问题拆开;(2)将答案合并;动态规划—最优二叉搜索树:动态规划的基本思想是将问题分解为若干个小问题,解子问题,然后从子问题得到原问题的解。
设计动态规划法的步骤:(1)找出最优解的性质,并刻画其结构特征;(2)递归地定义最优值(写出动态规划方程);(3)以自底向上的方式计算出最优值;(4)根据计算最优值时得到的信息,构造一个最优解。
●回溯法—图的着色回溯法的基本思想是确定了解空间的组织结构后,回溯法就是从开始节点(根结点)出发,以深度优先的方式搜索整个解空间。
这个开始节点就成为一个活结点,同时也成为当前的扩展结点。
在当前的扩展结点处,搜索向纵深方向移至一个新结点。
这个新结点就成为一个新的或节点,并成为当前扩展结点。
“算法分析与设计”课程教学改革和实践

通过实践 ,提 高了 学生学习本门课程的学习热情,有利于学生独立分析和解决问题 能力的培 养。 关键词 : 算法分析与设计 ; 启发式 ; 参与式 ;因材施教
随机 化 算 法 、 近 似 算 法 等 。 而在 教 学 计 划 中,课 程 的教 学 课 时 个问题 。同时提 出新 的算法设 计改进问题 ,以便 让学 生进 行思
是有限的,要将这些算法设计的策略全部讲透彻非常困难。
2 课 程 教 学内容难 以跟 上 当 科 技 发 展步伐 . 今
考和研究 。变单向传 输式教学 为双 向互动式教学 ,变 以强调抽 象算法设计为主的理论 讲授为探究解决应用问题为主 的设计引
通过 对计算机算法系统的学 习与研 究,理解和掌握算法设计的
在教学 内容 的选择 上,总的原则是 :内容难度适 中,结合
主要方法 ,培 养对 算法 的计算复杂性 进行正确分析 的能力,为 实际问题和相关课程 的知识讲解 算法设 计技巧及算法分析方法, 独立地设计算法和对给定算法进行复杂性分析奠定 坚实 的理论 使学 生 既能 理 解 ,又 能拓 展 创 新 。
CE E中国 电力教育 P
面
D I O 编码 :1.9 9 j sn 10 — 0 92 1 . .3 03 6 / . s . 7 0 7 .0 01 02 i 0 6
‘ ‘ 算法分析与设计’ ’课程教学改革和实践
李 涵
摘要 : 算法分析与设计”是计算机科 学与技术以及相关专业的重要课 程之・,是理论知 识和能力并重的课程。文中结合算法分析 “
算法设计与分析实验报告

算法设计与分析报告学生姓名学号专业班级指导教师完成时间目录一、课程内容 (3)二、算法分析 (3)1、分治法 (3)(1)分治法核心思想 (3)(2)MaxMin算法分析 (3)2、动态规划 (4)(1)动态规划核心思想 (4)(2)矩阵连乘算法分析 (5)3、贪心法 (5)(1)贪心法核心思想 (5)(2)背包问题算法分析 (6)(3)装载问题算法分析 (7)4、回溯法 (7)(1)回溯法核心思想 (7)(2)N皇后问题非递归算法分析 (7)(3)N皇后问题递归算法分析 (8)三、例子说明 (9)1、MaxMin问题 (9)2、矩阵连乘 (10)3、背包问题 (10)4、最优装载 (10)5、N皇后问题(非递归) (11)6、N皇后问题(递归) (11)四、心得体会 (12)五、算法对应的例子代码 (12)1、求最大值最小值 (12)2、矩阵连乘问题 (13)3、背包问题 (15)4、装载问题 (17)5、N皇后问题(非递归) (19)6、N皇后问题(递归) (20)一、课程内容1、分治法,求最大值最小值,maxmin算法;2、动态规划,矩阵连乘,求最少连乘次数;3、贪心法,1)背包问题,2)装载问题;4、回溯法,N皇后问题的循环结构算法和递归结构算法。
二、算法分析1、分治法(1)分治法核心思想当要求解一个输入规模为n,且n的取值相当大的问题时,直接求解往往是非常困难的。
如果问题可以将n个输入分成k个不同子集合,得到k个不同的可独立求解的子问题,其中1<k≤n, 而且子问题与原问题性质相同,原问题的解可由这些子问题的解合并得出。
那末,这类问题可以用分治法求解。
分治法的核心技术1)子问题的划分技术.2)递归技术。
反复使用分治策略将这些子问题分成更小的同类型子问题,直至产生出不用进一步细分就可求解的子问题。
3)合并技术.(2)MaxMin算法分析问题:在含有n个不同元素的集合中同时找出它的最大和最小元素。
算法分析与设计课程大纲
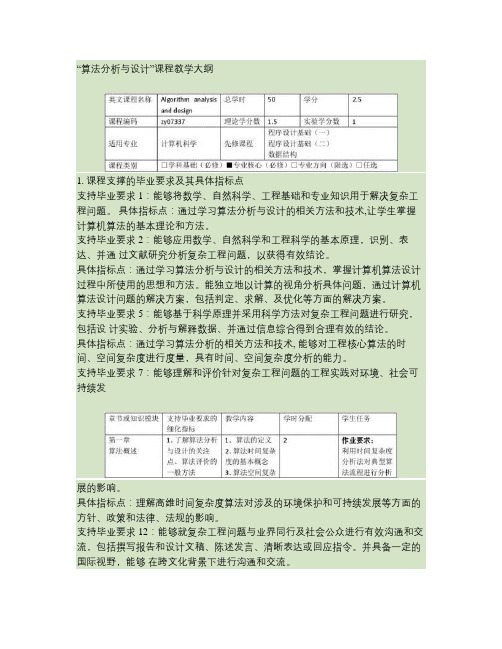
“算法分析与设计”课程教学大纲1. 课程支撑的毕业要求及其具体指标点支持毕业要求1:能够将数学、自然科学、工程基础和专业知识用于解决复杂工程问题。
具体指标点:通过学习算法分析与设计的相关方法和技术,让学生掌握计算机算法的基本理论和方法。
支持毕业要求2:能够应用数学、自然科学和工程科学的基本原理,识别、表达、并通过文献研究分析复杂工程问题,以获得有效结论。
具体指标点:通过学习算法分析与设计的相关方法和技术,掌握计算机算法设计过程中所使用的思想和方法。
能独立地以计算的视角分析具体问题,通过计算机算法设计问题的解决方案,包括判定、求解、及优化等方面的解决方案。
支持毕业要求5:能够基于科学原理并采用科学方法对复杂工程问题进行研究,包括设计实验、分析与解释数据、并通过信息综合得到合理有效的结论。
具体指标点:通过学习算法分析的相关方法和技术, 能够对工程核心算法的时间、空间复杂度进行度量,具有时间、空间复杂度分析的能力。
支持毕业要求7:能够理解和评价针对复杂工程问题的工程实践对环境、社会可持续发展的影响。
具体指标点:理解高维时间复杂度算法对涉及的环境保护和可持续发展等方面的方针、政策和法律、法规的影响。
支持毕业要求12:能够就复杂工程问题与业界同行及社会公众进行有效沟通和交流,包括撰写报告和设计文稿、陈述发言、清晰表达或回应指令。
并具备一定的国际视野,能够在跨文化背景下进行沟通和交流。
具体指标点:让学生在算法设计的时候与同行、领导以及下属等人员沟通,能清晰地表达其想法和思路,并掌握各种国际标准下的算法的撰写方法。
2. 课程教学内容对毕业要求及指标点的支撑3. 考核方式及成绩评定方式该课程的考核采用综合考核方式。
总成绩分为:期末笔试成绩(30%)、过程成绩(30%)、实验成绩(40%)。
过程成绩主要指平时上课出勤及实验态度得分。
本课程设置7 个实验。
前5个实验提前1 周布置给学生,要求学生通过课外进行实验预习,对实验内容进行分析和设计,写出基本程序代码,以保证课堂实验的效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
算法分析与设计课程综合实验Design and Analysis of Algorithms1 Map Routing要求:Mandatory.实验目的:Implement the classic Dijkstra's shortest path algorithm and optimize it for maps. Such algorithms are widely used in geographic information systems (GIS) including MapQuest and GPS-based car navigation systems.实验内容及要求:Maps. For this assignment we will be working with maps, or graphs whose vertices are points in the plane and are connected by edges whose weights are Euclidean distances. Think of the vertices as cities and the edges as roads connected to them. To represent a map in a file, we list the number of vertices and edges, then list the vertices (index followed by its x and y coordinates), then list the edges (pairs of vertices), and finally the source and sink vertices. For example, Input6 represents the map below:Dijkstra's algorithm.Dijkstra's