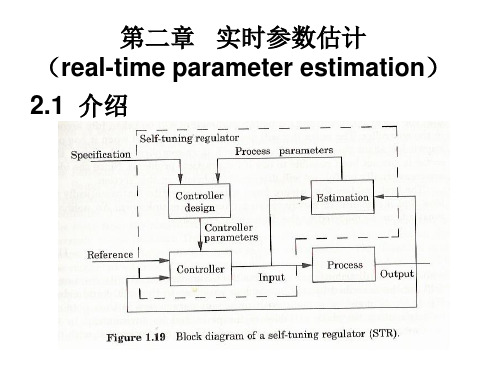
第二章 实时参数估计—2-5-2
应用统计学第二章参数估计精品PPT课件

第1页
第二章 参数估计
• 总体分布中常含有参数,一般常用 表示参
数,参数估计问题就是从样本出发构造一些 统计量作为某些未知参数的估计量。通常都 是对总体的期望和方差进行估计
• 参数估计的形式有两种:点估计与区间估计。
第二章 参数估计
第2页
• 设 X1, X2,…, Xn 是来自总体 X 的一个样本,我
(2)样本信息:抽取样本所得观测值提供的信息。
(3)先验信息:人们在试验之前对要做的问题在经 验上和资料上总是有所了解的,这些信息对 统计推断是有益的。先验信息即是抽样(试 验)之前有关统计问题的一些信息。一般说 来,先验信息来源于经验和历史资料。先验 信息在日常生活和工作中是很重要的。
第二章 参数估计
设总体的分 f(x布 ;) 密 2x 度 e x2,为 x0
0, x0
求 的极大似然估计量,它是否是无偏的,一致
的估计量?
第二章 参数估计
第37页
(四) 均方误差
无偏估计不一定比有偏估计更优。 评价一个点估计的好坏一般可以用:点估计值 ˆ
与参数真值 的距离平方的期望,这就是下式给
出的均方误差
第二章 参数估计
第5页
例.1 对某型号的20辆汽车记录其每加仑汽油的行 驶里程(km),观测数据如下:
29.8 27.6 28.3 27.9 30.1 28.7 29.9 28.0 27.9 28.7 28.4 27.2 29.5 28.5 28.0 30.0 29.1 29.8 29.6 26.9
1
2
2
n
(xi
i1
)2
ln
L(,
2)
1
2
2
自适应控制第2章.详解
1 2 n
(φ ) (Y φ θ1 φ θ2 φ θn ) 0, i 1,t
i T 1 2 n
最小二乘的统计解释(statistical interpretation)
y(i) φ (i)θ e(i)
T 0
(2.12)
ˆ(t ) θ ˆ(t 1) θ
φ(t ) T ˆ(t 1) y ( t ) φ ( t ) θ T φ (t )φ(t )
(2.23)
Kaczmarz算法
ˆ(t ) θ ˆ(t 1) θ γφ(t ) T ˆ(t 1) y ( t ) φ ( t ) θ φT (t )φ(t )
t
新的采样数据对参数估计的改进不再起作用, 这种现象称为数据饱和。
时变参数情形
1、参数突变但不频繁 重置(resetting)
2、参数连续变换但很缓慢
1 t i T V (θ , t ) λ y (i) φ (i)θ 2 i1
0 λ 1
t
2
(2.20)
遗忘因子(折扣因子) forgetting(discounting) factor
φn (1) ε (1) y (1) φ1 (1) φ ( 2) ε ( 2) y ( 2 ) φ ( 2 ) 1 θ1 n θn ε (t ) y (t ) φ1 (t ) φn (t )
T
1
ˆ θ (t ) P(t ) φ(i ) y (i ) i1
《参数估计方法》课件

目录
• 参数估计方法概述 • 点估计 • 区间估计 • 最大似然估计法 • 最小二乘估计法 • 贝叶斯估计法
01
参数估计方法概述
参数估计方法的定义
参数估计方法的定
义
参数估计方法是一种统计学中的 方法,它通过分析样本数据来估 计未知的参数值。这些参数可以 描述总体特性的程度,如平均值 、方差等。
使得它容易进行统计推断。
最小二乘估计法的应用场景
线性回归分析
最小二乘估计法是线性回归分析中最常用的 参数估计方法,用于预测一个因变量与一个 或多个自变量之间的关系。
时间序列分析
在时间序列分析中,最小二乘估计法可用于拟合和 预测时间序列数据,例如ARIMA模型。
质量控制
