Linux下的Raid监控设置
不用软驱,在CentOS linux上也能安装RAID驱动程序

自上次RAID安装失败后,我另外购买了一块adapter sata raid 2410sa 卡,准备测试四块机器安装RAID5.环境如下:主板:Inter Server S5000VSACPU:xeon 四核5405*2内存:16G硬盘:4块西部数据500GSATARAID: 主板自带RAID0系统:Centos5.3 64位遗憾的是,这次RAID5还是没有达成,原因是官方没有提供centos5 64位的驱动,只是实现了RAID0.不过,倒是掌握了不用软驱,也能安装RAID驱动程序的办法,想想前几天还专门购买了一个软驱,真是亏啊。
办法很简单,上次其实提到过,如下:1) 创建RAID,这一步,我就不讲相信大家都会。
2) 启动Centos安装,并且将驱动程序复制到你的移动硬盘里(注意最好是第一盘符),直接IMG文件就可以了。
3) 在安装的第一个界面,输入linux nostorage4) 进入安装过程中,一直看到“Add device” 按钮.5) 点击“Add Device”,出现一系列的驱动6) 按F2,就跳出选择软盘,或者移动硬盘7) 我们选择移动硬盘,找到驱动程序文件,一般是IMG文件,选中后再点OK按钮。
8 ) 这时会回到刚才看到的驱动程序列表界面9) 选中刚才加进来的驱动,建议大家记住自己的驱动型号,厂商等信息,以便快速定位。
11) 点击OK12) 驱动程序就被加载,并出现在新增加设置列里13) 点击Done14) 继续安装,完成了。
这次还测试了intel S5000VSA自带的RAID安装RAID10,发现就算安装了驱动,能够顺利安装完,但是重新启动就会有问题,与上次一样,attempt to access beyond end of devicesda: rw=0, want=1953278938, limit=976773168Buffer I/O error on device sda2, logical block 1952877312attempt to access beyond end of devicesda: rw=0, want=1953278939, limit=976773168Buffer I/O error on device sda2, logical block 1952877313attempt to access beyond end of devicesda: rw=0, want=1953278940, limit=976773168Buffer I/O error on device sda2, logical block 1952877314attempt to access beyond end of devicesda: rw=0, want=1953278941, limit=976773168Buffer I/O error on device sda2, logical block 1952877315attempt to access beyond end of devicesda: rw=0, want=1953278942, limit=976773168Buffer I/O error on device sda2, logical block 1952877316attempt to access beyond end of devicesda: rw=0, want=1953278943, limit=976773168Buffer I/O error on device sda2, logical block 1952877317attempt to access beyond end of devicesda: rw=0, want=1953278944, limit=976773168Buffer I/O error on device sda2, logical block 1952877318attempt to access beyond end of devicesda: rw=0, want=1953278945, limit=976773168Buffer I/O error on device sda2, logical block 1952877319attempt to access beyond end of devicesda: rw=0, want=1953278938, limit=976773168Buffer I/O error on device sda2, logical block 1952877312由此,我判断是自带的RAID不支持,4块500G硬盘构成的将近1T的容量,其实还是觉得奇怪,可事实如此,哎.除非这块主板有问题。
