非线性回归分析
《非线性回归分析》课件
封装式
• 基于模型的错误率和复 杂性进行特征选择。
• 常用的封装方法包括递 归特征消除法和遗传算 法等。
嵌入式
• 特征选择和模型训练同 时进行。
• 与算法结合在一起的特 征选择方法,例如正则 化(Lasso、Ridge)。
数据处理方法:缺失值填充、异常值 处理等
1
网格搜索
通过预定义的参数空间中的方格进行搜
随机搜索
2
索。
在预定义的参数空间中进行随机搜索。
3
贝叶斯调参
使用贝叶斯优化方法对超参数进行优化。
集成学习在非线性回归中的应用
集成学习是一种将若干个基学习器集成在一起以获得更好分类效果的方法,也可以用于非线性回归建模中。
1 堆叠
使用多层模型来组成一个 超级学习器,每个模型继 承前一模型的输出做为自 己的输入。
不可避免地存在数据缺失、异常值等问题,需要使用相应的方法对其进行处理。这是非线性回归 分析中至关重要的一环。
1 缺失值填充
常见的方法包括插值法、代入法和主成分分析等。
2 异常值处理
常见的方法包括删除、截尾、平滑等。
3 特征缩放和标准化
为了提高模型的计算速度和准确性,需要对特征进行缩放和标准化。
偏差-方差平衡与模型复杂度
一种广泛用于图像识别和计算机 视觉领域的神经网络。
循环神经网络
一种用于处理序列数据的神经网 络,如自然语言处理。
sklearn库在非线性回归中的应用
scikit-learn是Python中最受欢迎的机器学习库之一,可以用于非线性回归的建模、评估和调参。
1 模型建立
scikit-learn提供各种非线 性回归算法的实现,如 KNN回归、决策树回归和 支持向量机回归等。
非线性回归分析常见曲线及方程

非线性回归分析常见曲线及方程Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】非线性回归分析回归分析中,当研究的因果关系只涉及和一个时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。
此外,回归分析中,又依据描述自变量与因变量之间因果关系的表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。
通常线性回归分析法是最基本的分析方法,遇到非线性回归问题可以借助数学手段化为线性回归问题处理两个现象变量之间的相关关系并非线性关系,而呈现某种非线性的曲线关系,如:双曲线、二次曲线、三次曲线、幂函数曲线、指数函数曲线(Gompertz)、S型曲线(Logistic) 对数曲线、指数曲线等,以这些变量之间的曲线相关关系,拟合相应的回归曲线,建立非线性回归方程,进行回归分析称为非线性回归分析常见非线性规划曲线1.双曲线1bay x =+2.二次曲线3.三次曲线4.幂函数曲线5.指数函数曲线(Gompertz)6.倒指数曲线y=a/e b x其中a>0,7.S型曲线(Logistic)1e x ya b-=+8.对数曲线y=a+b log x,x>09.指数曲线y=a e bx其中参数a>01.回归:(1)确定回归系数的命令[beta,r,J]=nlinfit(x,y,’model’,beta0)(2)非线性回归命令:nlintool(x,y,’model’, beta0,alpha)2.预测和预测误差估计:[Y,DELTA]=nlpredci(’model’, x,beta,r,J)求nlinfit 或lintool所得的回归函数在x处的预测值Y及预测值的显着性水平为1-alpha的置信区间Y,DELTA.例2 观测物体降落的距离s与时间t的关系,得到数据如下表,求s关于t的回归方程2ˆct=.+btas+解:1. 对将要拟合的非线性模型y=a/e b x,建立M文件如下:function yhat=volum(beta,x)yhat=beta(1)*exp(beta(2)./x);2.输入数据:x=2:16;y=[ 10];beta0=[8 2]';3.求回归系数:[beta,r ,J]=nlinfit(x',y','volum',beta0); beta即得回归模型为:1.064111.6036e x y-=4.预测及作图:[YY,delta]=nlpredci('volum',x',beta,r ,J); plot(x,y,'k+',x,YY,'r')2.非线性函数的线性化曲线方程曲线图形变换公式变换后的线性函数by ax=ln ln ln c a v x u y=== u c bv +=bx y ae =ln ln c a u y==u c bv +=b xe y a=1ln ln x c a v u y===u c bv +=ln y a b x +=ln v x u y== u bv +=a。
