分子数据库及NCBI序列检索
NCBI如何查找序列

NCBI如何查找序列NCBI(National Center for Biotechnology Information,国家生物技术信息中心)是一个提供生物技术信息服务的综合性数据库。
该数据库包含了大量的基因序列、蛋白质序列、文献等信息。
要查找序列,可以使用NCBI提供的不同工具和资源,包括基本功能、BLAST(基本局部序列比对工具)和Entrez等。
1.基本功能:NCBI提供了一个称为"Basic Search"的引擎,可以使用关键字、序列ID、序列描述等进行。
只需要在框中输入关键字,系统将返回与该关键字相关的所有序列。
可以通过筛选选项进一步缩小范围,例如组织选择、物种选择、发表年份等。
这对于查找特定的序列非常有用。
2.BLAST(基本局部序列比对工具):BLAST是NCBI提供的一种用于快速和比对生物序列的工具。
它可以比对给定的序列与NCBI数据库中的序列进行相似性。
用户只需将目标序列输入到框中,选择BLAST数据库和其他设置,小工具将返回与目标序列相似的其他序列和相关信息,包括序列标识符、比对分数、比对位置等。
3. Entrez:Entrez是NCBI提供的一个综合性数据库引擎,可以用于不同类型的生物信息,包括序列、文献、生物样本等。
用户可以在框中输入关键字,并选择要的数据库类型。
对于序列,选择"Nucleotide"、"Protein"或"Gene"数据库类型。
此外,用户还可以使用高级选项进行更精确的。
结果将包括与关键字相关的序列、文献、记录和其他相关信息。
此外,NCBI还提供一些其他工具和资源,可以进一步帮助用户查找和分析序列,如NCBI数据浏览器、Gene数据库、SRA数据库等。
这些工具和资源可以根据具体需求进行使用。
总之,通过NCBI提供的基本功能、BLAST工具和Entrez系统,用户可以方便地查找到自己需要的生物序列。
ncbi使用方法

ncbi使用方法(原创版4篇)《ncbi使用方法》篇1CBI(National Center for Biotechnology Information)是美国国家生物技术信息中心的缩写,它提供了许多生物学和生命科学相关的数据库和工具。
以下是使用NCBI 的一些基本方法:1. 核酸序列数据库(Nucleotide Sequence Database):在NCBI 主页上,可以选择核酸序列数据库,输入序列名称或序列号,然后点击“Search”按钮即可查询序列信息。
2. 蛋白质序列数据库(Protein Sequence Database):在NCBI 主页上,可以选择蛋白质序列数据库,输入蛋白质名称或蛋白质号,然后点击“Search”按钮即可查询蛋白质信息。
3. 基因组数据库(Genome Database):在NCBI 主页上,可以选择基因组数据库,输入基因组名称或基因组号,然后点击“Search”按钮即可查询基因组信息。
4. 代谢通路数据库(Metabolic Pathway Database):在NCBI 主页上,可以选择代谢通路数据库,输入代谢通路名称或代谢通路号,然后点击“Search”按钮即可查询代谢通路信息。
5. 生物投影数据库(BioProject Database):在NCBI 主页上,可以选择生物投影数据库,输入生物投影名称或生物投影号,然后点击“Search”按钮即可查询生物投影信息。
6. 序列比对工具(Sequence Alignment Tool):NCBI 提供了一款名为“Clustal Omega”的序列比对工具,可以在NCBI 主页上使用该工具进行序列比对。
7. 基因表达数据库(Gene Expression Database):NCBI 提供了一款名为“GEO”的基因表达数据库,可以在NCBI 主页上查询基因表达数据。
8. 蛋白质结构数据库(Protein Structure Database):NCBI 提供了一款名为“RCSB PDB”的蛋白质结构数据库,可以在NCBI 主页上查询蛋白质结构信息。
NCBI良心教程寻找基因转录本序列及相关编码蛋白

NCBI良心教程寻找基因转录本序列及相关编码蛋白NCBI (National Center for Biotechnology Information) 是一个全球顶级的生物医学数据库,提供了大量的基因序列和相关的生物信息。
在这个教程里,我们将介绍如何在NCBI中基因转录本序列以及相关编码蛋白。