在质量控制中,最小二乘估计法可用于拟合 控制图,以监测过程的稳定性和预测异常情 况。
区间估计
区间估计是一种更精确的参数估计方法,它给出未知参数的一个置信区间,即有较大的把握认为未知参数落在这个区 间内。例如,用样本均值和标准差来估计总体均值的置信区间。
贝叶斯估计
贝叶斯估计是一种基于贝叶斯定理的参数估计方法,它根据先验信息和样本数据来推断未知参数的后验 概率分布。贝叶斯估计能够综合考虑先验信息和样本数据,给出更加准确的参数估计结果。
贝叶斯估计法的性质
01
02
03
贝叶斯估计法是一种主观概率估 计方法,因为它依赖于先验信息 的可信度和准确性。
先验信息的不确定性可以通过引 入一个先验分布来表达,该分布 描述了先验信息中未知参数的可 能取值及其概率。
贝叶斯估计法的后验概率分布可 以用于推断未知参数的估计值和 不确定性程度。
贝叶斯估计法的应用场景
3
参数估计课件讲解

置信区间
置信下限
置信上限
13
(3)置信水平:如果我们将构造置信区间的步骤重 复多次,置信区间中包含总体参数真值的次数所 占的比率,称为置信水平。
在构造置信区间时,我们可以用所希望的值作为
置信水平。比较常用的置信水平是:90%,95% 和99%,通常用 1- 表示置信水平,其中 称 为显著性水平。
由抽样平均误差
mx =
s = 1.5 =0.15(小时) n 10
D x = zm= 1.96? 0.15 0.29(4 小时)
\ x - 0.294 #X x + 0.294,即3.706 #X 4.294
因此,以95%置信度,估计该地区内居民每天
看电视的平均时间在3.706到4.294个小时之间。
18
4. F(z)、 z、 Δ、μ之间的关系
F(z)与z具有一一对应的关系,所以已知概率 保证程度F(z)就可以求出概率度z ;若已知z 也就可以知道F(z)。
给定F(z) z Δ = z×μ
样本 μ 和总体参数的点估计值
m= s n
给定Δ
抽样平均误差
Δ/μ= z
F(z)
19
5.区间估计的特点
(1)指出总体被估计参数的上限和下限, 即指出总体参数的可能范围,而不是直 接给出总体参数的估计值。
14
两个需要注意的问题
如果用某种方法构造的所有区间中有95%的 区间包含总体参数的真值,5%的区间不包含 总体参数的真值,那么,用该方法构造的区 间称为置信水平为95%的置信区间。
置信区间是一个随机区间,它会因样本的不 同而不同,而且不是所有的区间都包含参数 真值。
15
2.抽样误差汇总
第二章 多元正态分布及参数的估计

27
北大数学学院
第二章 多元正态分布及参数的估计
§2.2 多元正态分布的定义与基本性质—简单例子
y BxB
0 0 1
1 0 0
100 110
1 2 0
003 100
0 0 1
1 0 0
1 0 1
2 0 1
003 100
2
北大数学学院
第二章 多元正态分布及参数的估计
目录
§2.1 随机向量 §2.2 多元正态分布的定义与
基本性质
§2.3 条件分布和独立性 §2.4 随机矩阵的正态分布 §2.5 多元正态分布的参数估计
3
北大数学学院
第二章 多元正态分布及参数的估计
§2.1 随 机 向
本课程所讨论的是多变量总体.把 p个随机变量放在一起得
第二章 多元正态分布及参数的估计
§2.2 多元正态分布性质2的推论
例2.1.1
f (x1, x2
()X1,X212)的e联 12合( x12密 x22度) [1函数x为1 x2e
1 2
(
x12
x22
)
]
我们从后面将给出的正态随机向量的联合密
度函数的形式可知, (X1,X2)不是二元正态随机向 量.但通过计算边缘分布可得出:
本节有关随机向量的一些概念(联合分布, 边缘分布,条件分布,独立性;X的均值向量,X 的协差阵和相关阵,X与Y的协差阵)要求大家 自已复习.
