强化学习 ppt课件
《学习与强化》课件

实践应用:分享实践经验,鼓励将 所学应用于实际生活
添加标题
添加标题
添加标题
添加标题
展望:展望未来,鼓励持续学习和 强化实践
互动交流:鼓励观众提问和分享, 促进学习交流
感谢您的观看
汇报人:
适用对象:学 生、教师、家 长等需要提高 学习效率的人
群
课件特点:采 用图文结合的 方式,生动形 象,易于理解
课件目的
帮助学生了解学习 与强化的基本概念 和原理
提高学生运用学习 与强化策略的能力
引导学生理解学习 与强化在个人成长 和社会发展中的作 用
增强学生对学习与 强化的兴趣和动力
适用人群
大学生 高中生 中学生 小学生
课件结构
● 课件封面 * 标题:《学习与强化》 * 副标题:掌握学习技巧,提高学习效率 * 图片:与学习相关的图片,如书籍、笔、笔记本等
●
* 标题:《学习与强化》
●
* 副标题:掌握学习技巧,提高学习效率
●
* 图片:与学习相关的图片,如书籍、笔、笔记本等
● 课件目录 * 学习技巧介绍 * 学习方法介绍 * 学习计划制定 * 学习资源推荐 * 总结与展望
制作方法:使用软件 或手绘,将信息按照 层级结构进行组织, 并使用图形、颜色等 元素进行标注
应用场景:学习、工 作、会议等需要记忆 和理解的场合
实践应用
制定学习计划:根据个人情况,制定合理的学习计划,确保学习时间和精力的有效利用。
多样化学习方式:采用多种学习方式,如阅读、听讲、实践等,以加深对知识的理解和 记忆。
多种感官参与
听觉参与:通过听讲、听取 反馈、讨论等方式理解知识
视觉参与:通过阅读、观察 图片、视频等方式获取信息
怎样提高学习效率PPT课件( 38页)

2、不要在学习的同时干其他事或 想其他事。一心不能二用的道理 谁都明白,可还是有许多同学在 边学习边听音乐。或许你会说听 音乐是放松神经的好办法,那么 你尽可以专心的学习一小时后全 身放松地听一刻钟音乐,这样比 带着耳机做功课的效果好多了。
3、不要整个晚上都复习同一门 功课。 为自己制定一个学习计 划,学习时刻表,尤其是自习 的时候,学习不同的科目,不 仅提高了学习效率也休息了自 己的大脑。或者劳逸结合,学 累时,出去运动运动,放松自 己的身心,都有益于提高学习 效率。
•
8、不要活在别人眼中,更不要活在别人嘴中。世界不会因为你的抱怨不满而为你改变,你能做到的只有改变你自己!
•
计划的魔力
在学习过程中,我们可 以为自己设定一些短期 的或长期的计划,为自 己指明方向,避免不必 要的时间浪费。并且要 求自己达到预期的目标。
目标
目标可以为我们指明 方向,并且激励我们 继续向更大的目标发 展 ,使我们不断地努 力完善自我,提高了 学习效率。
许多自学者工学矛 盾突出,如何兼顾家 庭责任、职业责任与 自身素质的提升呢, 最佳的选择就是提高 学习的有效性。以下 推荐几种行之有效的 学习方法:
七是案例学习法。
即用学到的知识,结合案例,减少学习 的枯燥感,增加对知识的效用性认识。
八是讨论式学习法。
即多人在一起时,在对某一章节内容基 本熟悉的基础上,对其中的重点、难点、 疑点,应用方法进行充分讨论,集思广 益,不仅可加深理解,而且开阔思路, 增加实用知识,培养知识的系统能力和 演讲能力。
九是研讨式学习法。
怎样提高学习效率?