第一步:访问NCBI网站首先,打开你的浏览器,并输入 "NCBI",然后点击按钮。
在结果中,选择并点击进入 "NCBI - National Center for Biotechnology Information" 的官方网站。
第二步:选择数据库在NCBI的官方网站中,你可以看到很多不同的数据库。
对于本教程,我们将使用 "GenBank" 数据库来基因转录本序列以及相关编码蛋白。
点击页面左上角的 "Databases" 菜单,然后选择 "Nucleotide" 数据库,它是用于基因序列的数据库。
第三步:基因转录本序列在 "Nucleotide" 页面中,你会看到一个框,可以输入你感兴趣的基因的名称或相关关键词。
在框中输入基因的名称或相关关键词,然后点击按钮。
此时,你将看到与该基因相关的转录本序列的结果列表。
除了查找基因转录本序列,你还可以使用NCBI相关的编码蛋白质序列。
在 "Nucleotide" 页面中,选择 "Protein" 或 "Protein database" 选项卡。
在框中输入与你感兴趣的蛋白质相关的关键词,并点击按钮。
此时,你将看到与该蛋白质相关的转录本或基因的结果列表。
点击结果列表中感兴趣的蛋白质,你将进入蛋白质的详细页面。
在这个页面上,你可以找到该蛋白质的序列以及其他相关信息。
总结:在NCBI中基因转录本序列及相关编码蛋白可以通过以下步骤完成:1.访问NCBI官方网站;2.选择 "GenBank" 数据库;3.你感兴趣的基因的名称或相关关键词;4.点击结果中的转录本,查看序列和其他详细信息;5.如果你想相关编码蛋白质,选择 "Protein" 选项卡,并输入相关关键词;6.点击结果中的蛋白质,查看蛋白质序列和其他相关信息。
NCBI如何查找序列
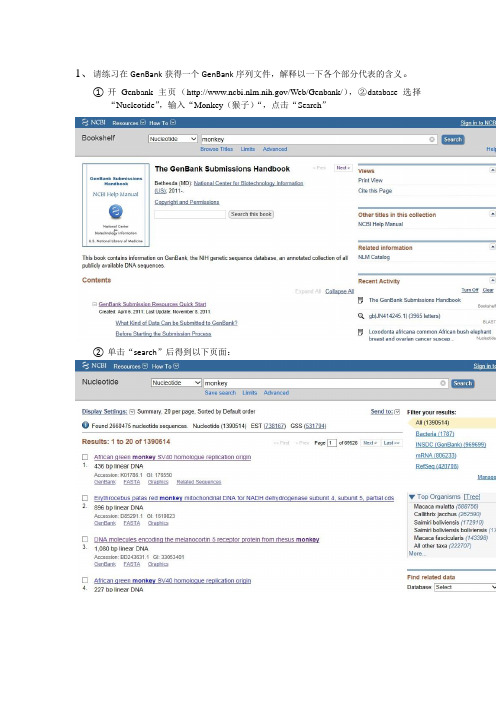
1、请练习在GenBank获得一个GenBank序列文件,解释以一下各个部分代表的含义。
①开Genbank主页(/Web/Genbank/),②database选择“Nucleotide”,输入“Monkey(猴子)“,点击“Search”②单击“search”后得到以下页面:③然后选择第一个序列文献打开;找到如下图的位置,选择“file“,保存到电脑。
序列内容如下:序列内容各部分意思如下:Go to:LOCUS AGMSV40RP 436 bp DNA linear PRI (名称)(碱基数)(分子类型)(分子类型)(灵长类)27-APR-1993(修正日期)DEFINITION African green monkey SV40 homologue replication origin. (定义行,精要描述序列特征)ACCESSION K01786(检索号)VERSION K01786.1 GI:176550(版本信息)KEYWORDS origin of replication.(关键词)SOURCE Chlorocebus aethiops (Cercopithecus aethiops)(物种来源及常用名)ORGANISM Chlorocebus aethiops(科学命名及该物种的分类地位)Eukaryota; Metazoa; Chordata; Craniata; Vertebrata;Euteleostomi;Mammalia; Eutheria; Euarchontoglires; Primates;Haplorrhini;Catarrhini; Cercopithecidae; Cercopithecinae; Chlorocebus. REFERENCE 1 (bases 1 to 436)(参考文献)AUTHORS Queen,C., Lord,S.T., McCutchan,T.F. and Singer,M.F.(作者)TITLE Three segments from the monkey genome that hybridize to simian (题目) virus 40 have common structural elementsJOURNAL Mol. Cell. Biol. 1 (12), 1061-1068 (1981)(期刊来源)PUBMED 6287216(数据库编号)REFERENCE 2 (sites)(参考文献)AUTHORS Dynan,W.S., Saffer,J.D., Lee,W.S. and Tjian,R.