algorithm is a classic solution to the shortest path problem. It is described in section 24.3 in CLRS. The basic idea is not difficult to understand. We maintain, for every vertex in the graph, the length of the shortest known path from the source to that vertex, and we maintain these lengths in a priority queue. Initially, we put all the vertices on the queue with an artificially high priority and then assign priority 0.0 to the source. The algorithm proceeds by taking the lowest-priority vertex off the PQ, then checking all the vertices that can be reached from that vertex by one edge to see whether that edge gives a shorter path to the vertex from the source thanthe shortest previously-known path. If so, it lowers the priority to reflect this new information.Here is a step-by-step description that shows how Dijkstra's algorithm finds the shortest path 0-1-2-5 from 0 to 5 in the example above.process 0 (0.0)lower 3 to 3841.9lower 1 to 1897.4process 1 (1897.4)lower 4 to 3776.2lower 2 to 2537.7process 2 (2537.7)lower 5 to 6274.0process 4 (3776.2)process 3 (3841.9)process 5 (6274.0)This method computes the length of the shortest path. To keep track of the path, we also maintain for each vertex, its predecessor on the shortest path from the source to that vertex. The files EuclideanGraph.java, Point.java, IndexPQ.java, IntIterator.java, and Dijkstra.java provide a bare bones implementation of Dijkstra's algorithm for maps, and you should use this as a starting point. The client program ShortestPath.java solves a single shortest path problem and plots the results using turtle graphics. The client program Paths.java solves many shortest path problems and prints the shortest paths to standard output. The client program Distances.java solves many shortest path problems and prints only the distances to standard output.Your goal.Optimize Dijkstra's algorithm so that it can process thousands of shortest path queries for a given map. Once you read in (and optionally preprocess) the map, your program should solve shortest path problems in sublinear time. One method would be to precompute the shortest path for all pairs of vertices; however you cannot afford the quadratic space required to store all of this information. Your goal is to reduce the amount of work involved per shortest path computation, without using excessive space. We suggest a number of potential ideas below which you may choose to implement. Or you can develop and implement your own ideas.Idea 1.The naive implementation of Dijkstra's algorithm examines all V vertices in the graph. An obvious strategy to reduce the number of vertices examined is to stop the search as soon as you discover the shortest path to the destination. With this approach, you can make the running time per shortest path query proportional to E' log V' where E' and V' are the number of edges and vertices examined by Dijkstra's algorithm. However, this requires some care because just re-initializi ng all of the distances to ∞ would take time proportional to V. Since you are doing repeated queries, you can speed things up dramatically by only re-initializing those values that changed in the previous query.Idea 2.You can cut down on the search time further by exploiting the Euclidean geometry of the problem, as described in section 21.5 in the book of Algorithm in C Part V. For general graphs, Dijkstra's relaxes edge v-w by updating d[w] to the sum of d[v] plus the distance from v to w. For maps, we instead update d[w] to be the sum of d[v] plus the distance from v to w plus the Euclidean distance from w to d minus the Euclidean distance from