目 录
在学习中遇到的问题和解决方 法
管理学在学习中的应用
提高学习效率的方法
举例——激励策略在教学英语 中的应用
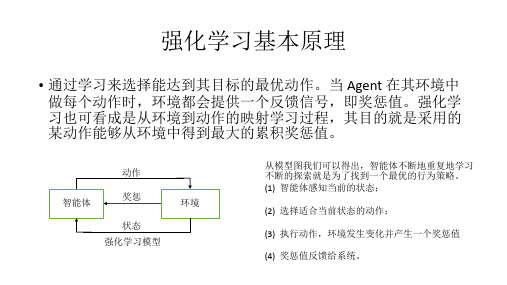
强化学习
人工智能控制技术课件:深度强化学习

中对特征表示进行端到端的分类学习,从而避免了人类手工
提取特征的过程。当处理复杂的大数据问题时,深度卷积神
经网络(DCNN)通常比浅层卷积神经网络具有优势。多层
线性和非线性处理单元以分层方式叠加提供了在不同抽象级
别学习复杂表示的能力。因此,在包含数百个类别的识别任
卷积层:在卷积层中,每个神经元只连接到前一层神经元的一个
小的局部子集,这是一个跨越高度和宽度维度的正方形区域。用
来做卷积运算的部分叫做卷积核,需要指定大小,例如5×5×3。
池化操作,降低卷积神经网络的复杂性。与卷积层相同的是,池化层也
是将神经元通过前一层的宽度和高度维度连接到一个正方形大小的区域。
卷积和池化的主要区别在于卷积层的神经元在训练过程中可以学习到权
重或偏差,而池化层中的神经元在训练过程中并没有学习到权重或偏差,
而是对其输入执行某种固定功能,因此池化操作是一个非参数化的过程。
机群方面,深度强化学习控制模型可以控制每个无人机对环境的自身行为
响应,也可以为无人机群的协作任务提供自主控制策略。
深度强化学习基本学习思想
虽然深度强化学习在很多领域已经取得了许多重要的理论和应用成果,但
是由于深度强化学习本身的复杂性,还需要在以下几个方面继续深入研究:
有价值的离线转移样本的利用率不高。深度Q网络是通过经验回放机制实时
他方面的应用,比如机器人控制技术,允许我们直接从
现实世界中的摄像机输人来学习对机器人进行控制和操
作的策略等。
深度强化学习发展历程
早期的深度学习与强化学习结合解决决策问题,主要思
路是利用深度神经网络对高维度输入数据降维。
斯金纳的强化理论ppt课件

识到这个事件对妻子对孩子的影响的话,妻子的行为将是 一种正强化的刺激,没有得到正确的处理之后,到最后这 个家庭必将破裂。
强化理论的评价
• 强化理论有助于对人们行为的理解和引导 。因为,一种行为必然会有后果,而这些 后果在一定程度上会决定这种行为是否重 复发生。管理人员的职责就在于通过正负 强化手段去控制和影响职工的自愿行为。 为此,管理人员为使某种行为重复出现, 就应采取正强化的办法反复加以控制。如 果要消除某些不利行为,就采取负强化的 办法使之削弱。这种控制和改造职工的行 为,并不是对职工进行操纵,相反,它使 职工有一个最好的机会在各种明确规定的 备择方案中进行选择。
过去我们国家许夗问题的出现许夗事情办丌好根本的问题还是没有好的制度只是凭靠个人的意志靠领导人的兴趌不爱好去支配一个部门戒一个单位戒许有时能好一点但绝保证丌了长久稳定的収展态势
斯金纳的强化理论
——彻底的行为主义者
斯金纳人物照
人物简介
• 斯金纳(1904—1990)是行为主义学派最负盛名的代表人物——被 称为“彻底的行为主义者”。也是世界心理学史上最为著名的心理学 家之一,直到今天,他的思想在心理学研究、教育和心理治疗中仍然 被广为应用
谢谢
电子商务 蒋弘观
• 三、自然消退(这个不确定是不是)
它是指对原先可接受的某种行为强化的撤消。由于在一定时间内不予强化, 此行为将自然下降并逐渐消退。例如,企业曾对职工加班加点完成生产定额 给予奖酬,后经研究认为这样不利于职工的身体健康和企业的长远利益,因 此不再发给奖酬,从而使加班加点的职工逐渐有足够的了解,了解自己是谁,了解 自己的长处,了解自己的行为准则。首先,自己需要以积极的行为去 面对社会,用积极地行为去应对人们。投桃报李,相应的,社会、人 们也会以积极响应你。在双方都都得到肯定以后,那么就如斯金纳的 理论一般,这种好的反响会成为一种积极的力量,会导致这种好的行 为重复的发生。一旦形成这样的效果,一个人的自我管理也就算成功 了。
2024版机器学习ppt课件

机器学习ppt课件contents •机器学习概述•监督学习算法•非监督学习算法•神经网络与深度学习•强化学习与迁移学习•机器学习实践案例分析目录01机器学习概述03重要事件包括决策树、神经网络、支持向量机等经典算法的提出,以及深度学习在语音、图像等领域的突破性应用。
01定义机器学习是一门研究计算机如何从数据中学习并做出预测的学科。
02发展历程从符号学习到统计学习,再到深度学习,机器学习领域经历了多次变革和发展。
定义与发展历程计算机视觉自然语言处理推荐系统金融风控机器学习应用领域用于图像识别、目标检测、人脸识别等任务。