Unix,Linux 磁盘 IO 性能监控命令

Unix/Linux 磁盘I/O 性能监控命令磁盘I/O 性能监控指标和调优方法在介绍磁盘I/O 监控命令前,我们需要了解磁盘I/O 性能监控的指标,以及每个指标的所揭示的磁盘某方面的性能。
磁盘I/O 性能监控的指标主要包括:指标1:每秒I/O 数(IOPS 或tps)对于磁盘来说,一次磁盘的连续读或者连续写称为一次磁盘I/O, 磁盘的IOPS 就是每秒磁盘连续读次数和连续写次数之和。
当传输小块不连续数据时,该指标有重要参考意义。
指标2:吞吐量(Throughput)指硬盘传输数据流的速度,传输数据为读出数据和写入数据的和。
其单位一般为Kbps, MB/s 等。
当传输大块不连续数据的数据,该指标有重要参考作用。
指标3:平均I/O 数据尺寸平均I/O 数据尺寸为吞吐量除以I/O 数目,该指标对揭示磁盘使用模式有重要意义。
一般来说,如果平均I/O 数据尺寸小于32K,可认为磁盘使用模式以随机存取为主;如果平均每次I/O 数据尺寸大于32K,可认为磁盘使用模式以顺序存取为主。
指标4:磁盘活动时间百分比(Utilization)磁盘处于活动时间的百分比,即磁盘利用率,磁盘在数据传输和处理命令(如寻道)处于活动状态。
磁盘利用率与资源争用程度成正比,与性能成反比。
也就是说磁盘利用率越高,资源争用就越严重,性能也就越差,响应时间就越长。
一般来说,如果磁盘利用率超过70%,应用进程将花费较长的时间等待I/O 完成,因为绝大多数进程在等待过程中将被阻塞或休眠。
指标5:服务时间(Service Time)指磁盘读或写操作执行的时间,包括寻道,旋转时延,和数据传输等时间。
其大小一般和磁盘性能有关,CPU/ 内存的负荷也会对其有影响,请求过多也会间接导致服务时间的增加。
如果该值持续超过20ms,一般可考虑会对上层应用产生影响。
指标6:I/O 等待队列长度(Queue Length)指待处理的I/O 请求的数目,如果I/O 请求压力持续超出磁盘处理能力,该值将增加。
Linux命令高级技巧使用mdadm管理软件RAID

Linux命令高级技巧使用mdadm管理软件RAIDRAID(冗余磁盘阵列)是一种数据存储技术,通过将多个磁盘组合在一起,提供数据冗余和性能增强。
在Linux系统中,我们可以使用mdadm(多磁盘和设备管理器)命令来管理软件RAID。
本文将介绍一些高级技巧,帮助您更好地使用mdadm来管理软件RAID。
1. 安装mdadm在开始之前,您需要确保系统中已经安装了mdadm。
如果尚未安装,可以使用以下命令进行安装:```sudo apt-get install mdadm```2. 创建软件RAID使用mdadm命令可以创建各种类型的软件RAID,包括RAID 0、RAID 1、RAID 5和RAID 6等。
以下是创建RAID 1(镜像)的示例:```sudo mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sdb1/dev/sdc1```上述命令将创建一个名为/md0的RAID设备,使用/dev/sdb1和/dev/sdc1两个磁盘进行镜像。
3. 添加和移除磁盘在创建RAID后,您可以随时添加或移除磁盘。
以下是添加磁盘的示例:```sudo mdadm --add /dev/md0 /dev/sdd1```上述命令将磁盘/dev/sdd1添加到RAID设备/md0中。
如果需要移除磁盘,可以使用以下命令:```sudo mdadm --fail /dev/md0 /dev/sdd1sudo mdadm --remove /dev/md0 /dev/sdd1```第一条命令将磁盘标记为失败状态,第二条命令将其从RAID设备中移除。
4. 磁盘替换当一个磁盘故障时,您需要将其替换为新的磁盘。