v to d. This is known as the A* algorithm. This heuristics affects performance, but not correctness.Idea e a faster priority queue. There is some room for optimization in the supplied priority queue. You could also consider using a multiway heap as in Sedgewick Program 20.10.Testing.The file usa.txt contains 87,575 intersections and 121,961 roads in the continental United States. The graph is very sparse - the average degree is 2.8. Your main goal should be to answer shortest path queries quickly for pairs of vertices on this network. Your algorithm will likely perform differently depending on whether the two vertices are nearby or far apart. We provide input files that test both cases. You may assume that all of the x and y coordinates are integers between 0 and 10,000.实验类型:Verification.适用对象:Undergraduate for Computer School2 Document Distance Problem要求:Mandatory.实验目的:Design and implement the document distance problem and optimize it for data.实验内容及要求:Let D be a text document (e.g. the complete works of William Shakespeare).A word is a consecutive sequence of alphanumeric characters, such as "Hamlet" or "2007". We'll treat all upper-case letters as if they are lower-case, so that "Hamlet" and "hamlet" are the same word. Words end at a non-alphanumeric character, so "can't" contains two words: "can" and "t".The word frequency distribution of a document D is a mapping from words w to their frequency count, which we'll denote as D(w).We can view the frequency distribution D as vector, with one component per possible word. Each component will be a non-negative integer (possibly zero).The norm of this vector is defined in the usual way:.The inner-product between two vectors D and D' is defined as usual..Finally, the angle between two vectors D and D' is defined:This angle (in radians) will be a number between 0 and since the vectors are non-negative in each component. Clearly,angle(D,D) = 0.0for all vectors D, andangle(D,D') = π / 2if D and D' have no words in common.Example: The angle between the documents "To be or not to be" and "Doubt truth to be a liar" isWe define the distance between two documents to be the angle between their word frequency vectors.The document distance problem is thus the problem of computing the distance between two given text documents.An instance of the document distance problem is the pair of input text documents.3 Edit Distance要求:Mandatory.实验目的:Many word processors and keyword search engines have a spelling correction feature. If you type in a misspelled word x, the word processor or search engine can suggest a correction y. The correction y should be a word that is close to x. One way to measure the similarity in spelling between two text strings is by “edit distance”. The notion of edit distance is useful in other fields as well. For example, biologists use edit distance to characterize the similarity of DNA or protein sequences.实验内容及要求:The edit distance d(x, y) of two strings of text, x[1..m] and y[1..n], is defined to be the minimum possible cost of a sequence of “transformation operations”(defined below) that transforms string x[1..m] into string y[1..n]. To define the effect of thetransformation operations, we use an auxiliary string z[1..s] that holds the intermediate results. At the beginning of the transformation sequence s = m and z[1..s] = x[1..m] (i.e., we start with string x[1..m]). At the end of the transformation sequence, we should have s = n and z[1..s] = y[1..n](i.e., our goal is to transform into string y[1..n]). Throughout the transformation, we maintain the current length s of string z, as well as a cursor position