非线性回归分析的入门知识

非线性回归分析的入门知识在统计学和机器学习领域,回归分析是一种重要的数据分析方法,用于研究自变量和因变量之间的关系。
在实际问题中,很多情况下自变量和因变量之间的关系并不是简单的线性关系,而是呈现出一种复杂的非线性关系。
因此,非线性回归分析就应运而生,用于描述和预测这种非线性关系。
本文将介绍非线性回归分析的入门知识,包括非线性回归模型的基本概念、常见的非线性回归模型以及参数估计方法等内容。
一、非线性回归模型的基本概念在回归分析中,线性回归模型是最简单和最常用的模型之一,其数学表达式为:$$Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_pX_p +\varepsilon$$其中,$Y$表示因变量,$X_1, X_2, ..., X_p$表示自变量,$\beta_0, \beta_1, \beta_2, ..., \beta_p$表示模型的参数,$\varepsilon$表示误差项。
线性回归模型的关键特点是因变量$Y$与自变量$X$之间呈线性关系。
而非线性回归模型则允许因变量$Y$与自变量$X$之间呈现非线性关系,其数学表达式可以是各种形式的非线性函数,例如指数函数、对数函数、多项式函数等。
一般来说,非线性回归模型可以表示为:$$Y = f(X, \beta) + \varepsilon$$其中,$f(X, \beta)$表示非线性函数,$\beta$表示模型的参数。
非线性回归模型的关键在于确定合适的非线性函数形式$f(X,\beta)$以及估计参数$\beta$。
二、常见的非线性回归模型1. 多项式回归模型多项式回归模型是一种简单且常见的非线性回归模型,其形式为: $$Y = \beta_0 + \beta_1X + \beta_2X^2 + ... + \beta_nX^n +\varepsilon$$其中,$X^2, X^3, ..., X^n$表示自变量$X$的高次项,$\beta_0, \beta_1, \beta_2, ..., \beta_n$表示模型的参数。
非线性回归分析常见模型

非线性回归常见模型一.基本内容模型一xc e c y 21=,其中21,c c 为常数.将xc ec y 21=两边取对数,得x c c e c y xc 211ln )ln(ln 2+==,令21,ln ,ln c b c a y z ===,从而得到z 与x 的线性经验回归方程a bx z +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型二221c x c y +=,其中21,c c 为常数.令a c b c x t ===212,,,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型三21c x c y +=,其中21,c c 为常数.a cbc x t ===21,,,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型四反比例函数模型:1y a b x=+令xt 1=,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型五三角函数模型:sin y a b x=+令x t sin =,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.二.例题分析例1.用模型e kx y a =拟合一组数据组()(),1,2,,7i i x y i =⋅⋅⋅,其中1277x x x ++⋅⋅⋅+=;设ln z y =,得变换后的线性回归方程为ˆ4zx =+,则127y y y ⋅⋅⋅=()A.70e B.70C.35e D.35【解析】因为1277x x x ++⋅⋅⋅+=,所以1x =,45z x =+=,即()127127ln ...ln ln ...ln 577y y y y y y +++==,所以35127e y y y ⋅⋅⋅=.