三﹑ 均值向量和协方差阵的性质 (1) 设X,Y为随机向量,A,B为常数阵,则
E(AX)=A·E(X) E(AXB)=A·E(X)·B
6
应用多元统计分析课后习题答案高惠璇(第二章部分习题解答

2
x12
22
x1
65
x12
14
x1
49)
1 2
(
x2
x1
7)2
e e dx2
2
1 e
1 2
(
x12
8
x1
16)
2
1
2
e dx
1 2
(
x2
x1
7
)
2
2
1 e
1 2
(
x1
4
)
2
2
X1 ~ N(4,1).
类似地有
f2 (x2 ) f (x1, x2 )dx1
1
e
1 4
(
x2
3)2
注意:由D(X)≥0,可知 (Σ1-Σ2) ≥0.
8
第二章 多元正态分布及参数的估计
2-11 已知X=(X1,X2)′的密度函数为
f
( x1 ,
x2 )
1
2
exp
1 2
(2 x12
x22
2 x1 x2
22 x1
14 x2
65)
试求X的均值和协方差阵.
解一:求边缘分布及Cov(X1,X2)=σ12
应用多元统计分析
第二章部分习题解答
第二章 多元正态分布及参数的估计
2-1 设3维随机向量X~N3(μ,2I3),已知
002,
A
0.5 0.5
1 0
00.5.5, d 12.
试求Y=AX+d的分布.
解:利用性质2,即得二维随机向量Y~N2(y,y),
其中:
2
第二章 多元正态分布及参数的估计
2-2 设X=(X1,X2)′~N2(μ,Σ),其中
应用统计方法第二章参数估计
2
1 1
2 x 1 1
2 2
2 dx
1 12
(
2
1 ) 2
令
X
S 2
1 2
(1
2
)
1 12
( 2
1)
解上述关于
1
,
2
的方程得
1 2
X X
3S 3S
8
.
Example 2.4 贝努利试验中,事件 A 发生的频率是该事件 发生概率的矩法估计。 Solution 此处,实际上我们视总体 X 为“唱票随机变量”, 即 X 服从两点分布:
此,必须采用求极值的办法,即对对数似然函数关于 i 求导, 再令之为 0,即得
ln L( ) i
(Xi
X )2
S2
记为ˆ 2 S 2 .第三步等号再一次用到习题 1.4.
7
.
Example 2.3 设 X 为[1, 2 ]上的均匀分布, X1, X 2 ,, X n
为样本,求1, 2 的矩估计。
Solution
a 1
2 xdx
1 2 1
2 2
12
2( 2 1 )
1 2
(
1
2)
2
.
Chapter 2 参数估计
(Parameter Estimation)
1
.
§2.1 点估计(Point Estimation) §2.2 估计量的评价准则 §2.3 区间估计(Interval Estimation)
2
.
§2.1 点估计(Point Estimation)
一、 矩估计法
若总体 X 的期望存在,E(X ) , X1, X 2 ,, X n 是出 自X 的样本,则由柯尔莫哥洛夫强大数定律,以
应用数理统计第二章
□
例2.1.11 总体 X ~ U (θ,θ +1) , θ 是未知参数, X1,…,Xn 是一组样本,求θ 的极大似然估计。 解. 总体的密度函数为: f(x,θ ) = 1, θ < x1,…,xn < θ +1 显然不能对参数 θ 求导,无法建立似然方程 注意到这个似然函数不是 0 就是 1 ,利用 顺序统计量,把似然函数改写成如下形式:
f(x,θ ) = 1, θ < x(1) <… < x(n) < θ +1 因此只要 θ < x(1) 并且 x(n) < θ +1 同时满足, 似然函数就可以达到极大值 1 。 所以 U (θ,θ +1) 中参数θ 的极大似然估计 可以是区间 ( x(n) - 1 ,x(1) ) 里的任意一个点 。 说明 MLE 可以不唯一,甚至有无穷多个 同理,总体 U (a,b) 左右端点 a 、b 的MLE 分别就是两个极值统计量 x(1) 、x(n) 。
k =1
n
注意这里总体参数 θ 是一个向量 (µ,σ2 ) , 因此对于似然函数取对数后分别对 µ,σ2 求导, 建立对数似然方程组:
1
σ
−
2
(x − µ) = 0 n + 1 2(σ 2 )2 ( xk − µ )2 = 0 ∑
k =1 n
2σ 2
解方程组得到正态总体两个参数的MLE
ˆ µ=X
1 n n−1 2 ˆ σ 2 = ∑ ( X k − X )2 = S n k =1 n
⎛ N ⎞ ∑ xk nN − ∑ xk L ( x ,θ ) = [ ∏ ⎜ ⎟ ] p (1 − p ) ⎝ xk ⎠
这里每一个 xk = 0、1、…、N 中的某个值
参数估计 教学PPT课件
• 2.极大似然估计法
•(1)写出总体X的分布律或密度函数f(x,θ)
•(2)写出Biblioteka 然函数L( x1,n
, xn, ) f (xi , )
i 1
•(3)对似然函数取对数 ln L(x1,, xn , )
•(4)对 ln L(x1,, xn , ) 求导得似然方程
•(5)解似然方程,得极大似然估计量
(n
1))
又 X ?, S ? n 16, 0.1, t1 2 (n 1) ?