i, i.e., an index into string z. The invariant 1 ≤i ≤s +1 holds at all times during the transformation. (Notice that the cursor can move one space beyond the end of the string z in order to allow insertion at the end of the string.)Each transformation operation may alter the string z, the size s, and the cursor position i. Each transformation operation also has an associated cost. The cost of a sequence of transformation operations is the sum of the costs of the individual operations on the sequence. The goal of the edit-distance problem is to find a sequence of transformation operation of minimum cost that transforms x[1..m] into y[1..n].There are five transformation operations:Operation Cost Effectleft 0 If i = 1 then do nothing. Otherwise, set i ←i-1right 0 If i = s +1 then do nothing. Otherwise, set i←i-1.replace 4 If i = s +1 then do nothing. Otherwise, replace the character underthe cursor by another character c by setting z[i] ←c, and thenincrementing i.delete 2 If i = s +1 then do nothing. Otherwise, delete the character c underthe cursor by setting z[i..s] ← z[i+1..s+1] and decrementing s. Thecursor position i does not change.insert 3 Insert the character c into string z by incrementing s, setting z[i+1..s] ←z[i..s-1], setting z[i] ←c, and then incrementing index i. As an example, one way to transform the source string algorithm to the target string analysis is to use the sequence of operations shown in Table 1, where the position of the underlined character represents the cursor position i. Many other sequences of transformation operations also transform algorithm to analysis − the solution in Table 1 is not unique − and some other solutions cost more while some others cost less.Operation z Cost Totalinitial string algorithm 0 0right algorithm 0 0right algorithm 0 0replace by y alyorithm 4 4replace by s alysrithm 4 8replace by i alysiithm 4 12replace by s alysisthm 4 16delete alysishm 2 18delete alysism 2 20delete alysis_ 2 22left alysis 0 22left alysis 0 22left alysis 0 22left alysis 0 22left alysis 0 22insert n anlysis 3 25insert a analysis 3 28Table 1: Transforming algorithm into analysis(a)It is possible to transform algorithm to analysis without using the “left” operation.Give a sequence of operations in the style of Table 1 that has the same cost as in Table 1 but does not use the “left” operation.(b)Argue that, for any two strings x and y with edit distance d(x, y), there exists asequence S of transformation operations that transforms x to y with cost d(x, y) where S does not contain any “left” operations.(c)Show that the problem of calculation the edit distance d(x, y) exhibits optimalsubstructure.(Hint: Consider all suffixes of x and y.)(d)Recursively define the value of edit distance d(x, y) in terms of the suffixes of stringsx and y. Indicate how edit distance exhibits overlapping subproblems.(e)Describe a dynamic-programming algorithm that computes the edit distance fromx[1..m] to y[1..n].(Do not use a memoized recursive algorithm. Your algorithm should be a classical, bottom-up, tabular algorithm.) Analyze the running time and space requirements of your algorithm.(f)Implement your algorithm as a computer program in any language you wish. Yourprogram should calculate the edit distance d(x, y) between two strings x and y using dynamic programming and print out the corresponding sequence of transformation operations in the style of Table 1. Run your program on the stringsx= “electrical engineering”,y= “computer science”.Submit the source code of your program electronically on the class website, and hand in a printout of your source code and your results. Sample input and output text is provided on the class website to help you debug your program. These solutions are not necessarily unique: there may be other sequences of transformation operations that achieve the same cost. As usual, you may collaborate to solve this problem, but you must write the program by yourself.