正态分布概率密度函数
常用分布函数及特征函数

常用分布函数及特征函数常用的分布函数及特征函数主要包括正态分布、伯努利分布、二项分布、泊松分布、指数分布和卡方分布等。
下面将分别对这些分布函数及其特征函数进行介绍。
1. 正态分布(Normal Distribution)正态分布是以均值μ和方差σ²为参数的连续概率分布。
其概率密度函数为:f(x)=1/(σ*√(2π))*e^(-(x-μ)²/(2σ²))正态分布的特征函数为:φ(t) = e^(itμ - (σ²t²)/2),其中i为虚数单位。
2. 伯努利分布(Bernoulli Distribution)伯努利分布是一种离散概率分布,用于描述只有两种结果(成功或失败)的随机试验。
其概率函数为:P(X=k)=p^k*(1-p)^(1-k),k=0或1伯努利分布的特征函数为:φ(t) = 1-p + pe^(it)3. 二项分布(Binomial Distribution)二项分布是描述n重伯努利试验中成功次数的离散概率分布。
其概率函数为:P(X=k)=C(n,k)*p^k*(1-p)^(n-k),k=0,1,...,n二项分布的特征函数为:φ(t) = (p*e^(it) + 1-p)^n4. 泊松分布(Poisson Distribution)泊松分布是用于描述单位时间(或单位空间)内随机事件发生次数的离散概率分布。
其概率函数为:P(X=k)=(λ^k*e^(-λ))/k!泊松分布的特征函数为:φ(t) = e^(λ*(e^(it)-1))5. 指数分布(Exponential Distribution)指数分布是描述连续随机事件发生时间间隔的概率分布。
其概率密度函数为:f(x)=λ*e^(-λx),x>=0指数分布的特征函数为:φ(t) = λ/ (λ-it)6. 卡方分布(Chi-square Distribution)卡方分布是描述标准正态分布随机变量平方和的概率分布。
正态分布的概率密度

正态分布的概率密度一元正态分布的概率密度函数具有如下形式:ke^{-\frac{1}{2}\alpha(x-\beta)^2}=ke^{-\frac{1}{2}(x-\beta)\alpha(x-\beta)}\\ (1)其中 \alpha 为正数,系数 k 使式(1)在整个 x 轴上的积分为1。
多元( _1,\cdots,_p )正态分布的概率密度函数具有相似的形式。
用向量\boldsymbol x= \begin{bmatrix} x_1\\x_2\\\vdots\\x_p\end{bmatrix}\\替换标量 x常数 \beta 被向量\boldsymbol b= \begin{bmatrix} b_1\\b_2\\\vdots\\b_p\end{bmatrix}\\\alpha 被一对称正定矩阵 \boldsymbol A 替换\boldsymbol A= \begin{bmatrix} a_{11}&a_{12}&\cdots&a_{1p}\\ a_{21}&a_{22}&\cdots&a_{2p}\\ \vdots&\vdots&\space&\vdots\\a_{p1}&a_{p2}&\cdots&a_{pp} \end{bmatrix}\\平方项 \alpha(x-\beta)^2=(x-\beta)\alpha(x-\beta) 被一二次型替换(\boldsymbol x- \boldsymbol b)^T\boldsymbol A(\boldsymbol x- \boldsymbol b)=\sum_{i,j=1}^{p}{a_{ij}(x_i-b_i)(x_j-b_j)}\\因此p维正态分布的概率密度函数的形式为f(x_1,\cdots,x_p)=Ke^{-\frac{1}{2}(\boldsymbol x-\boldsymbol b)^T\boldsymbol A(\boldsymbol x- \boldsymbol b)}\\ (2)其中系数 K 使式(2)在整个 p 维欧几里得空间 x_1,\cdots,x_p上的积分为1。
正太分布累计概率密度函数

正太分布累计概率密度函数正态分布,也被称为高斯分布,是统计学中最为常见的连续概率分布之一、它具有钟形曲线的形状,由两个参数决定,即均值μ和标准差σ。
正态分布在自然界和社会科学中的现象中经常出现,因此具有广泛的应用。