区间估计例题
• 例2:从自动机床加工的同类产品中随 机抽取16件,测得长度值为:12.50, 12.12,12.01,12.28,12.09,12.16, 12.03,12.01,12.06,12.13,12.07, 12.11,12.08,12.01,12.03,12.06,
0.90的置信区间:
(1)如果已知σ=0.01 (2)如果σ未知
区间估计例题
解:(1)σ=0.01已知,a的置信度为1-α的置
信区间为
0.01 ( X n u1 2 )
又 X ?, n 16, 0.1, u1 2 1.645
(2)σ未知,a的置信度为1-α的置信区间为
(X
S n
1
t1
2
ˆ ˆ(X1,, X n )
极大似然估计法例题
例1:设总体X~(0-1)分布,求p的极大似然估计.
解:总体X的分布律 P(X x) px (1 p)1x, x 0,1
似然函数 取对数
n
L( p) pxi (1 p)1xi pnx (1 p)nnx i 1
ln L( p) nx ln p (n nx) ln(1 p)
设产品长度X~N(a,σ2). 求σ2的置信区间(α=0.05)
计量经济学 第二章 一元线性回归模型
计量经济学第二章一元线性回归模型第二章一元线性回归模型第一节一元线性回归模型及其古典假定第二节参数估计第三节最小二乘估计量的统计特性第四节统计显著性检验第五节预测与控制第一节回归模型的一般描述(1)确定性关系或函数关系:变量之间有唯一确定性的函数关系。
其一般表现形式为:一、回归模型的一般形式变量间的关系经济变量之间的关系,大体可分为两类:(2.1)(2)统计关系或相关关系:变量之间为非确定性依赖关系。
其一般表现形式为:(2.2)例如:函数关系:圆面积S =统计依赖关系/统计相关关系:若x和y之间确有因果关系,则称(2.2)为总体回归模型,x(一个或几个)为自变量(或解释变量或外生变量),y为因变量(或被解释变量或内生变量),u为随机项,是没有包含在模型中的自变量和其他一些随机因素对y的总影响。
一般说来,随机项来自以下几个方面:1、变量的省略。
由于人们认识的局限不能穷尽所有的影响因素或由于受时间、费用、数据质量等制约而没有引入模型之中的对被解释变量有一定影响的自变量。
2、统计误差。
数据搜集中由于计量、计算、记录等导致的登记误差;或由样本信息推断总体信息时产生的代表性误差。
3、模型的设定误差。
如在模型构造时,非线性关系用线性模型描述了;复杂关系用简单模型描述了;此非线性关系用彼非线性模型描述了等等。
4、随机误差。
被解释变量还受一些不可控制的众多的、细小的偶然因素的影响。
若相互依赖的变量间没有因果关系,则称其有相关关系。
对变量间统计关系的分析主要是通过相关分析、方差分析或回归分析(regression analysis)来完成的。
他们各有特点、职责和分析范围。
相关分析和方差分析本身虽然可以独立的进行某些方面的数量分析,但在大多数情况下,则是和回归分析结合在一起,进行综合分析,作为回归分析方法的补充。
回归分析(regression analysis)是研究一个变量关于另一个(些)变量的具体依赖关系的计算方法和理论。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5.算法框图 终判:
6.递推最小二乘法(RLS)的特点
T ˆ θˆN +1 = θˆN + K N +1 y N +1 − ϕ N +1θ N
ˆ = 0, P = 106 I , y , u 置初值, θ 0 0 0 0
1) 预先决定结束辨识 1→N 的总递推步数。 构成 ϕ N 计算K N , PN 2) 绝对误差 θˆN−θˆN −1 < ε 采样 y N , uN 相对误差
