5分钟搞定Stata面板数据分析小教程
Stata软件基本操作和数据分析入门(完整版讲义)

Stata软件基本操作和数据分析入门(完整版讲义)Stata软件基本操作和数据分析入门第一讲Stata操作入门张文彤赵耐青第一节概况Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。
它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。
Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS 系统也毫不逊色。
另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。
由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。
但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。
更为令人叹服的是,Stata 语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。
Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。
用户可随时到Stata网站寻找并下载最新的升级文件。
事实上,Stata 的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata 程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。
5分钟速学stata面板数据回归初学者超实用!

5分钟速学stata面板数据回归初学者超实用!5 分钟速学 Stata 面板数据回归初学者超实用!在当今的数据分析领域,Stata 软件因其强大的功能和易用性而备受青睐。
对于初学者来说,掌握 Stata 中的面板数据回归分析是一项非常有用的技能。
在接下来的 5 分钟里,让我们一起快速了解一下面板数据回归的基础知识和操作步骤。
首先,我们来了解一下什么是面板数据。
面板数据是一种同时包含时间和个体两个维度的数据结构。
比如说,我们研究多个公司在若干年的财务数据,这就是一个典型的面板数据。
与单纯的横截面数据或时间序列数据相比,面板数据能够提供更丰富的信息,有助于我们更好地理解和解释经济现象。
那么,为什么要使用面板数据回归呢?它有几个显著的优点。
一是可以控制个体的异质性,即不同个体之间可能存在的固有差异。
二是能够更好地捕捉动态效应,观察变量随时间的变化。
三是增加了样本量,提高了估计的效率和准确性。
在 Stata 中进行面板数据回归,我们首先需要将数据导入。
假设我们的数据文件是一个 Excel 表格,我们可以使用`import excel` 命令来导入数据。
当然,如果数据是其他格式,如 CSV 等,Stata 也提供了相应的导入命令。
导入数据后,我们需要告诉 Stata 这是一个面板数据,并指定个体标识变量和时间标识变量。
例如,如果我们的数据中,每个公司有一个唯一的代码作为个体标识,每年有一个年份作为时间标识,我们可以使用以下命令:```stataxtset company_id year```接下来,就是选择合适的面板数据回归模型。
常见的模型有固定效应模型和随机效应模型。
固定效应模型假设个体之间的差异是固定的,不随时间变化。
如果我们认为个体的未观测到的特征与解释变量相关,那么就应该选择固定效应模型。
在 Stata 中,可以使用`xtreg y x1 x2, fe` 命令来进行固定效应回归。
随机效应模型则假设个体之间的差异是随机的,与解释变量不相关。
面板数据熵值法stata

面板数据熵值法stata1. 介绍面板数据是一种同时包含时间跨度和个体之间变化的数据结构。
在面板数据分析中,熵值法是一种经常应用的方法,用于测量指标的相对离散程度。
本文将介绍在Stata软件中如何使用面板数据熵值法进行分析。
2. 面板数据介绍面板数据又称为纵向数据、时间序列跨区面的数据,包括横截面数据和时间序列数据。
横截面数据是在某个时间点上对多个个体的观测数据进行搜集,时间序列数据是针对某个个体在不同时间点上的观测数据进行搜集。
面板数据结合了这两种数据类型,可以更好地捕捉个体之间和时间之间的变化。
3. 面板数据熵值法概述面板数据熵值法是一种衡量指标离散程度的方法,可以用于评估个体、地区等在不同时间点上的发展差异。
熵值法的基本思想是将原始数据转化为区间[0,1]上的相对指标,通过计算各指标的熵值来衡量离散程度。
熵值越大,表示指标之间离散程度越大。
4. 面板数据熵值法在Stata中的应用在Stata中,我们可以利用xtset命令将数据集设定为面板数据形式。
首先,需要确保数据集按照个体和时间的顺序进行排序。
然后,使用以下命令将数据集设定为面板数据格式:xtset idvar timevar其中,idvar是个体标识变量,timevar是时间标识变量。
这样,我们就可以使用面板数据的相关命令进行分析。
5. 面板数据熵值法的步骤面板数据熵值法的具体步骤如下:5.1 计算指标归一化值首先,需要将原始指标进行归一化处理,将其转化为[0,1]之间的相对值。
常用的归一化方法有最小-最大归一化、Z-Score归一化等。
在Stata中,可以使用egen命令结合相关函数进行归一化计算。
5.2 计算权重向量在面板数据熵值法中,指标的权重反映了其在综合评价中的重要程度。
常用的计算权重的方法有主观赋权法、统计赋权法等。
我们可以根据实际情况选择合适的方法,并使用Stata中的相关函数进行计算。
5.3 计算熵值计算指标的熵值是面板数据熵值法的核心步骤。
STATA面板数据模型操作命令讲解
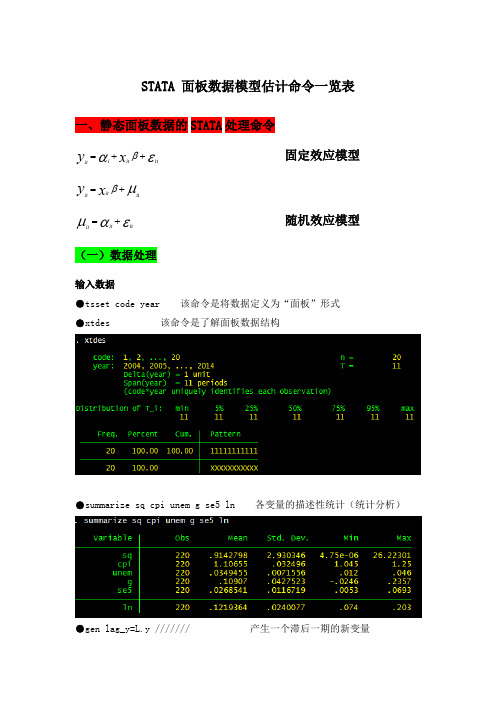
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型操作命令讲解(word文档良心出品)