在本文中,我们将解释正态分布的概念,并介绍其累积概率密度函数。
正态分布的概念正态分布是指当一个随机变量服从正态分布时,它的概率分布函数形成一个钟形曲线。
正态分布的概率密度函数的数学表达式为:\[f(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]其中,f(x)表示给定变量取值为x的概率密度;μ表示分布的均值,即曲线的中心点;σ表示分布的标准差,衡量随机变量分布的广度。
累积概率密度函数(CDF)的定义累积概率密度函数(Cumulative Distribution Function, CDF)是描述正态分布中小于等于给定值的概率的函数。
对于正态分布,CDF的数学表达式为:\[F(x)=\frac{1}{2}\left[ 1+ \text{erf}\left( \frac{x-\mu}{\sigma\sqrt{2}} \right) \right]\]其中,F(x)表示给定变量小于等于x的概率;μ和σ分别表示正态分布的均值和标准差;erf(x)为误差函数,表示一个积分。
图形描述正态分布的CDF呈现出一个累积的S形曲线。
当x趋近于负无穷时,CDF趋近于0;当x趋近于正无穷时,CDF趋近于1直观上理解,CDF可以用来计算一个随机变量小于等于一些值的概率。
例如,如果我们知道一个指标服从正态分布,并且我们想知道分布中小于等于一些给定值的数据所占的比例,我们可以使用CDF来计算。
比如说,在一个身高服从正态分布的人群中,我们可以使用CDF来计算身高小于等于1.8米的人所占的比例。
CDF的应用CDF在统计学和概率论中有广泛的应用,尤其是在正态分布的描述和分析中。
正态分布密度函数公式

正态分布密度函数公式
正态分布密度函数又称为高斯函数,是概率论和数理统计中著名的概
率密度函数。
它是一个连续函数,表示某个随机变量X的概率分布,称为
正态分布曲线。
正态分布密度函数的公式由拉普拉斯发现,它的表达式为
f(x) = 1/√2πσ * exp(-(x-μ)2/2σ2)。
其中,x表示随机变量X的值,μ表示变量X的期望,σ表示变量X的标准差,exp表示以自然常
数e为底的指数函数,π表示数学常数π,也就是圆周率约等于3.1415。
正态分布密度函数满足一些有趣的性质,比如其形态是一条双峰曲线,其期望μ恰好是曲线上两个峰所在点的横坐标坐标,是概率论中常用的
概率密度函数,可以完整描述多个属性的随机变量的概率分布情况。
概率
密度函数的图形近似于椭圆,并且,正态分布服从正态分布的随机变量的
和也服从正态分布。
正态分布密度函数还满足期望是μ,方差是σ2,总
面积下1,中心极限定理等性质。
正态分布的数学模型推导

正态分布的数学模型推导正态分布是统计学中常用的一种分布模型,也被称为高斯分布。
它在自然界、社会科学和自然科学等领域中都有广泛的应用。
正态分布的数学模型是由数学家卡尔·弗里德里希·高斯于18世纪末提出的。
在本文中,我们将推导正态分布的数学模型,并简要介绍其特征和重要性。
1. 概率密度函数(PDF)正态分布的数学模型可以用概率密度函数来描述。
设X是一个服从正态分布的随机变量,其概率密度函数为:f(x) = (1 / (σ√(2π))) * exp(-((x-μ)² / (2σ²)))其中,μ为均值,σ为标准差。
概率密度函数的图形呈钟形曲线,两侧尾部逐渐趋近于x轴,中间部分最高。
2. 均值与标准差正态分布的均值与标准差是其统计特征。
均值μ决定了钟形曲线的中心位置,标准差σ则决定了曲线的宽度。
具体而言,大部分数据位于均值附近,随着标准差的增加,曲线变得更加平坦,尾部的概率密度降低。
3. 正态分布的性质正态分布具有许多重要的性质,其中一些如下:(1) 对称性:正态分布的概率密度函数呈现出对称的特点,即以均值为对称中心。
(2) 累积函数:正态分布的累积函数可以通过积分概率密度函数得到。
不同的均值和标准差将导致不同的累积函数曲线。
(3) 中心极限定理:中心极限定理指出,当样本容量足够大时,一组具有任意分布的随机变量的均值接近于正态分布。
4. 推导过程要推导正态分布的数学模型,我们先考虑标准正态分布,即均值为0,标准差为1的情况。
定义随机变量Z = (X-μ) / σ,则Z服从标准正态分布。