(作者)TITLE(题目) Transcription factor Sp1 recognizes promoter sequences from the monkey genome that are simian virus 40 promoterJOURNAL Proc. Natl. Acad. Sci. U.S.A. 82 (15), 4915-4919 (1985)(期刊来源)PUBMED 2991898(数据库编号)COMMENT(注释)Original source text: African green monkey liver DNA, clonepCaOri7.01 [1].[2] sites; Sp1 binding sites.Draft entry and clean copy sequences for [2] kindly provided byW.Dynan, 31-OCT-1985.Two segments of monkey DNA were hybridized and compared to SV40DNA. Each contained multiple copies of the sequence 'gggcggrr'which also appears six times near the origin of SV40 [1]. Bothcontained a long internal degenerate repeat [1]. The SV40 origin ofreplication contains several long repeats [1]. The SV40 hybridizingsegments are members of a larger family of genomic monkey sequencesthat hybridize well to each other, but not necessarily to SV40 [1].Two regions in the monkey DNA bind the promoter-specific cellulartranscription factor (SP1) and are protected by it in DNaseprotection experiments [2].FEATURES Location/Qualifiers(特征)source 1..436(物种来源) /organism="Chlorocebus aethiops"/mol_type="genomic DNA"/db_xref="taxon:9534"ORIGIN(序列区) SalI site.1 tcgaccacag ccagagtcca tgcatcggga ggttcactcg gtttgcgaag aacgggcagg61 gcatgcacgg cctgggctcg gcgggcgggc gggcgggccg gggcgcagtt cccaggttcg121 ccactagagg tcaggaggtg accgcttcgg ggctggaaga cgggcccgtc gtggattggc181 tagtgccggc ggagggcggg gcggagagtg gggcggggcg gagagtgggg cggggcgcag241 ttccccagtt cgccactaga ggtcaggagg tgaccgcttc ggggcgggaa gactggcccg301 tcggggattg gctagtgccg gcggggggcg gggcgggggg cggagggcgg ggtggacgtg361 gcacctggtt gctgacatct ggaatgactt ttttttggca tcggatttcc tgtctttgtg421 gggctgatgg acccga//2.预习genbank中blast的用法BLAST 是由美国国立生物技术信息中心(NCBI)开发的一个基于序列相似性的数据库搜索程序。
ncbi数据库检索解读

收集并储存大分子结构信息,部分来源于PDB
提供并及时更新后生生物的全基因组序列以及最为精确的注释. 是一个蛋白质信息最为准确的蛋白质数据库, 它所提供的蛋白质信息有着最详尽的注释和 最少的冗余..