(g) Run your program on the three input files provided on the class website. Each inputfile contains the following four lines:1.The number of characters m in the string x.2.The string x.3.The number of characters n in the string y.4.The string y.Compute the edit distance d(x, y) for each input. Do not hand in a printout of the transformation operations for this problem part. (Extra bonus kudos if you can identify the source of all the texts, without searching the web.)(h) If z is implemented using an array, then the “insert” and “delete” operations requiresΘ(n) time. Design a suitable data structure that allow each of the five transformation operations to be implemented in Ο(1) time.实验类型:Synthesis适用对象:Undergraduate for Computer School4 Global Sequence Alignment要求:Optional实验目的:Write a program to compute the optimal sequence alignment of two DNA strings. This program will introduce you to the emerging field of computational biology in which computers are used to do research on biological systems. Further, you will be introduced to a powerful algorithmic design paradigm known as dynamic programming.实验内容及要求:Biology review. A genetic sequence is a string formed from a four-letter alphabet {Adenosine (A), Thymidine (T), Guanosine (G), Cytidine (C)} of biological macromolecules referred to together as the DNA bases. A gene is a genetic sequence that contains the information needed to construct a protein. All of your genes taken together are referred to as the human genome, a blueprint for the parts needed to construct the proteins that form your cells and, by extension, your body. Each new cell produced by your body receives a copy of the genome. This copying process, as well as natural wear and tear, introduces a small number of changes into the sequences of many genes. Among the most common changes are the substitution of one base for another and the deletion of a substring of bases; such changes are generally referred to as point mutations. As a result of these point mutations, the same gene sequenced from closely related organisms will have slight differences.The problem.Through your research you have found the following sequence of a gene in a previously unstudied organism.A A C A G T T A C CWhat is the function of the protein that this gene encodes? You could immediately begin a series of uninformed experiments in the lab to determine what role this gene plays. However, there is a good chance that it is a variant of a known gene in a previously studied organism. Since biologists and computer scientists have laboriously determined (and published) the genetic sequence of many organisms (including humans), you wouldlike to leverage this information to your advantage. We'll compare the above genetic sequence with one which has already been sequenced and whose function is well understood.T A A G G T C AIf the two genetic sequences are similar enough, we might expect them to have similar functions. We would like a way to quantify "similar enough".Edit-distance.We measure the similarity of two genetic sequences by using a very popular method known as the edit distance, a concept which is also widely used in spell checking, speech recognition, plagiarism detection, file revision, and computational linguistics. We align the two sequences, but we are permitted