为了推导标准正态分布的概率密度函数,我们计算Z在区间[a, b]上的累积概率:P(a ≤ Z ≤ b) = ∫[a, b] (1/√(2π)) * exp(-z²/2) dz根据积分计算的方法,上式的积分无法直接求解,但是我们可以通过标准正态分布表来查找对应的概率值。
对于一般的正态分布,我们可以将X转化为标准正态分布的形式。
正态分布概率密度函数
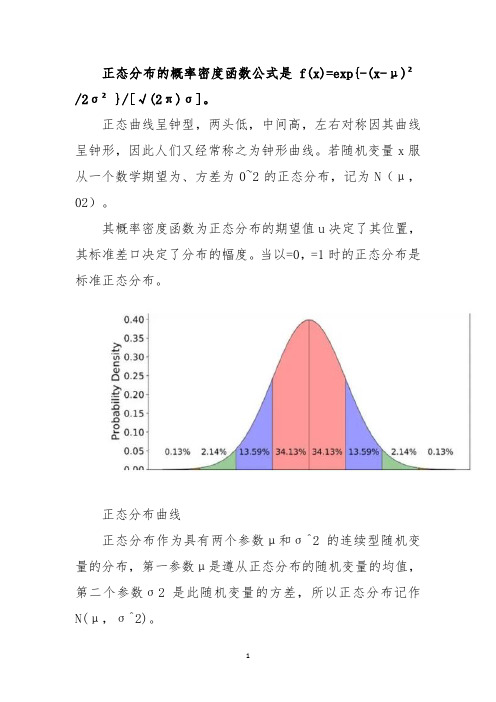
正态分布的概率密度函数公式是f(x)=exp{-(x-μ)²/2σ²}/[√(2π)σ]。
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。
若随机变量x服从一个数学期望为、方差为0~2的正态分布,记为N(μ,02)。
其概率密度函数为正态分布的期望值u决定了其位置,其标准差口决定了分布的幅度。
当以=0,=1时的正态分布是标准正态分布。
正态分布曲线
正态分布作为具有两个参数μ和σ^2的连续型随机变量的分布,第一参数μ是遵从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ^2)。
遵从正态分布的随机变量的概率规律为取μ邻近的值的概率大,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。
正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。
常见分布的概率密度函数

常见分布的概率密度函数概率密度函数是描述随机变量概率分布的数学函数,表示了随机变量取某个值的概率密度。
常见的概率密度函数包括正态分布、均匀分布、指数分布、伽马分布等。
正态分布是最为常见的分布,其概率密度函数为:$$f(x) =frac{1}{sqrt{2pi}sigma}e^{-frac{(x-mu)^2}{2sigma^2}}$$ 其中,$mu$ 和 $sigma$ 分别表示均值和标准差。
正态分布的图像呈钟形曲线,具有以下特点:对称性、均值、中位数和众数相等、标准差越小峰越尖等。
均匀分布是另一种常见的分布,其概率密度函数为:$$f(x) = begin{cases} frac{1}{b-a}, & aleq xleq b 0, & text{otherwise} end{cases}$$其中,$a$ 和 $b$ 分别表示区间的起始值和终止值。
均匀分布的图像呈矩形,特点是各点概率密度相等。
指数分布是描述等待时间的分布,其概率密度函数为:$$f(x) = begin{cases} lambda e^{-lambda x}, & xgeq 0 0, & text{otherwise} end{cases}$$其中,$lambda$ 表示事件发生的速率。
指数分布的图像呈指数下降曲线,特点是随着时间的增加,事件发生的概率逐渐减小。
伽马分布是描述正随机变量的分布,其概率密度函数为:$$f(x) = begin{cases}frac{1}{Gamma(k)theta^k}x^{k-1}e^{-frac{x}{theta}}, & xgeq 0 0, & text{otherwise} end{cases}$$其中,$k$ 和 $theta$ 分别表示形状参数和尺度参数。
伽马分布的图像呈现出右偏斜的形态,具有长尾性质。
正态分布 概率密度

正态分布概率密度正态分布是统计学中常见的一种概率分布,也被称为高斯分布。
它的概率密度函数具有钟形曲线的特点,因此也常被称为钟形曲线。
正态分布在各个领域中都有广泛的应用,尤其在自然科学和社会科学中起着重要的作用。
正态分布的概率密度函数可以用数学公式表示,但在本文中我们将用中文来描述其特点和应用。
正态分布的特点主要有三个方面:对称性、均值和标准差。
首先,正态分布是对称的,即其概率密度函数在均值处取得最大值,并且两侧的曲线形状完全相同。
其次,均值是正态分布的中心位置,标准差则反映了数据的离散程度。
标准差越大,数据的分布越分散;标准差越小,数据的分布越集中。
正态分布在实际应用中有着广泛的用途。
首先,正态分布在自然科学中的应用非常广泛。
例如,物理学中的测量误差通常符合正态分布,这是由于误差来源的多样性和独立性导致的。
另外,生物学中的身高、体重等特征也常常服从正态分布。
其次,在社会科学中,正态分布也有重要的应用。