故选:C例2.一只红铃虫产卵数y 和温度x 有关,现测得一组数据()(),1,2,,10i i x y i =⋅⋅⋅,可用模型21e c x y c =拟合,设ln z y =,其变换后的线性回归方程为4zbx =- ,若1210300x x x ++⋅⋅⋅+=,501210e y y y ⋅⋅⋅=,e 为自然常数,则12c c =________.【解析】21e c x y c =经过ln z y =变换后,得到21ln ln z y c x c ==+,根据题意1ln 4c =-,故41e c -=,又1210300x x x ++⋅⋅⋅+=,故30x =,5012101210e ln ln ln 50y y y y y y ⋅⋅⋅=⇒++⋅⋅⋅+=,故5z =,于是回归方程为4zbx =- 一定经过(30,5),故ˆ3045b -=,解得ˆ0.3b =,即20.3c =,于是12c c =40.3e -.故答案为:40.3e -.该景点为了预测2023年的旅游人数,建立了模型①:由最小二乘法公式求得的数据如下表所示,并根据数据绘制了如图所示的散点图.。
第八讲非线性回归分析

线性对数回归函数
因为该模型中Y是对数形式而X不是, 所以有时称它为对数线性模型。
如何理解β1的含义
在线性对数模型中, β1 表示X变化1个 单位引起Y的变化为(100*β1)%。
推导:我们考察自变量X变化∆X的过程。
此时: f ( X X ) f ( X ) ln(Y Y ) ln(Y ) ( Y ) Y
对数形式
对数形式经常用于表示变量的百分率变 化。例如:
在消费者需求的经济分析中,通常假定 价格上涨1%导致需求量下降一定的 百 分率。称价格上涨1%引起的需求下降 百分率为价格弹性(elasticity)。
对数形式是经济学中最常用的形式,广泛地应用在 各个领域中:
例如:在宏观经济学中,我们如果想研究投资的增
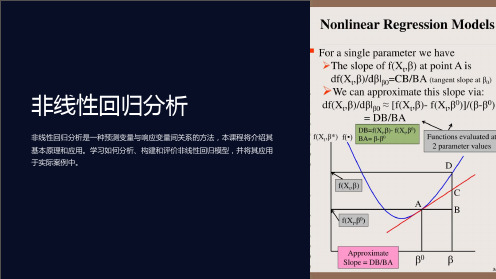
但当回归函数为非线性时,由于Y的预期 变化依赖于自变量的取值,因此其计算 较复杂。
我们假定非线性总体回归的一般公式为
书中的两个例子
1。地区收入从10----11(单位是千美 元)
2。地区收入从40----41
Yˆ (607.3 3.8511 0.0423112 ) (607.3 3.8510 0.0423102 ) 2.96 Yˆ (607.3 3.85 41 0.0423 412 ) (607.3 3.85 40 0.0423 402 ) 0.42
可以看出,income对testscore的弹性 逐渐变小。
效应估计的标准误差
在上例中
利用多元回归建立非线性模型的 一般方法
(1)确定一种可能的非线性关系。最佳做法 是利用经济理论和你对实际应用的了解提出 一种可能的非线性关系。在看数据之前,问 自己联系Y和X的回归函数斜率是否依赖于X 或其他自变量的取值。
当d1=0(男性) 对Y的效应为β2 当d1=1(女性) 对Y的效应为β2+β3
非线性回归分析的方法研究

非线性回归分析的方法研究在科学和工程领域,回归分析是一种广泛使用的数据分析方法,旨在探索变量之间的相互关系。
然而,许多实际问题是非线性的,传统的线性回归方法无法很好地解决这些问题。
因此,非线性回归分析的研究变得越来越重要。
本文将介绍非线性回归分析的基本概念、方法、应用领域以及所面临的挑战,并讨论未来的研究方向。
非线性回归分析方法可以解决许多复杂的问题,如生物医学、经济学、工程等领域中的非线性关系。
例如,在生物医学领域,药物浓度与治疗效果之间的关系往往是非线性的;在经济学领域,价格和需求之间的关系也往往是非线性的。
因此,研究非线性回归分析的方法对于解决这些实际问题具有重要的意义。
参数非线性回归是一种常用的非线性回归方法,它通过建立一个包含参数的数学模型来描述变量之间的非线性关系。
这种方法通常包括确定参数的初始值、使用最小二乘法等优化算法来拟合模型以及验证模型的可靠性等步骤。
基于核的非线性回归方法使用核函数来计算变量之间的相似性,并将这些相似性用于建立回归模型。
这种方法不需要明确的数学表达式,因此可以处理一些难以描述的复杂非线性关系。
支持向量回归是一种基于支持向量机(SVM)的非线性回归方法。
它通过建立一个SVM模型来描述变量之间的非线性关系,并使用优化算法来寻找最优的模型参数。
非线性回归分析方法在各个领域都有广泛的应用。