to insert gaps in either sequence (e.g., to make them have the same length). We pay a penalty for each gap that we insert and also for each pair of characters that mismatch in the final alignment. Intuitively, these penalties model the relative likeliness of point mutations arising from deletion/insertion and substitution. We produce a numerical score according to the following simple rule, which is widely used in biological applications:As an example, two possible alignments for the genetic sequences discussed above are:The first alignment has a score of 8, while the second one has a score of 7. The edit-distance is the score of the best possible alignment between the two genetic sequences over all possible alignments. In this example, the second alignment is in fact optimal, so the edit-distance between the two strings is 7. Computing the edit-distance between two strings is a nontrivial computational problem because we must find the best alignment among exponentially many possibilities. For example, if both strings are 100 characters long, then there are more than 10^75 possible alignments.A recursive solution.Your job is to write a program to compute the edit-distance and the optimal alignment of two genetic sequences. We can compute the edit-distancerecursively by breaking up the sequence alignment problem on the two original strings x and y into many alignment problems on the suffixes of the two strings. We use the notation x[i..M] to refer to the suffix of x consisting of the characters x[i], x[i+1], ..., x[M]. Note that x[M] is the string termination character '\0'. For example, consider the two strings x = "AACAGTTACC" and y = "TAAGGTCA" of length M = 10 and N = 8, respectively. Then, x[2..M] is "CAGTTACC" and y[8..N] is the empty string.Now, we return to our recursive solution technique. Consider the zeroth column in an optimal alignment of x[0..M] with y[0..N]. There are three possibilities:1.The optimal alignment matches x[0] = 'A' up with y[0] = 'T'. In this case, we pay apenalty of 1 for a mismatch and still need to align the string x[1..M] with y[1..N].What is the best way to do this? This subproblem is exactly the same as the original sequence alignment problem, except that the two inputs are each suffixes of the original inputs. We can solve this subproblem recursively.2.The optimal alignment matches the x[0] = 'A' up with a gap. In this case, we pay apenalty of 2 for a gap and still need to align the string x[1..M] with y[0..N]. This subproblem is identical to the original sequence alignment problem, except that the first input is a suffix of the original input.3.The optimal alignment matches the y[0] = 'T' up with a gap. In this case, we pay apenalty of 2 for a gap and still need to align the string x[0..M] with y[1..N]. This subproblem is identical to the original sequence alignment problem, except that the second input is a suffix of the original input.All of the resulting subproblems are sequence alignment problem on suffixes of the original inputs. Thus, we need a function, say opt(i, j) that returns the optimum value of aligning the input string x[i..M] with y[j..N]. Using this notation, the optimal value of our original sequence alignment problem is opt(0, 0). In general, to compute opt(i, j), we need to compute the minimum of the following three quantities:opt(i+1, j+1) + 0/1 by aligning x[i] with y[j], add 0 if a match, 1 if a mismatchopt(i+1, j) + 2 by aligning x[i] with a gapopt(i, j+1) + 2 by aligning y[j] with a gapFor our recursive scheme to bottom-out, we need a base case. Aligning an empty string with another string of length j