以下是磁盘替换的示例:sudo mdadm --remove /dev/md0 /dev/sdd1sudo mdadm --add /dev/md0 /dev/sde1```上述命令将故障的磁盘/dev/sdd1从RAID设备/md0中移除,并将新磁盘/dev/sde1添加到RAID设备中。
查看linux服务器的Raid配置

查看linux服务器的Raid配置有些情况下Linux服务器系统不是自己装好的,raid也不是自己配置的,远程登录系统后可能就不知道系统是否有做raid,raid级别多少?因此在这里稍微总结一下Linux下查看软、硬raid信息的方法。
软件raid:只能通过Linux系统本身来查看cat /proc/mdstat可以看到raid级别,状态等信息。
硬件raid:最佳的办法是通过已安装的raid厂商的管理工具来查看,有cmdline,也有图形界面。
如Adaptec公司的硬件卡就可以通过下面的命令进行查看:# /usr/dpt/raidutil -L all可以看到非常详细的信息。
当然更多情况是没有安装相应的管理工具,只能依靠Linux本身的话一般我知道的是两种方式:# dmesg |grep -i raid# cat /proc/scsi/scsi显示的信息差不多,raid的厂商,型号,级别,但无法查看各块硬盘的信息。
另外Dell的服务器可以通过命令来显示,而HP、IBM等的服务器通过上面的命令是显示不出的。
只能够通过装硬件厂商的管理工具来查看。
另:软raid有工具 mdadm可供查看:[root@test]# mdadm --helpmdadm is used for building, managing, and monitoring Linux md devices (aka RAID arrays)Usage: mdadm --create device options...Create a new array from unused devices.mdadm --assemble device options...Assemble a previously created array.mdadm --build device options...Create or assemble an array without metadata.mdadm --manage device options...make changes to an existing array.mdadm --misc options... devicesreport on or modify various md related devices.mdadm --grow options deviceresize/reshape an active arraymdadm --incremental deviceadd/remove a device to/from an array as appropriatemdadm --monitor options...Monitor one or more array for significant changes.mdadm device options...Shorthand for --manage.Any parameter that does not start with '-' is treated as a device nameor, for --examine-bitmap, a file name.The first such name is often the name of an mddevice. Subsequentnames are often names of component devices.For detailed help on the above major modes use --help after the modee.g.mdadm --assemble --helpFor general help on options usemdadm --help-options。
浅析LINUX之RAID管理

浅析LINUX之RAID管理1引言在存储技术飞速发展的今天,RAID技术为系统带来的存储高性能和数据高可靠是有目共睹的。
经过了十几年发展的Linux操作系统现已进入更具理性、更重实效的应用时代,如何在Linux系统中高效有序地管理各种RAID设备成为人们越来越关注的主题之一。