例如,在生物医学领域,非线性回归分析可以用于研究药物浓度与治疗效果之间的关系,为新药研发提供指导;在经济学领域,非线性回归分析可以用于研究价格和需求之间的关系,帮助企业制定更加合理的定价策略。
非线性回归分析还广泛应用于工程、环境科学、社会科学等领域。
数据处理:非线性回归分析需要处理的数据往往比较复杂,需要采取合适的数据预处理方法来提高分析的准确性。
模型选择:不同的非线性回归方法适用于不同的问题,如何根据实际问题选择合适的模型是一个重要的挑战。
模型优化:非线性回归模型需要通过优化算法来寻找最优的模型参数,如何选择合适的优化算法也是一个重要的挑战。
非线性回归分析
非线性回归分析随着数据科学和机器学习的发展,回归分析成为了数据分析领域中一种常用的统计分析方法。
线性回归和非线性回归是回归分析的两种主要方法,本文将重点探讨非线性回归分析的原理、应用以及实现方法。
一、非线性回归分析原理非线性回归是指因变量和自变量之间的关系不能用线性方程来描述的情况。
在非线性回归分析中,自变量可以是任意类型的变量,包括数值型变量和分类变量。
而因变量的关系通常通过非线性函数来建模,例如指数函数、对数函数、幂函数等。
非线性回归模型的一般形式如下:Y = f(X, β) + ε其中,Y表示因变量,X表示自变量,β表示回归系数,f表示非线性函数,ε表示误差。
二、非线性回归分析的应用非线性回归分析在实际应用中非常广泛,以下是几个常见的应用领域:1. 生物科学领域:非线性回归可用于研究生物学中的生长过程、药物剂量与效应之间的关系等。
2. 经济学领域:非线性回归可用于经济学中的生产函数、消费函数等的建模与分析。
3. 医学领域:非线性回归可用于医学中的病理学研究、药物研发等方面。
4. 金融领域:非线性回归可用于金融学中的股票价格预测、风险控制等问题。
三、非线性回归分析的实现方法非线性回归分析的实现通常涉及到模型选择、参数估计和模型诊断等步骤。
1. 模型选择:在进行非线性回归分析前,首先需选择适合的非线性模型来拟合数据。
可以根据领域知识或者采用试错法进行模型选择。
2. 参数估计:参数估计是非线性回归分析的核心步骤。
常用的参数估计方法有最小二乘法、最大似然估计法等。
3. 模型诊断:模型诊断主要用于评估拟合模型的质量。
通过分析残差、偏差、方差等指标来评估模型的拟合程度,进而判断模型是否适合。
四、总结非线性回归分析是一种常用的统计分析方法,可应用于各个领域的数据分析任务中。
通过选择适合的非线性模型,进行参数估计和模型诊断,可以有效地拟合和分析非线性关系。
在实际应用中,需要根据具体领域和问题的特点来选择合适的非线性回归方法,以提高分析结果的准确性和可解释性。
非线性回归分析江南大学张荷观.pptx
记 (1, 2 ,, p ) , 高斯–牛顿法的具体方法如下。
第9页/共47页
(1)
先取参数的一组初值 B0 (b10 , b20 ,, bp0 ) , 根据泰勒级数并 只取线性项, 得
y f (x1, x2 ,, xk ;b10 , b20 ,, bp0 )
p i 1
f
i
b B0 i0
p f
i1 i
B0 i '
第10页/共47页
(3-6)
最小二乘估计
令
MLeabharlann yf(x1 , x2 ,, xk ;b10 , b20 ,, bp0 )
p i 1
f
i
b B0 i0
Zi
f
i
B0 , i 1,2,, p
对给定的初始值 B0 , M 和 Zi 都是确定的。则得线性回归模型
停止迭代。 在实际工作中这几个标准可替换, 但无明显优劣, 一般可同时
使用。
第23页/共47页
第三节 非线性回归评价和假设捡验 与线性回归分析一样,非线性回归分析在建立回归方程后进行评 价和捡验。主要有回归方程拟合度的评价,以及回归方程和回归系数 的显著性捡验等。非线性回归的最小二乘估计不是BLUE, 但一般条 件下是一致估计。
直到满足要求, 即得参数的最小二乘估计。
直接搜索法和格点搜索法都是低效的, 在实际工作中很少采用。
第8页/共47页
三、高斯–牛顿(Gauss - Newton)法 高斯–牛顿法是一种常用的迭代法。 非线性回归模型不能通过变换转化为线性回归模型, 但可以利 用泰勒展开式转化为线性回归模型。设非线性回归模型
非线性回归与指数回归的分析方法
因果推断:在统 计学领域,非线 性回归与指数回 归可用于分析变 量之间的因果关 系,为决策提供 依据。