2-5 线性参数模型最小二乘辨识
2-5 线性参数模型最小二乘辨识
六、递推最小二乘估计(RLS) 一次完成算法需要计算机存储全部测量数据, 占用的存储单元较多 在已知1~N 由 Y = Φθ + e 构成 YN , Φ N 求出θˆN 共N组数据后
基本思路:
θˆN +1 = θˆN + 修正项
一次完成算法:每取得一次新数据要重新计算, 计算量大,且没有实时能力。 递推LS法:取得一次数据,估计一次参数。
(
)
−1
B T A −1
2-5 线性参数模型最小二乘辨识
3.递推公式 −1 T 对 P N + 1 = ( PN− 1 + ϕ N + 1ϕ N +1 ) 由求逆引理(推论一),有
PN +1
T P ϕ +1ϕ N + 1 PN = PN − N N T 1 + ϕ N +1 PN ϕ N +1
将 ④PN +1 , ②Φ N +1 , ①YN +1 ,代入θˆN +1③
令 K N +1 =
PN ϕ N +1 T 1+ϕN + 1 PN ϕ N + 1
——卡尔曼增益阵
②
T T 则 θˆN +1 = ⎡ ⎣ PN − K N +1ϕ N +1 PN ⎤ ⎦ ( Φ N YN + ϕ N + 1 y N + 1 )
T T = PN Φ T N YN + PN ϕ N +1 y N +1 − K N +1ϕ N +1 PN Φ N YN
max
i
(
)
θˆ ( i ) 表明 ˆ 向量中的第i个分量 θ ε为精度要求的权
ˆ (i) ˆ ( i ) −θ θ N N +1 <ε θˆN +1 ( i )
计算 θˆ
1) 新的估计量 θˆN +1 先前一步 的估计量
N N+1→N
校正项
N
终判 Y ˆ 输出 θ N 停机
线性组合 构成递推公式
θˆN +1 = θˆN + 修正项
①
ˆ = ( ΦT Φ ) ΦT Y θ N +1 N +1 N +1 N +1 N +1
−1
2.递推最小二乘估计: 已取得N组数据 y1 , , y N , u1 , , u N T ⎡ϕ 1 ⎤ ⎡ y1 ⎤ ⎢ ⎥ ⎢ ⎥ ˆ = ( Φ T Φ ) −1 Φ T Y Φ = YN = ⎢ ⎥ θ N ⎢ ⎥ N N N N N T ⎥ ⎢ϕ N ⎢ ⎥ y ⎣ ⎦ ⎣ N⎦
(A
(
X −1 = Y ←⎯ ← 有⎯ XY = I
(
)
(
)
−1
− A−1B C −1 + DA−1B
(
)
−1
DA−1
)
= I + BCDA−1 − B I + CDA−1 B C −1 + DA−1 B
= I + BCDA−1 − B C−1 + DA−1B DA−1 − BCDA−1B C−1 + DA−1B DA−1
12/44
2
2-5 线性参数模型最小二乘辨识
2-5 线性参数模型最小二乘辨识
利用递推公式,可以在线实时估计 初值 θˆ0
T 构成 ϕ1 = [ y0
4.初值的确定: 递推时要已知初值 θˆ0 , P0 , 可用如下方法: 1) 取一批观测值 y0 , 用LS估计 θˆn , 计算 PN
, yn , u0 ,
)
=I
4/44
2-5 线性参数模型最小二乘辨识
2-5 线性参数模型最小二乘辨识
推论一:当D=BT有,
当又获得一组新的测量数据 y N + 1 , u N + 1 时,
−1
( A + BCB )
T
−1
= A −A B C +B A B
T
−1
(
−1
−1
)
−1
B A
T
−1
推论二:当C=I有,
( A + BD )
PN
则 PN + 1
(Φ
T N +1
Φ N +1 )