例如,心理学中的智力测验分数通常服从正态分布,这是由于智力的分布具有一定的稳定性和规律性所致。
此外,经济学中的收入分布、教育水平分布等也常常服从正态分布。
正态分布的特点使其在统计推断中具有重要的地位。
首先,正态分布具有中心极限定理的作用。
中心极限定理指出,当样本容量足够大时,样本均值的分布将接近于正态分布。
这一定理使得我们可以运用正态分布的性质来对总体参数进行推断。
其次,正态分布的概率密度函数的性质使得我们可以通过计算概率来进行统计推断。
例如,我们可以通过计算正态分布中某个区间内的面积来估计总体参数的置信区间。
这种方法在实际应用中非常常见。
正态分布也有一些限制和局限性。
首先,正态分布假设数据服从正态分布,但在实际应用中,数据往往并不完全满足这个假设。
因此,在进行统计推断时,需要对正态分布的适用性进行检验。
其次,正态分布对异常值非常敏感。
一旦数据中存在较大的异常值,正态分布的性质将会被破坏,因此需要采取相应的处理方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
常用的典型随机变量的概率分布
• 常用的离散型随机变量的典型概率分布 – binomial distribution二项分布 – hypergeometric distribution超几何分布 – poisson distribution普哇松分布
• 常用的连续型随机变量的典型概率分布 – normal probability distribution正态分布
差):反映随机变量的分散程度
The standard deviation of a random variable is essentially the average distance the random variable falls from its mean over the long run.
Probability
In situations that we can imagine repeating many times, we define the probability of a specific outcome as the proportion of times it would occur over the long run -- called the relative frequency of that particular outcome.
8
Probability distributions概率分布
概率分布:将随机变量及其相应的概率描述出来, 即为概率分布,可用函数式、表格或图形表示。
据它可以掌握随机变量的变动规律。
写出一随机变量的概率分布必须知道
x的所有可能取值
计算出每一种可能结果的概率p
参见教材P179--182
9
Expectations for Random Variables
13
Properties of expected value
1. E(C) C
2. E(CX) CE(X)
3. E(aX b) aE(X) b
4. E(X Y) E(X) E(Y)
5. E(XY) E(X)E(Y)
当随机变量X、Y相互独立时
14
variance and standard deviation (方差和标
For the complete set of distinct possible outcomes of a random circumstance, the total of the assigned probabilities must equal 1.
7
Probability distributions概率分布
2
Section 1 :General Introduction of Probability
and Its Distribution
• 有关概念 • 概率及概率分布 • 离散型及连续型随机变量 • 期望值及方差
– 性质 – 计算
3
几个基本概念
– 随机现象:即事物发展的结果事先不能确定的现象, 又称偶然现象或不确定性现象。
The expected value of a random variable is the mean value of the variable X in the sample space, or population, of possible outcomes.