5 UniProtKB\Swiss-prot
2.2.4 SRS 检索实例
已知BPMV的名字,查询其基因组的信息,核酸序 列信息,蛋白质序列信息和结构信息
第二章 数据库检索
2.1 综合性数据库 NCBI
2.1.1 NCBI简介
美国参议员Claude Pepper率先意识到信息计算机化过程 方法对指导生物医学研究的重要性,发起了在1988年11月4日 建立国立生物技术信息中心的立法. (National Center for Biotechnology Information , NCBI) . NCBI隶属于国立医学图书馆( National Library of Medicing, NLM)。NLM在创立和维护生物医学数据库方面有 丰富的经验。
包含用于群体进化或变异研究的比对序列
准确的基因表达谱数据和大规模的分子实验数据
公众医学信息中心,是NLM在生命科学领域 Central数据库 期刊文献的数字存档 医学主题5 Bookshelf 数据库
16 OMIM 数据库
主要着眼于可遗传或遗传性的基因疾病,包括文献, 序列记录,染色体定位图谱及相关的数据库的链接
7 uniSTS数据库 8 基因数据库 9 UniGene数据库
可通过基因名称,同义词,编号,出版物,染色体号等属性 寻找基因 GenBank 中基因序列的集合
10 SNP数据库 11 PopSet 12 GEO数据库 13 PubMed
用于存储包括单核苷酸替换,一两个碱基的插入 或缺失等多态性信息
NCBI检索

NCBI的检索NCBI包括五个部分,第一部分是欢迎进入NCBI,包括NCBI的最新信息、计划与活动、读者来信、服务地址和用户评论等。
第二部分是基因序列数据库(GenBank),包括基因库概述、检索与投稿。
第三部分是数据库服务,包括免费的PubMed检索、Entrez检索、BLAST序列族性检索、电子邮件服务(详见本章第四节)、匿名FTP服务。
第四部分是NCBI的其它资源。
GenBank的检索在NCBI主页的第二部分点击“Searching GenBank”,即可进入GenBank的检索屏幕。
NCBI•提供了五种检索,即Entrez浏览检索、BLAST序列类似性检索、dbEST检索、dbSTS•检索和文本检索(Text Searching)。
一、Entrez浏览检索1.Entrez检索的数据库及其检索信息Entrez浏览器(Entrez Browser)可以检索以下与NCBI•链接的基因序列数据库的分子生物数据和书目文献资料。
••••(1) GenBank、EMBL、DDBJ中的DNA序列;••••(2) SWISS-PROT、PIR、PRF、PDB中的蛋白质序列以及DNA序列数据库中翻译的蛋白质序列;••••(3) 基因和染色体图像数据;••••(4) PDB以及收入NCBI分子模型数据库(MMDB)的蛋白质三维结构;••••(5) 通过PubMed检索Medline和PreMedline数据库。
••••2.Entrez检索功能••••Entrez提供了以下三种检索功能。
••••(1)自由词检索功能••••用户可以通过文本词、关键词、截词、期刊名或文献的作者检索Entrez数据库。
截词用*号,期刊名必须用Medline刊名缩写,作者姓名必须是姓在前,名在后,用首字母缩写。
••••(2)索引词表(List Terms)检索功能••••索引词表检索是当你键入检索词,Entrez•在你选定的字段中显示从该检索词开始的一个索引词表窗口,这时,你可以选择一个或几个词进行检索,这对单词拼写不准确时非常有用。
《植物分子生物学》PPT课件

生物信息学基础(10学时)
唐玉荣 tangyurong@
主要内容
1. 绪论
2学时
2. 分子数据库及NCBI序列检索
3. 双序列比对及BLAST比对工具 4学时
4. 多序列比对和分子系统发育
4学时
5. 核酸和蛋白质序列分析工具
主要参考书
1.基础生物信息学及应用,蒋彦等,清华大学 出版社
蛋白数据库
SWISS-PROT(蛋白序列数据库) /swissprot/
BioSino
网址: /
HKBIC
网址: .hk/
MBC
网址: .tw/index.php
TUBIC
网址: /
EMBL
NIH
DDBJ
• GenBank数据库