requires inserting j gaps, for a total cost of 2j. Thus, in general we should set opt(M, j) = 2(N-j) and opt(i, N) = 2(M-i). For our example, the final matrix is:6 T 9 87 5 3 3 5 6 87 A 11 9 7 6 4 2 3 4 68 C 13 11 9 7 5 3 1 3 49 C 14 12 10 8 6 4 2 1 210 - 16 14 12 10 8 6 4 2 0The score of the optimal alignment is opt(0, 0) = 7.A dynamic programming approach. A direct implementation of the above recursive scheme will work, but it is spectacularly inefficient. If both input strings have N characters, then the number of recursive calls will exceed 2^N.To overcome this performance bug, we will use dynamic programming. (Read sections 15.1 for an introduction to this technique and 15.4 for the problem.) Dynamic programming is a powerful algorithmic paradigm that forms the core computational engine of many programs, including BLAST(the sequence alignment program almost universally used by molecular biologist in their experimental work). The key idea of dynamic programming is to break a large computational problem up into smaller subproblems, store the answers to those smaller subproblems, and, eventually, using the stored answers to solve the original problem. This avoids recomputing the same quantity over and over again. Specifically, we maintain an array, say c[i][j], that contains a table (or cache) of the solutions to all of the subproblems that the recursive function has already solved. The recursive function computes and fills in the appropriate table entry when it is presented with a new subproblem. However, when the function is presented with a previously solved subproblem, it simply looks up the appropriate value in the table and returns it.Finding the alignment itself.The above procedure above indicates how to compute the value of the optimal alignment. We now describe how to find the optimal alignment itself. In order to reconstruct the optimal alignment, we maintain a character matrix, say bl[i][j], to keep track of where the minimum value for aligning x[i..M] with y[j..N] came from. For example, if the minimum came from aligning x[i] with y[j] (in which case we solved the subproblem c(i+1, j+1), then we can record this fact by drawing an arrow from (i, j) to (i+1, j+1). We can obtain a crude ASCII picture of such an arrow by storing one of the three characters '\', '-', or '|' into b[i][j]. We interpret the three symbols as arrows emanating from (i, j) and terminating at (i+1, j+1), (i+1, j), and (i, j+1), respectively. For the example above, we get the the following solution matrix:5 T \ \ \ \ \ \ \ | |6 T \ \ \ \ \ \ \ | |7 A - \ \ \ \ \ | \ |8 C \ \ \ \ \ \ \ \ |9 C - - - - - - \ \ |10 - - - - - - - - - .Note that all arrows point from top to bottom and left to right. In order to reconstruct the alignment, we follow the arrows from the upper left corner c[0][0] until we arrive at the lower right corner c[M][N]. When we encounter '-', we insert a gap in x; when we encounter '|', we insert a gap in y; and, when we encounter '\', we align the two characters. The optimal alignment is the second candidate alignment in the edit-distance section.Input and output.Read the two input strings from standard input, one per line. Print the edit-distance to standard output. If both strings have length at most 40, also print out a table of optimal values, optimal choices, and an optimal alignment. Test your program using the example provided above, as well as the genomic data sets from GenBank.Analysis.Estimate the running time and memory usage of your program as a function of the lengths of the two input strings M and N.实验类型:Synthesis适用对象:Undergraduate for Computer School。