2RAID概述RAID(Redundant Array of Independent Disks)术语最早是由加州大学Berkeley分校于20世纪80年代提出,后被存储业界大力推广和研究,开发出为数众多的RAID产品,在以后的发展中,又加入了新的分级,成为现今最流行的存储标准。
常用的RAID级别有:RAID0、RAID1、RAID3、RAID4、RAID5、RAID6、RAID10、RAID50、Linear Mode、JBOD等。
造成RAID流行的三个主要原因:●RAID在容量和管理上的优势RAID系统可以组合多个单盘,而呈现在系统中的可以是单一的地址或LUN,不占用更多的系统总线插槽,还能解决RAID出现之前不得不将应用扩展到多个服务器而造成的管理困难和增加失效几率等问题。
●RAID的性能优势RAID的一个最重要的概念是磁盘分条。
其思想是:通过将I/O操作分散到所有成员磁盘中,使主机I/O控制器能够处理更多的操作,这是在单个磁盘驱动器下所不能达到的。
[1]●RAID的可靠性和可用性优势由于采用了冗余算法,可以保证:即使在个别磁盘失效的情况下,数据仍能维持一致性。
常用的冗余算法包括镜像和校验。
校验算法是利用“异或”操作之逆操作是其本身的特点,来实现数据保护的功能。
如下所示。
A⊕ B ⊕ C = D => A ⊕ B ⊕ D = C假设A、B、C为分条数据,D为校验数据。
当C所在的磁盘失效时,可利用剩余分条数据A、B和校验数据D重新生成数据C,系统并未因盘坏而导致数据丢失,仍可继续工作,但处于降级状态(Degraded)。
Linux下系统如何监控服务器硬件、操作系统、应用服务和业务

Linux下系统如何监控服务器硬件、操作系统、应⽤服务和业务1.Linux监控概述Linux服务器要保证系统的⾼可⽤性,需要实时了解到服务器的硬件、操作系统、应⽤服务等的运⾏状况,各项性能指标是否正常,需要使⽤各种LINUX命令。
做到⾃动化运维就需要,将上述各项监控指标在同⼀个软件中展显出来,图形化监控,消息报警机制,⽇志检看,资产管理等等2.Linux监控的对象2.1 硬件监控(1)服务器:如电源,风扇,磁盘,CPU等,可以使⽤IPMI监控,在LINUX下安装IPMITOOL不同的服务器⼚商都在服务器上配有远程控制卡BMC: 如DELL(iDRAC) ,IBM (IMM) ,HP(ILO)LINUX下只需安装:#yum install -y OpenIPMI ipmitool 这⼆个⼯具就可以IPMI命令可以在服务器本地运⾏,也可以通过⽹络远程调⽤,IPMI在服务器上可以配置单独的IP地址和访问密码(2)⽹络设备:交换机,防⽕墙,路由器等,使⽤SNMP进⾏监控在被监控的设备上开启SNMP代理,到时可以通过⼯具进⾏获取数据,如ZABBIX1.LINUX上安装#yum list |grep snmp#yum install -y net-snmp net-snmp-utils安装好后要配置snmpd.conf⽂件rocommunity snmptest 172.16.20.89 #172.16.20.89表⽰仅这IP地址才可以来访问snmp信息#systemctl start snmpd 启动SNMP ,netstat -nulp ,netstat -ntlp 查看snmp启来的端⼝udp=161 ,TCP=199通过SNMP命令可以获取监控信息:#snmpget -v2c -c snmptest 172.16.20.89 1.3.6.1.2.1.1.3.0 #1.3.6.1.2.1.1.3.0为OID2.交换机上开启snmp-server community public ro(3)定期机房巡检,查看设备运⾏情况2.2 操作系统监控安装sysstat⼯具,包括了iostat、vmstat、sar、mpstat、nfsiostat、pidstat (yum install -y sysstat #rpm -ql sysstat)(1)CPU (CPU调度上下⽂切换,运⾏队列负载,CPU使⽤率)确定服务类型:IO密集型(如:数据库),CPU密集型(如:WEB)1.cpu利⽤率内核态: 30%和⽤户态:70%2.cpu运⾏队列:1~3线程 1CPU=4核队列不超过12个3.上下⽂切换:尽量少,结合cpu利⽤率4.