医学研究:在医 学领域,非线性 回归与指数回归 可用于研究疾病 发生、发展与治 疗的效果,为医 学研究和临床实 践提供支持。
在经济学领域的应用前景
预测经济趋势:非线性回归与指数回归可用于预测经济趋势,帮助决策 者制定更加科学合理的经济政策。
合数据。
非线性回归分 析方法可以用 于探索变量之 间的复杂关系, 例如幂函数、 对数函数等。
非线性回归分 析方法在数据 分析、统计学、 机器学习等领 域有广泛应用。
适用场景
描述因变量和自变量之间非线性关系的场景 探索变量之间的潜在机制和因果关系的场景 对数据分布和统计假设不满足线性回归的场景 需要考虑交互项和多项式项的场景
常用模型
双曲线模型 逻辑斯蒂模型 生长曲线模型 多项式回归模型
参数估计与模型检验
参数估计:非线性回归分析方法使用最小二乘法或最大似然法进行参数 估计,以确定最佳拟合曲线。
模型检验:通过残差分析、正态性检验、异方差性检验等方法对非线性 回归模型的适用性和可靠性进行检验。
诊断检验:对模型中可能存在的各种问题,如多重共线性、自相关等进 行诊断和检验。
THANKS
汇报人:XX
比较分析结果
非线性回归与指数回归的拟合 度比较
预测结果准确性比较
模型适用性比较
参数解释性比较
Part Five
非线性回归与指数 回归的优缺点分析
非线性回归的优缺点分析
优点:能够处理非 线性关系的数据, 更好地拟合数据, 更准确地预测结果。
缺点:模型复杂度 高,计算量大,需 要更多的数据和样 本量,且模型的可 解释性较差。
非线性回归分析
非线性回归分析随着经济和社会的发展,数据分析和统计方法越来越受到重视。
在统计学中,回归分析是一种广泛应用的方法,它可以帮助我们研究两个或多个变量之间的关系,并用数学模型描述它们之间的关系。
线性回归是最基本的回归分析方法,但在实际应用中,很多现象并不是线性的,这时候就需要用到非线性回归分析。
什么是非线性回归分析?非线性回归分析是一种研究两个或多个变量之间关系的方法,但假设它们之间的关系不是线性的。
因此,在非线性回归模型中,自变量和因变量之间的关系可以被描述为一个非线性函数,例如指数函数、对数函数、幂函数等。
非线性回归模型的公式可以表示为:y = f(x, β) + ε其中,y是因变量,x是自变量,β是待估计参数,f是非线性函数,ε是随机误差项。
非线性回归模型的目的就是估计参数β,找出最佳的拟合函数f,使预测值与实际值的误差最小。
常见的非线性回归模型包括:1. 指数模型:y = αeβx + ε2. 对数模型:y = α + βln(x) + ε3. 幂函数模型:y = αxβ + ε4. S型曲线模型:y = α / (1 + e^(βx)) + ε为何要使用非线性回归分析?非线性回归模型可以更好地描述真实世界中的现象。
例如,在生态学中,物种数量和资源的关系往往是非线性的,这时候就需要用到非线性回归分析来研究它们之间的关系。
再如,在经济学中,通货膨胀率和经济增长率之间的关系也是非线性的。
此外,非线性回归还可以应用于医学、生物学、工程学、地球科学等领域,用于研究复杂的现象和关系。
如何进行非线性回归分析?1. 数据准备首先需要收集相关数据,并进行数据清洗和处理。
确保数据的准确性和完整性。
2. 模型选择根据数据的特征和研究目的,选择适合的非线性回归模型。
如果不确定,可以尝试多种模型进行比较。
3. 参数估计使用统计方法估计模型中的参数值。
常用的方法包括最小二乘法、极大似然法等。
4. 模型诊断诊断模型的拟合程度和假设是否成立。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
非线性回归分析(转载)(2009-10-23 08:40:20)转载分类:Web分析标签:杂谈在回归分析中,当自变量和因变量间的关系不能简单地表示为线性方程,或者不能表示为可化为线性方程的时侯,可采用非线性估计来建立回归模型。
SPSS提供了非线性回归“Nonlinear”过程,下面就以实例来介绍非线性拟合“Nonlinear”过程的基本步骤和使用方法。
应用实例研究了南美斑潜蝇幼虫在不同温度条件下的发育速率,得到试验数据如下:表5-1 南美斑潜蝇幼虫在不同温度条件下的发育速率温度℃17.5 20 22.5 25 27.5 30 35 发育速率0.0638 0.0826 0.1100 0.1327 0.1667 0.1859 0.1572 根据以上数据拟合逻辑斯蒂模型:本例子数据保存在DATA6-4.SAV。