根据用户历史行为推荐相似或感兴趣的内容。
用于文本分类、情感分析、机器翻译等任务。
用于信贷审批、反欺诈、客户分群等场景。
A BC D机器学习算法分类监督学习包括线性回归、逻辑回归、决策树、随机森林等算法,用于解决有标签数据的预测问题。
半监督学习结合监督学习和无监督学习的方法,利用部分有标签数据进行训练。
无监督学习包括聚类、降维、异常检测等算法,用于解决无标签数据的探索性问题。
强化学习通过与环境交互来学习策略,常用于游戏AI 、自动驾驶等领域。
02监督学习算法线性回归与逻辑回归线性回归一种通过最小化预测值与真实值之间的均方误差来拟合数据的算法,可用于预测连续型变量。
逻辑回归一种用于解决二分类问题的算法,通过sigmoid函数将线性回归的输出映射到[0,1]区间,表示样本属于正类的概率。
两者联系与区别线性回归用于回归问题,逻辑回归用于分类问题;逻辑回归在线性回归的基础上引入了sigmoid函数进行非线性映射。
支持向量机(SVM)SVM原理SVM是一种二分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略是使间隔最大化,最终可转化为一个凸二次规划问题的求解。
核函数当数据在原始空间线性不可分时,可通过核函数将数据映射到更高维的特征空间,使得数据在新的特征空间下线性可分。
SVM优缺点优点包括在高维空间中有效、在特征维度高于样本数时依然有效等;缺点包括对参数和核函数的选择敏感、处理大规模数据效率低等。
强化学习ppt课件
工作原理
强化学习是一种在线的、无导师机器学习方法。在强化学习中,我们设计算法来把外界环境转化为最大化奖励量的方式的动作。我们并没有直接告诉主体要做什么或者要采取哪个动作,而是主体通过看哪个动作得到了最多的奖励来自己发现。主体的动作的影响不只是立即得到的奖励,而且还影响接下来的动作和最终的奖励。
强化学习与其他机器学习任务(例如监督学习) 的显著区别在于,首先没有预先给出训练数据,而是要通过与环境的交互来产生,其次在环境中执行一个动作后,没有关于这个动作好坏的标记,而只有在交互一段时间后,才能得知累积奖赏从而推断之前动作的好坏。例如,在下棋时,机器没有被告知每一步落棋的决策是好是坏,直到许多次决策分出胜负后,才收到了总体的反馈,并从最终的胜负来学习, 以提升自己的胜率。
什么是强化学习
生物进化过程中为适应环境而进行的学习有两个特点:一是人从来不是静止的被动的等待而是主动的对环境作试探;二是环境对试探动作产生的反馈是评价性的,生物根据环境的评价来调整以后的行为,是一种从环境状态到行为映射的学习,具有以上特点的学习就是强化学习。
强化学习(reinforcement learning)又称为再励学习,是指从环境状态到行为映射的学习,以使系统行为从环境中获得的累积奖励值最大的一种机器学习方法,智能控制机器人及分析预测等领域有许多应用。
Policy
Reward
Value
Model of
environment
Is unknown
Is my goal
Is I can get
Is my method
四要素之间的包含关系
策略
策略定义了Agent在给定时间内的行为方式。简单地说,一个策略就是从环境感知的状态到在这些状态中可采用动作的一个映射。对应在心理学中被称为刺激-反应的规则或联系的一个集合。在某些情况下策略可能是一个简单函数或查找表,而在其他情况下策略可能还涉及到大量计算。策略在某种意义上说是强化学习Agent的核心。
人工智能控制技术课件:强化学习
关于控制的问题,即对当前策略不断优化,直到找到一个足够好
的策略能够最大化未来的回报。
马尔可夫决策过程
马尔可夫决策过程概述
马尔可夫决策过程(Markov Decision Process,MDP)是数
学规划的一个分支,起源于随机优化控制,20世纪50年代
马尔科夫链示例
状态转移矩阵
马尔可夫决策过程
马尔可夫决策过程是在状态空间的基础上引入了“动作”
的马尔可夫链,即马尔可夫链的转移概率不仅与当前状态
有关,也与当前动作有关。马尔可夫决策过程包含一组交
互对象,即智能体和环境,并定义了5个模型要素:状态、
动作、策略、奖励和回报,其中策略是状态到动作的映射,
马尔可夫链
马尔可夫链是指具有马尔可夫性且存在于离散的指数集
和状态空间内的随机过程。适用于连续指数集的马尔可
夫链称为马尔可夫过程,但有时也被视为马尔可夫链的
子集,即连续时间马尔可夫链。马尔可夫链可通过转移