–基因组DNA数据库 –对应于表达基因的cDNA数据库 –表达序列标签(ESTs) –序列标签位点(STS) –基因组测序序列(GSSs) –高通量基因组序列(HTGS)
• 其它核酸数据库
• HIV Database(HIV序列数据库)
/content/index
数学
计算机
生物信息学
生物
1.3 生物信息学目标任务
• 收集和管理生物分子数据 • 数据分析和挖掘 • 开发分析工具和实用软件
–生物分子序列比较工具 –基因识别工具 –生物分子结构预测工具 –基因表达数据分析工具
1.4 生物信息学研究内容
序列比对 (Sequence Alignment) 蛋白质结构预测 计算机辅助基因识别 非编码区分析和DNA语言研究 分子进化和比较基因组学 序列重叠群装配 遗传密码的起源 基于结构的药物设计 基因表达谱分析 ,代谢网络分析 ,基因
NBCI介绍与使用方法

NBCI介绍与使用方法2012-02-25 21:35:32| 分类:书籍学术| 标签:nbci blast 基因组测序 dna |字号大中小订阅NCBI (National Center for Biotechnology Information), 美国国家生物技术信息中心[url]/[/url]NCBI是NIH的国立医学图书馆(NLM)的一个分支。
NCBI提供检索的服务包括:1.GenBank(NIH遗传序列数据库):一个可以公开获得所有的DNA序列的注释过的收集。
GenBank 是由NCBI受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库的。
它同日本和欧洲分子生物学实验室的DNA数据库共同构成了国际核酸序列数据库合作。
这三个组织每天交换数据。
其中的数据以指数形式增长,最近的数据为它已经有来自47000个物种的30亿个碱基。
2.Molecular Databases(分子数据库):Nucleotide Sequence(核酸序列库):从NCBI其他如Genbank数据库中收集整理核酸序列,提供直接的检索。
Protein Sequence (蛋白质序列库):与核酸类似,也是从NCBI多个不同资源中编译整理的,方便研究者的直接查询。
Structure(结构)-——关于NCBI结构小组的一般信息和他们的研究计划,另外也可以访问三维蛋白质结构的分子模型数据库(MMDB)和用来搜索和显示结构的相关工具。
MMDB:分子模型数据库—一个关于三维生物分子结构的数据库,结构来自于X-ray晶体衍射和NMR色谱分析。
Taxonomy(分类学)——NCBI的分类数据库,包括大于7万余个物种的名字和种系,这些物种都至少在遗传数据库中有一条核酸或蛋白序列。
其目的是为序列数据库建立一个一致的种系发生分类学。
3.Literature Databases(文献数据库)(1)PubMed是NLM提供的一项服务,能够对MEDLINE上超过1200万条的上世纪六十年代中期至今的杂志引用和其他的生命科学期刊进行访问,并可以连接到参与的出版商网络站点的全文文章和其他相关资源。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• GenBank数据库 –基因组DNA数据库 –对应于表达基因的cDNA数据库 –蛋白质数据库 –表达序列标签(ESTs) –序列标签位点(STS) –基因组测序序列(GSSs) –高通量基因组序列(HTGS)
• 其它核酸数据库
• HIV Database(HIV序列数据库)
/content/index
1.4
生物信息学研究内容
序列比对 (Sequence Alignment) 蛋白质结构预测 计算机辅助基因识别 非编码区分析和DNA语言研究
分子进化和比较基因组学
序列重叠群装配 遗传密码的起源 基于结构的药物设计 基因表达谱分析 ,代谢网络分析 ,基因 芯片设计和蛋白质组学数据分析等
• EMBL
( European Molecular Biology Laboratory欧洲分子生 物学实验室数据库 ,EBI维护)
• GenBank
( NCBI , National Center for Biotechnology Information 美国国家生物技术信息中心数据库)
• DDBJ
TUBIC
网址: /
CHGC
网址:
/
2.