1)准备分析数据在SPSS数据编辑窗口建立变量“t”和“v”两个变量,把表6-14中的数据分别输入“温度”和“发育速率”对应的变量中。
或者打开已经存在的数据文件(DATA6-4.SAV)。
2)启动线性回归过程单击SPSS主菜单的“Analyze”下的“Regression”中“Nonlinear”项,将打开如图5-1所示的线回归对话窗口。
图5-1 Nonlinear非线性回归对话窗口3) 设置分析变量设置因变量:从左侧的变量列表框中选择一个因变量进入“Dependent(s)”框。
本例子选“发育速率[v]”变量为因变量。
4) 设置参数变量和初始值单击“Parameters”按钮,将打开如图6-14所示的对话框。
该对话框用于设置参数的初始值。
图5-2 设置参数初始值“Name”框用于输入参数名称。
“Starting”框用于输入参数的初始值。
输入完参数名和初始值后,单击“Add”按钮,则定义的变量及其初始值将显示在下方的参数框中。
需要修改已经定义的参数变量,先用将其选中,然后在“Name”和“Starting”栏里进行修改,完成后点击“Change”按钮确认修改。
要删除已经定义的参数变量,先用将其选中,然后点击“Bemove”按钮删除。
在本例逻辑斯蒂模型中估计的参数有“K”、“a”和“b”三个参数变量。
设置初始值为:K=0.1;a=3;b=0.1。
参数的初始值可根据给定模型中参数定义范围情况而定。
输入后的“Nonlinear”对话窗口如下图。
图5-3 设置参数初始值后的对话框完成后点击“Continue”按钮。
5)输入方程式在“Model expression_r_r”框中输入需要拟合的方程式,在该方程中包含自变量、参数变量和常数等。
自变量和参数变量可以从左边的列表框和“Parameters”框里选入。
方程中的函数可以从“Function”框里选入;运算符号和常数可以用鼠标从窗口“数字符号”显示区中点击输入。
本例输入的逻辑斯蒂模型是: K/(1+EXP(a-b*t))。
输入后的窗口显示如下图。
图5-4 设置后的非线性回归对话窗口6) 迭代条件在主对话框中单击“Loss”按钮,将打开如图5-5所示的对话框。
图5-5 Loss 对话框Sum of squared residuals”项,残差平方和最小值,系统默认。
本例选该项。
“User-defined loss function”自定义选项。
设置其他统计量为迭代条件,在下边输入框中输入相应的统计量的表达式,称为损失函数。
在左上角的变量列表框中,“RESID”代表所选变量的残差;“PRED_”代表预测值。
可以从左下角框中选择已定义的参数进入损失函。
7)参数取值范围在主对话框中单击“Constraints”按钮,将打开如图5-6所示的对话框。
在该对话框中设置回归方程中参数的取值范围。
选中“Define parameter constraint”项,即可对选定的参数变量设置取值范围。
参数的取值范围,用不等式“=,<=,>=”来定义。
例如,在本例逻辑斯蒂模型中K参数应该小于1。
应该定义如下:k<=0.9999定义后会提示:是否复制现有的变量名,回答“确定”。
图5-6 参数取值范围对话框8) 保存分析数据在主对话框中单击“Save”按钮将打开如图5-7所示的对话框,选择要保存到数据文件中的统计量。
图 5-7 Save对话框其中各项分别为:“Predicted values”因变量的预测值。
“Residuals”因变量的残差。
“Derivatives”派生数。
“Loss function values”损失函数值。
9) 迭代方法主对话框中单击“Options”按钮,将打开如图5-8所示的对话框。
图5-8 迭代方法对话框“Bootstrap estimates of standard error”项,将采用样本重复法计算标准误。
样本重复法需要顺序二次规划算法的支持。
当选中该项时,SPSS将自动选中“Sequential quadratic Programming”项。
“Estimation Method”框中列出了参数的两种估计方法:“Sequential Quadratic Programming”项为顺序二次规划算法。
该方法要求输入的参数为:“Maximum”最大迭代步数。
“Step Iimit”最大步长。