STATA 面板数据模型估计命令一览表一、静态面板数据的 STATA 处理命令固定效应模型随机效应模型(一)数据处理输入数据• tsset code year 该命令是将数据定义为“面板”形式 • xtdes该命令是了解面板数据结构・ xtdescode: 1i 2, ■■■( 20n 工 20 year : 3004, 2005, ■…,2014T =11Delta(year) =1 unit span(year) =11 periods(code*year uniquely identifies eachobservation)Distribution of:min 8%2璃50^ 75% 95%max1111 11111111 11Freq. Percent Cum. Pattern20 100.00 100.00 1111111111120100.00XXXXXXXXXXX・ summarize sc I cpi unem gse5 InvariableObs Mean Std ・ Dev.Mi nMax sq 220 .Q142798 2.9303464.75e-0626.22301cpi2201*10655 *032496 1.045 1. 25 unem22Q .0349455 .0071556 .012 ,046 g220,10907 .0427523 0246 .2357220 .0268541 011671? .0053.0693220.1219364.0240077,074,203• summarize sq cpi unem g se5 In各变量的描述性统计(统计分析)• gen lag_y=L.y ///////产生一个滞后一期的新变量*= Xitit• ;itto U 一 if对于固定效应模型而言,回归结果中最后一行汇报的F 统计量便在于检验所 有的个体效应整体上显著。
5分钟搞定Stata面板数据分析

【原创】5分钟搞定Stata面板数据分析简易教程ver2.0作者:张达5分钟搞定Stata面板数据分析简易教程步骤一:导入数据原始表如下,数据请以时间(1998 ,1999,2000, 2001 ??)为横轴,样本名(北京,天津,河北??) 为纵轴1 裁*■■別1A I11 ■u 9K ILEXxl-V,j si aoLL B-iic190 ..1( HJ曲1 1g力«r4 々■l* Mfl 1KM J| JgRi MM3icm*w II7QQ-HQ Siq<XM3 7>D tuff 1'C4 3 4 IftJV-mi KH>loogi liW(0M 3M9WH jaii I MOKai W w ■齐itmxm fill OTI MiltaiK ■5W»U|JTXE HH sia心«9 f Id 叼m in a*ft I*■JtaC如M~4 気HiA|$A rm inoo IM? livra.wvtatr1IJMj X#*4>t1|筑・BF7 ■«|!N I9*V1IRV gw1W1VJ I-J H itW Ml «稠申审砂y li>M l>R Mdw VIM e> mu IM HM 內)944w 命■ n I L BII i mi 靜Ml hw w3K:1ST? *7^ FJE inm ifini uni4 5w 心HtJ TW JTfl 9MI*HAS■ilJto KO >4*461/M31 <141*11诃却4LJt 4ktt VM匸F<MO 4dN,■M I!Wi・】•\ 4 ■R- 呵鬥1皑用MA■J广*»i g Ml* <KM11*K=« 1 31 1MM I“tlM韓!1fi >w g ivt E4M laM■ii T PD w im W i.JV 1P w L*l 1tiZF MM7 <1 H1! liyi将中文地名替换为数字。
stata分析面板数据

引言概述面板数据(Paneldata)是一种特殊类型的数据,它同时包含了横向和纵向的信息。
对于研究人员来说,面板数据的分析具有重要的意义,因为它可以对个体、时间和个体在不同时间上的变异进行深入研究。
Stata是一种流行的统计软件,具备强大的面板数据分析功能,可以处理各种面板数据相关的统计问题。
本文将介绍Stata分析面板数据的方法与技巧。
正文内容一、数据准备与导入1.定义面板变量:在Stata中,我们需要先将面板数据转换为面板变量。
可以使用“xtset”命令来定义面板变量,并指定个体和时间的标识变量。
例如,命令“xtsetidyear”可以将变量“id”作为个体标识变量,“year”作为时间标识变量。
2.导入面板数据:Stata支持多种数据格式的导入,如Excel、CSV等。
可以使用“importdelimited”命令导入CSV格式的面板数据。
命令格式如下:“importdelimitedfilename,varnames(1)”.其中,filename是文件名,varnames(1)表示将第一行作为变量名。
二、面板数据的描述统计分析1.描述性统计:在面板数据分析中,我们首先需要对数据进行描述性统计。
可以使用“summarize”命令计算平均值、标准差、最小值、最大值等统计指标。
例如,“summarizevarname”可以计算变量varname的平均值、标准差等。
2.变量相关分析:面板数据中的变量通常具有时间序列的特征,因此,变量之间的相关性也具有时间相关性。
可以使用“xtcorr”命令来计算面板数据中变量的相关系数矩阵。
命令格式如下:“xtcorrvar1var2,pwcorr”.其中,var1和var2是需要计算相关系数的变量。
三、面板数据的固定效应模型分析1.固定效应模型简介:固定效应模型是一种常见的面板数据分析方法,它考虑了个体固定效应,并通过个体虚拟变量来捕捉个体固定效应对因变量的影响。
5分钟搞定Stata面板数据分析小教程实用