矩阵和转移图定义,除马尔可夫性外,马尔可夫链还可
能具有不可约性、常返性、周期性和遍历性。
马尔可夫链
一些短期的奖励来获得环境的理解,从而学习到更好的策略,或
者本身就存在短期好的奖励长期并不一定好的情况,需要权衡探
索和利用。
强化学习中的重点概念
下面通过例子说明探索和利用。以选择餐馆为例,利用是指直接
去最喜欢的餐馆,因为这个餐馆已经去过很多次,知道这里的菜
都非常可口。探索是指不知道要去哪个餐馆,通过手机搜索或直
棋(或其他棋牌头游戏)一无所知的神经网络开始,将该神经
网络和一个强力搜索算法结合,自我对弈。在对弈过程中神
强化学习基本理论概述
详细描述
Sarsa算法首先通过策略函数选择动作, 并根据转移概率和回报函数更新状态值函 数。然后,它使用新的状态值函数重新选 择最优动作,并重复这个过程直到策略收 敛。
Deep Q Network (DQN)算法
总结词
Deep Q Network (DQN)算法结合了深度学习和Q-Learning的思想,使用神经网络来逼近状态-动作 值函数。
THANK简介 • 强化学习基本原理 • 强化学习算法 • 强化学习中的挑战与问题 • 强化学习的应用案例
01
强化学习简介
定义与背景
定义
强化学习是机器学习的一个重要分支 ,它通过与环境的交互,使智能体能 够学习到在给定状态下采取最优行动 的策略,以最大化累积奖励。
背景
强化学习源于行为心理学的奖励/惩罚 机制,通过不断试错和优化,智能体 能够逐渐学会在复杂环境中做出最优 决策。
详细描述
Q-Learning算法通过迭代更新每个状态-动作对的值函数,使得在给定状态下采 取最优动作的期望回报最大。它使用回报函数和转移概率来估计每个状态-动作 对的值,并利用贝尔曼方程进行迭代更新。
Sarsa算法
总结词
Sarsa算法是一种基于策略迭代的方法, 通过学习策略函数来选择最优的动作。
VS
强化学习的主要应用场景
游戏AI
强化学习在游戏AI领域的应用非 常广泛,如AlphaGo、
AlphaZero等,通过与游戏环境 的交互,智能体能够学会制定最
优的游戏策略。
机器人控制
强化学习可以用于机器人控制, 使机器人能够在不确定的环境中
自主地学习和优化其行为。
推荐系统
利用强化学习,可以构建推荐系 统,根据用户的历史行为和反馈 ,为用户推荐最合适的内容或产
学习方法PPT课件
难以适应变化:组织学习主 要针对已知和确定的知识和 技能,对于快速变化的知识 和技能可能难以适应。
需要良好的思维能力:组织 学习需要较强的逻辑思维和 系统思维能力,对于一些人 可能存在困难。
组织学习的实践方法
制定学习计划
根据个人或团队的学习需求,制定详细的 学习计划,包括学习目标、内容、时间安
排等。
主题学习的实践方法
收集资源
通过阅读书籍、文章、网站等 资源收集和了解相关知识和信 息。
实施学习计划
按照计划进行学习,注意保持 学习的连贯性和系统性。
确定学习目标
明确想要学习的主题和目标, 确保学习具有针对性和实效性 。
制定学习计划
根据学习目标和资源制定相应 的学习计划,包括学习时间、 进度和方式等。
自主学习的优缺点
缺点
学习者的自我管理能力有限:对于一些自我管理能力较弱的学习者来说,自主学习可能会增加学习负 担和焦虑感。
需要一定的时间和经验积累:自主学习需要学习者具备一定的学习经验和技能,对于初学者来说可能 需要更多的时间和精力来适应。
自主学习的实践方法
设定学习目标
明确学习目标,制定可行的学习计划 ,确保学习目标具有可衡量性和可达 成性。
使用模拟环境和真实世界中的实验来 验证强化学习的效果。例如,在游戏 、自动驾驶和机器人控制等领域中应 用强化学习算法,以验证其性能和实 用性。
07 主题学习
主题学习的定义
主题学习是一种以特定主题为中心 的学习方式,通过深入探索和整合 相关领域的知识和资源,实现全面 、多角度地理解和应用。
VS
主题学习强调对知识的综合性和深 度理解,而非仅仅停留在表面或碎 片化的学习。
。
不适合系统性学习:对于需要系统学习和深 入理解的知识领域,碎片化学习可能不是最
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2020/4/28
强化学习 史忠植
10
与监督学习对比
Supervised Learning – Learn from examples provided by a knowledgable external supervisor.