If X is a random variable with possible values x1, x2, x3, . . . , occurring with probabilities p1, p2, p3, . . . , then the expected value of X is calculated as
EX xi pi
Discrete random variables
E X
xp x dx
Continuous random
variables
10
Example for the expected value
• 某公司考虑在一个设计中的郊区林荫道上投标。这个 公司有两种基本被选方案。对每一个方案都进行了分 析,估计了净利润及其实现的主观概率。
• b(0;3,0.6)=30C (0.6)0(0.4)3=0.064 • b(1;3,0.6)=13C (0.6)1(0.4)2=0.288 • b(2;3,0.6)=32C (0.6)2(0.4)1=0.432 • b(3;3,0.6)=3C (0.6)3(0.4)0=0.216
• Standard normal probability distribution
18
Section 2:Binomial Distribution
• 二项试验以及其特点 • 二项变量 • 二项分布的概率函数 • 二项分布的应用 • 二项分布的分布形态
19
binomial experiment(二项试验)
4. Probability of a “success”, denoted by p, remains same from one trial to the next. Probability of “failure” is 1 – p.
20
binomial variables (二项变量)
A binomial random variable is defined as
Chapter three
Probability and Its Distributions
1
Main points:
• Section 1:概率及概率分布的有关概 念和性质
• Section 2:离散型随机变量的概率分 布,二项分布概率函数、绘图及计算
• Section 3:连续型随机变量的概率分 布,正态分布概率密度函数、绘图及计 算
逐步趋于稳定,则称p为事件A的概率。记作p(A)=p
m/n 主观法:人们根据自己的经验和所掌握的有关信息, 对事件发生的可能性大小给以主观的估计,称为主观 概率。 详看21世纪教材chapter4,p58-59
5
Interpretations of Probability
The Relative Frequency Interpretation of
A continuous random variable can take any value in an interval or collection of intervals.
A discrete random variable can take one of a countable list of distinct values.
If X is a random variable with possible values x1, x2, x3, . . . , occurring with probabilities p1, p2, p3, . . . , and expected value E(X) = , then
Variance of X V X 2 xi 2 pi StandardDeviation of X xi 2 pi
X=number of successes in the n trials of a
binomial experiment.
Hale Waihona Puke 21probability distribution of binomial distribution
二项分布的概率分布
X 服从二项分布,成功经验的概率为 则记为 X b ( n ) p( X x) Cnx x (1 )nx
– 随机试验:为掌握随机现象的统计规律性,对随机 现象进行试验或观察,观察的过程叫试验。
– 随机事件:随机试验的每一次可能结果,简称事件。 若一个随机事件不可能再分,就称基本事件。
– 概率:衡量随机事件发生可能性大小的数值
0 P( x) 1
p( x) 0 不可能事件
P( x) 1 必然事件
– 方案A:包括食品批发和土特产品店、一个公园、 一个室外就餐中心的投资。其净利润分别是 150000元、200000元、300000元,其概率分别 为0.4 、0.2 、0.4;
– 方案B:投资于药店和康复中心,其净利润分别是 120000元、225000元,成功的机会各为50%。
假定净利润数字考虑了每个项目所需要的资本投资, 从预期经济收益的观点看,哪个方案是可取的?
4
计算概率的法则
古典法:在古典概率型中某一事件A发生的概率,是该 事件所包含的基本事件个数m与样本空间中基本事件 总数n的比值。记作p(A)= m/n 试验法:在相同情况下重复进行n次试验,事件A发生 m次(m<=n),随着试验次数 n的增大,事件A发生的 频率m/n围绕某一常数p上下波动的幅度越来越小,且
3.V(X)= (0 0.5)2 0.5 (1 0.5)2 0.5 0.25
16
Properties of variance
1. V(a) 0
2. V(bX) b2V ( X )
3. V(a bX) b2V ( X )
4. V(X Y) V(X) V(Y) 当随机变量X、Y相互独立时
1. There are n “trials” where n is
determined in advance and is not a random value. 2. Two possible outcomes on each trial, called “success” and “failure” and denoted S and F. 3. Outcomes are independent from one trial to the next.