分子数据库及NCBI序列检索
核酸序列数据
2.1 分子数据类型
生 物 分 子 信 息 生物分子功能数据
2.2
分子数据库 核酸数据库
植物分子生物学
生物信息学基础(12学时)
唐玉荣
tangyurong@
主要内容
1. 绪论
2学时(第2周) 4学时(第2周) 2学时(第3周) 2学时(第5周)
2. 分子数据库及NCBI序列检索
3. 双序列比对及BLAST比对工具
4. 多序列比对和分子系统发育
5. 核酸和蛋白质序列分析工具
Sanger
网址: 主要提供基因组研究相关的数 据与分析工具
SIB
网址:
http://www.isb-sib.ch/
ANGIS
网址:
.au/
NIG
网址:
http://www.nig.ac.jp/index-e.html
NCBI
网址: / 包含了公共数据库、生物信 息工具及应用等多种资源。 与很多生物信息软件相关的 站点及资源有链接。
NCBI站点图
EBI
/ 包含了生物数据库、 软件等多种资源,很 多都有相当优秀的使 用指导帮助
• IMGT(ImMunoGeneTics数据库含有与免疫系统有
关的核酸序列数据 ) /imgt/
• dbEST (序列表达标记数据库)
/dbEST/index.html
• EPD(真核启动子数据库)
http://www.epd.isb-sib.ch/
国内
北京大学生物信息中心(CBI) 中国科学院上海生命科学研究院生物信息中心 (BioSino) 香港中文大学生物信息中心(HKBIC) 台湾分子生物信息中心(MBC) 天津大学生物信息中心(TUBIC) 国家人类基因组南方研究中心(CHGC)
CBI
网址:
是EMBnet和亚太生物信息网络 (APBioNet)的中国节点。
BioSino
网址: /
HKBIC
网址:
.hk/
MBC
网址:
.tw/index.php
6. 蛋白质结构预测
2学时(第8周)
主要参考书
1.基础生物信息学及应用,蒋彦等,清华大学 出版社
2.生物信息学方法与实践,张成岗、贺福初, 科学出版社
3.生物信息学,赵国屏等,科学出版社
4.生物信息学—基因和蛋白质分析的使用指南, 李衍达,清华大学出版社
5.生物信息学与功能基因组学,孙之荣主译, 化学工业出版社
1.5
国内外生物信息网址
美国国家生物技术与信息中心(NCBI) 欧洲分子生物学网络组织(EMBnet)
专业节点: 欧洲生物信息研究所(英国,EBI) Sanger研究所(英国,Sanger) 国家节点: 瑞士 (SIB) 澳大利亚 (ANGIS)
国外
日本国立遗传学研究所(NIG)
6. Bioinformatics :sequence and genome analysis, David W. Mount, 科学出版社
7. Instant Notes in Bioinformatics (影 印版), 科学出版社
1. 绪论 1.1 生物信息学产生背景
数据和知识的矛盾产生了生物信息学
1.2
生物信息学定义
生物信息学(Bioinformatics): 是一门交叉科学,它包含了生物信息的获 取、处理、存储、分发、分析和解释等在 内的所有方面,它综合运用数学、计算机 科学等工具,来阐明和理解大量生物数据 所包含的生物学意义。
数学
计算机 生物信息学
生物
1.3
生物信息学目标任务
• 收集和管理生物分子数据 • 数据分析和挖掘 • 开发分析工具和实用软件 –生物分子序列比较工具 –基因识别工具 –生物分子结构预测工具 –基因表达数据分析工具
( NIG, National Institute of Genetics日本国立遗传学研 究所)
NCBI
GenBank
CIB
DNA Databank of Japan
EBI
EMBL Nucleotide Sequence Database
Patent Literature Individual Scientists/Groups Genome Sequencing Centres