“Optimality”目标函数的迭代误差限。
“Function”函数精度,应比目标函数的迭代误差限小。
“Infinite step”当一次迭代中参数值的变化大于设置值,则迭代停止。
“Levenberg-Marquardt”项,采用麦夸尔迭代法),系统缺省设置。
该法要求输入的参数为:“Maximum iterations”最大迭代步数。
“Sum-of-squares convergence”在一步迭代中目标函数残差平方和的变化比例小于设置的值时,迭代停止。
“Parameter convergence”在一步迭代中参数的变化比例小于设置值时,迭代停止。
本例选“Levenberg-Marquardt”项,最大迭代步数100,残差平方和的变化比例小于1E-8,参数的变化比例小于1E-8。
10)提交执行所有的设置完成后,在主对话框中点击“OK”按钮提交所有设置,SPSS执行过程后输出结果显示在输出窗口中。
11) 结果分析结果:<img height="734" alt="文本框: All the derivatives will be calculated numerically. Iteration Residual SS K A B 1 .0625076405 .100000000 3.00000000 .100000000 1.12.564768220 -.475469153.69314164 .675071407 1.2 .0050867657 .1577097061.90159327 .141778778 2 .0050867657 .157709706 1.90159327 .141778778 : : : :16 .0009331870 .177359068 5.70621767 .281983521 16.1 .0009331870 .177360878 5.70599385 .281971271 Run stopped after 33 model uations and 16 derivative uations. Iterations have been stopped because the relative reduction between successive residual sums of squares is at most SSCON = 1.000E-08 Nonlinear Regression Summary Statistics Dependent Variable V Source DF Sum of Squares Mean Square Regression3 .12673 .04224 Residual 4 9.331870E-04 2.332968E-04 Uncorrected Total 7 .12766 (Corrected Total) 6 .01223 R squared = 1 - Residual SS / Corrected SS = .92370 Asymptotic 95 % Asymptotic Confidence Interval Parameter Estimate Std. Error Lower Upper (参数名估计参数标准误 95%置信限 )K .177360878 .015726528 .133697035 .221024720 A 5.705993848 1.793759786 .725718271 10.686269425 B .281971271 .092934086 .023944884 .539997658 Asymptotic Correlation Matrix of the Parameter Estimates (参数相关矩阵) K A B K 1.0000 -.6624 -.7401 A -.6624 1.0000 .9889 B -.7401 .9889 1.0000 "src="/epcl/spss/Regression/images/5_clip_image001.gif"width="546" />根据以上输出结果得到K的参数估计值是0.177360878;a的参数估计值是5.705993848;b 的参数估计值是0.281971271。
其拟合的逻辑斯蒂发育速率模型为:残差平方和(Q)为0.0009331870;拟合优度系数(R2)为0.92370。