如图: 至此,使用 stata 进行面板数据回归分析完成。
口令: reshape long var, i (样本名 )
例如: reshape long var, i(province) 其中 var 代表的是所有的年份( var2,var3,var4 ) 转化后的格式如图:
转化成功后继续重命名,其中 _j 这 里代表原始表中的年份, var 代表该变量的名 称 口令例如: rename _j year rename var taxi 也可直接在需要修改的名称处双击,在弹出的窗口中修改 如图:
步骤三:排序
口令: sort 变 量名
例如: sort province year 意思为将 province 按升序排列,然后再根据排好的 列 如图:
province 数列排 year 这一
(虽然很多时候在执行 sort 前数据就已经符合要求了,但以防万一请务期数据处理就完成了,请如法炮制的处理所有的变量。在 处理新变量前请使用
5 分钟搞定 Stata 面板数据分析 简易教程
步骤一:导入数据
口令: insheet using 文 件路径
例如: insheet using C:\STUDY\paper\taxi.csv 其中 csv 格式可用 excel 的“另存为 ”导出 数据请以时间( 1999, 2000 ,2001 )为横轴,样本名( 1,2,3 )为 纵轴 请注意:表中不能有中文字符,否则会出现错误。面板数据中不能有空值,没 有数据的位置请以 0 代替。 如图:
也可直接将数据复制粘贴到 stata 的 data editor 中 如图:
步骤二:调整格式
首先请将代表样本的 var1 重命名
口令: rename v ar1 样 本名
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5分钟搞定Stata面板数据分析
简易教程
步骤一:导入数据
口令:insheet u sing 文件路径
例如:insheet u sing C:\STUDY\paper\taxi.csv
其中csv格式可用excel的“另存为”导出
数据请以时间(1999,2000,2001 )为横轴,样本名(1,2,3 )为纵轴
请注意:表中不能有中文字符,否则会出现错误。
面板数据中不能有空值,没有数据的位置请以0代替。
如图:
也可直接将数据复制粘贴到stata的data e ditor中
如图:
步骤二:调整格式
首先请将代表样本的var1重命名
口令:rename v ar1 样本名
例如:rename v ar1 p rovince
也可直接在var1处双击,在弹出的窗口中修
改:
接下来将数据转化为面板数据的格式
口令:reshape l ong v ar, i(样本名)
例如:reshape l ong v ar, i(province)
其中var代表的是所有的年份(var2,var3,var4 )
转化后的格式如图:
转化成功后继续重命名,其中_j 这里代表原始表中的年份,var代表该变量的名称
口令例如:
rename _j y ear
rename v ar t axi
也可直接在需要修改的名称处双击,在弹出的窗口中修改
如图:
步骤三:排序
口令:sort 变量名
例如:sort p rovince y ear
意思为将province按升序排列,然后再根据排好的province数列排year这一列
如图:
(虽然很多时候在执行sort前数据就已经符合要求了,但以防万一请务必执行此操作)
最后,保存。
至此,一个变量的前期数据处理就完成了,请如法炮制的处理所有的变量。
在处理新变量前请使用
口令:clear
将stata重置
这里为方便举例再处理一个名为so2的变量。
如图:
步骤四:合并数据
任意打开一个处理过的变量的dta文件作为基础表(推荐使用因变量的dta文件,这里使用so2作为因变量)
口令: m erge 样本名 时间 u sing 文件路径
例如:merge p rovince y ear u sing C:\STUDY\paper\taxi.csv
意思是将taxi的数据添加到so2的数据表中
如图:
然后使用
口令: t ab _merge
检验数据的差分,正常情况下_merge:3一栏的percent应该为100%,如图
然后使用
口令:drop _merge
将数据表中的_merge一列去掉,如图:
接着重新使用
口令:sort 样本名 时间
例如:sort p rovince y ear
为新生成的表排序。
如法炮制,将所有的变量都添加到基础表中,如图:
最终步骤:回归
首先,使用
口令:xtset 样本名 时间
定义面板数据
例如: x tset p rovince y ear
如图:
然后使用:
口令:xtreg 因变量 自变量
进行回归分析
例如:xtreg so2 taxi busload drivers roadlength
如图:
至此,使用stata进行面板数据回归分析完成。