#top命令(显⽰CPU和内存信息,M按内存使⽤率排序,P按CPU使⽤率排序,Q退出)CPU百分⽐各项指标: us:⽤户态 sy:内核态 ni:进程间优先级更换 id:空闲 wa:IO等待 hi:硬中断 si:软件中 st:虚拟5.CPU监控的各种命令:top ,vmstat , mpstat, uptime ,ps cpu进程情况,pstree 以树形结构显⽰进程之间的关系(2)内存1. free -m :显⽰内存信息2.vmstat :来监控虚拟内存 #vmstat 1 10 每隔1秒共10次获取监控信息(3)磁盘1.iostat:命令⽤来显⽰存储⼦系统的详细信息,通常⽤它来监控磁盘 I/O 的情况。
Linux下Raid配置详细过程(图文)
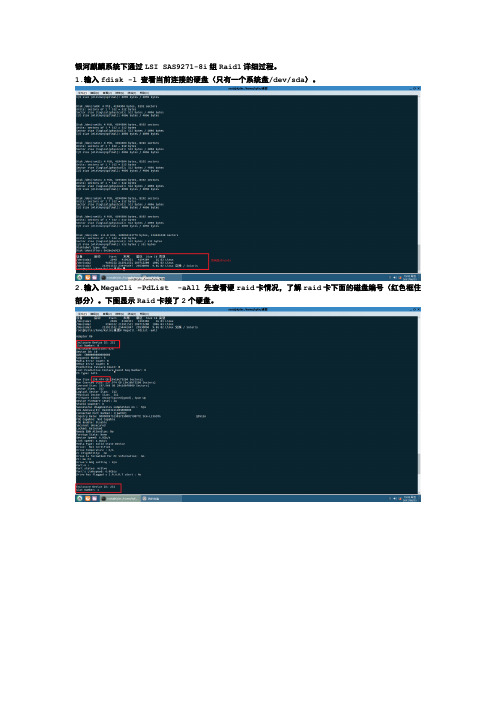
银河麒麟系统下通过LSI SAS9271-8i组Raid1详细过程。
1.输入fdisk -l 查看当前连接的硬盘(只有一个系统盘/dev/sda)。
2.输入MegaCli –PdList -aAll 先查看硬raid卡情况,了解raid卡下面的磁盘编号(红色框住部分)。
下图显示Raid卡接了2个硬盘。
3.输入命令“MegaCli –CfgLdAdd –r1 [252:0, 252:1] Direct –a0”将当前Raid卡上的2个硬盘组成Raid1。
4.使用命令“MegaCli –CfgDsply -a0”查看配置后的RAID信息。
如下图红色部位显示当前的Raid类型为Raid1。
4.使用命令“MegaCli -LdInit -start –full -l0 -a0”初始化Raid。
5.使用命令“MegaCli -LdInit –showprog -l0 -a0”查看初始化进度。
6.初始化完成后在系统设备节点下新增一设备 /dev/sdb,即为当前创建成功的Raid1。
7.通过命令“fdisk /dev/sdb”来创建分区,通过mount /dev/sdb /mnt 挂载设备。
注意:
创建Raid时如果遇到“the specified physical disk does not have the
appropriate attributes to。
”
1.执行MegaCli –PDMakeGood –PhysDrv ‘[252:0,252:1]’ –Force –aAll (清除硬盘
为Good状态)。
Linux命令行中的系统监控和报警技巧

Linux命令行中的系统监控和报警技巧Linux作为一种稳定可靠的操作系统,在服务器和大型计算机系统中被广泛使用。
对于管理员来说,有效监控系统的健康状况,并在出现问题时迅速报警是非常重要的。
本文将介绍一些在Linux命令行下实现系统监控和报警的技巧,帮助管理员更好地管理和维护系统。
1. 基础系统监控指标为了及时发现系统性能问题,我们首先需要了解一些基础的系统监控指标。
下面是一些常用的命令行工具,可以获取这些指标的信息:1.1 top:显示当前系统中运行的进程列表和系统资源的使用情况,如CPU、内存和磁盘等。
1.2 mpstat:查看系统的CPU使用情况,包括每个核心的负载和闲置时间。
1.3 free:用于显示系统内存的使用情况。
1.4 df:查看磁盘使用情况和可用空间。
1.5 iostat:用于监控系统磁盘和I/O设备的使用情况。
通过使用这些命令,管理员可以定期检查系统的运行状态,及时发现资源瓶颈和异常情况。
2. 高级系统监控技巧除了基础的系统监控指标外,Linux还提供了一些高级的监控技巧,帮助管理员更全面地了解系统的运行情况。
2.1 sar:System Activity Reporter(系统活动报告器)是一个强大的系统性能监控工具,可以收集CPU、内存、磁盘、网络和I/O等方面的数据,并生成报告供管理员分析。
使用sar命令,管理员可以查看历史数据,分析系统的使用模式和趋势,并根据需要调整系统配置。
2.2 vmstat:用于监控系统的虚拟内存、进程、CPU利用率和I/O等信息。
通过使用vmstat命令,管理员能够快速了解系统的性能状况,实时监控系统的各项参数。
2.3 netstat:用于监控网络连接和网络统计信息。
管理员可以使用netstat命令查看当前连接到系统的网络服务和端口,以及网络流量的情况。
除了上述命令外,还有一些其他的工具和技术可以用于系统监控,如nmap、iftop、htop等。