−1
⎧ ⎪ = ⎨ ΦT N ⎪ ⎩
(
ϕ N +1 ) ⎜ ⎜
⎛ Φ N ⎞⎫ ⎪ ⎟ T ⎟⎬ ⎪ ⎝ ϕ N +1 ⎠ ⎭
−1
( = (P
T = ΦT N Φ N + ϕ N + 1ϕ N + 1
−1 N T + ϕ N + 1ϕ N +1
)
−1
(
)(
)
为预报误差 或拟合误差
17/44
且不需进行矩阵求逆计算,存储量和计算量 大大降低了。
18/44
3
2-5 线性参数模型最小二乘辨识
2-5 线性参数模型最小二乘辨识
5) 先前数据一直起作用,是无限增长记忆算法。 y ,u θN ˆ ⎯⎯⎯⎯ → θ N +1
N +1 N +1
2.当随机干扰序列{ek}是白噪声时,若数据量 N→∞时,lim θˆN → θ N →∞
递推最小二乘估计实际上是对估计值不断修正的
T ˆ ˆN +1 = yN +1 − ϕN 过程,它把每一步的预报误差 ε +1θ N
ˆ ˆ + K N +1 yN +1 − ϕ θ =θ N
(
T N +1 N
)
预报误差
11/44
作为基本修正量,然后用卡尔曼增益阵 K N +1对基 本修正量进行适当调整以产生实际修正量。
ˆ = P ΦT Y θ N +1 N +1 N +1 N +1
③
9/44
ˆ θ N
T − K N +1ϕ N +1 PN ϕ N +1 y N +1
10/44
2-5 线性参数模型最小二乘辨识
将 θˆN = PN ΦT N YN 代入
KN +1 =
PNϕ N +1 T 1 + ϕN +1 PNϕ N +1
T N N
采样 y1 , u1
y2 , u2 ⎯⎯⎯ → θˆ2
ˆ P0 → K 1 → θ 1
un
−1
, u0
]
→ K 2 → P2 P1 ⎯⎯ ϕ2
yN +1
原有信息
ΦN +1 新观测值
2 6 2) 人为地给定 ˆ = 0, 或任意 P = α 2 I , α为充分大正数 θ 0 0
( Φ Φ ) , 分别取作 θˆ , P (一般取 α = 10 ∼ 10 )
2-5 线性参数模型最小二乘辨识
1.矩阵求逆引理:避免矩阵和求逆 设A、C和A+BCD或(C-1+DA-1B)非奇方阵,则
( A + BCD)
(A
−1
− A−1B C −1 + DA−1B
(
)
−1
DA−1
)
( )
−1
( A + BCD)
−1
= A − A B C + DA B
−1
−1
(
−1
−1
)
−1
ˆ +e Y = Φ θ + e → YN = Φ N θ N
获得一组新 的测量数据
由 yN+1, uN+1 构成 YN+1, ΦN+1
ˆ 算出 θ N+1
1/44
又取得一组数据 y N +1 , uN +1 ,
ˆ 有Y N + 1 , Φ 并算出 θˆN +1 N +1 ,
2/44
2-5 线性参数模型最小二乘辨识
(W . P .1) 是一致性估计。
ˆ = θ 是无偏的, Eθ 3.当N→∞时, N
PN
KN
PN +1
七、LS和RLS 1.从RLS推导过程可以看出,LS和RLS在数学上 是等价的,都是使残差平方和为最小进行推导的 , 在估计θˆ 时,不需对噪声序列{e }的概率特性有
2-5 线性参数模型最小二乘辨识
T ˆ θˆN +1 = θˆN + K N +1 y N +1 − ϕ N + 1θ N
ˆ = ⎡ P − K ϕ T P ⎤ ( ΦT Y + ϕ y ) θ N +1 N +1 N +1 N ⎦ N N N +1 N +1 ⎣ N
T ˆ ˆ −K ϕT θ =θ N +1 N +1 N + ( P Nϕ N +1 − K N +1ϕ N +1 PNϕ N +1 ) yN +1 N