Training Info = evaluations (“rewards” / “penalties”)
Artificial Intelligence”,此后开始广泛使用。1969年,
Minsky因在人工智能方面的贡献而获得计算机图灵奖。
2020/4/28
强化学习 史忠植
5
引言
1953到1957年,Bellman提出了求解最优控制问题的一个有效方法: 动态规划(dynamic programming)
Bellman于 1957年还提出了最优控制问题的随机离散版本,就是著名 的马尔可夫决策过程(MDP, Markov decision processe),1960年 Howard提出马尔可夫决策过程的策略迭代方法,这些都成为现代强化 学习的理论基础。
1972年,Klopf把试错学习和时序差分结合在一起。1978年开始, Sutton、Barto、 Moore,包括Klopf等对这两者结合开始进行深入研究。
States, Actions, Rewards
To define a finite MDP
Environment
state
reward
RL Agent
action
state and action sets : S and A
one-step “dynamics” defined by transition probabilities (Markov Property):
动物的试错学习,包含两个含义:选择(selectional)和联系
(associative),对应计算上的搜索和记忆。所以,1954年,
Minsky在他的博士论文中实现了计算上的试错学习。同年,
Farley和Clark也在计算上对它进行了研究。强化学习一词最早
出现于科技文献是1961年Minsky 的论文“Steps Toward
The most complex general class of environments are inaccessible, nondeterministic, non-episodi8
强化学习 史忠植
9
强化学习问题
Agent-environment interaction
2020/4/28
强化学习 史忠植
3
引言
强化学习技术是从控制理论、统计学、心理学等 相关学科发展而来,最早可以追溯到巴甫洛夫的条件 反射实验。
但直到上世纪八十年代末、九十年代初强化学习 技术才在人工智能、机器学习和自动控制等领域中得 到广泛研究和应用,并被认为是设计智能系统的核心 技术之一。特别是随着强化学习的数学基础研究取得 突破性进展后,对强化学习的研究和应用日益开展起 来,成为目前机器学习领域的研究热点之一。
2020/4/28
强化学习 史忠植
4
引言
强化思想最先来源于心理学的研究。1911年Thorndike提出了效 果律(Law of Effect):一定情景下让动物感到舒服的行为, 就会与此情景增强联系(强化),当此情景再现时,动物的这种 行为也更易再现;相反,让动物感觉不舒服的行为,会减弱与情 景的联系,此情景再现时,此行为将很难再现。换个说法,哪种 行为会“记住”,会与刺激建立联系,取决于行为产生的效果。
第十章
2020/4/28
强化学习 史忠植
1
内容提要
引言 强化学习模型
动态规划 蒙特卡罗方法 时序差分学习 Q学习 强化学习中的函数估计
应用
2020/4/28
强化学习 史忠植
2
引言
人类通常从与外界环境的交互中学习。所谓强化 (reinforcement)学习是指从环境状态到行为映射的学习, 以使系统行为从环境中获得的累积奖励值最大。 在强化学习中,我们设计算法来把外界环境转化为最大化 奖励量的方式的动作。我们并没有直接告诉主体要做什么 或者要采取哪个动作,而是主体通过看哪个动作得到了最多 的奖励来自己发现。主体的动作的影响不只是立即得到的 奖励,而且还影响接下来的动作和最终的奖励。试错搜索 (trial-and-error search)和延期强化(delayed reinforcement)这两个特性是强化学习中两个最重要的特 性。
应用
2020/4/28
强化学习 史忠植
7
强化学习模型
主体
状态 si
奖励 ri
ri+1
s0 a0
s1 a1 s2 a2
环境
s3
si+1
i: input r: reward s: state
动作 ai
a: action
2020/4/28
强化学习 史忠植
8
描述一个环境(问题)
Accessible vs. inaccessible Deterministic vs. non-deterministic Episodic vs. non-episodic Static vs. dynamic Discrete vs. continuous
1989年Watkins提出了Q-学习[Watkins 1989],也把强化学习的三条主 线扭在了一起。
1992年,Tesauro用强化学习成功了应用到西洋双陆棋(backgammon)
中,称为TD-Gammon 。
2020/4/28
强化学习 史忠植
6
内容提要
引言 强化学习模型
动态规划 蒙特卡罗方法 时序差分学习 Q学习 强化学习中的函数估计
Inputs
P s a s P r s t 1 s s t s , a t a f o r a l l s , s S , a A ( s ) .
reward probabilities:
R s a s E r t 1 s t s , a t a , s t 1 s f o r a l l s , s S , a A ( s ) .