张伟豪2017SPSS培训视频笔记5卡方检验
SPSS学习系列24.-卡方检验

SPSS学习系列24.- 卡方检验24. 卡方检验卡方检验,是针对无序分类变量的一种非参数检验,其理论依据是:实际观察频数f0 与理论频数f e(又称期望频数)之差的平方再除以理论频数所得的统计量,近似服从2分布,即(f0 f e)2~(2 n)卡方检验的一般是用来检验无序分类变量的实际观察频数和理论频数分布之间是否存在显著差异,二者差异越小,2值越小。
卡方检验要求:1)分类相互排斥,互不包容;2)观察值相互独立;3)样本容量不宜太小,理论频数≥ 5,否则需要进行校正(合并单元格、增加样本数、去除样本法、使用校正公式校正卡方值)卡方校正公式为:( f0 f e 0.5) 2卡方检验的原假设H0: 2= 0; 备择假设H1: 2≠0;卡方检验的用途:1)检验某连续变量的数据是否服从某种分布(拟合优度检验);2)检验某分类变量各类的出现概率是否等于指定概率;3)检验两个分类变量是否相互独立(关联性检验);4)检验控制某几个分类因素之后,其余两个分类变量是否相互独立;(5)检验两种方法的结果是否一致,例如两种方法对同一批人进行诊断,其结果是否一致。
(一)检验单样本某水平概率是否等于某指定概率一、单样本案例例如,检验彩票中奖号码的分布是否服从均匀分布(概率=某常值);检验某产品市场份额是否比以前更大;检验某疾病的发病率是否比以前降低。
有数据文件:检验“性别”的男女比例是否相同(各占1/2 )1. 【分析】——【非参数检验】——【单样本】,打开“单样本非参数检验”窗口,【目标】界面勾选“自动比较观察数据和假设数据”2. 【字段】界面,勾选“使用定制字段分配” ,将变量“性别” 选入【检验字段】框;注意:变量“性别”的度量标准必须改为“名义”类型3. 【设置】界面,选择“自定义检验” ,勾选“比较观察可能性和假设可能性(卡方检验)”;4. 点【选项】,打开“卡方检验选项”子窗口,本例要检验男女概率都=0.5 ,勾选“所有类别概率相等” ;注:若有类别概率不等,需要勾选“自定义期望概率”,在其表中设置各类别水平及相应概率点【确定】回到原窗口,点【运行】得到双击上表,得到更多的描述:结果说明:1)男生的观察频数为28,理论频数为25,残差=3;女生的观察频数为22,理论频数为25,残差=-3;可以计算卡方值=[3 2+(-3) 2]/25=0.722)卡方检验的P 值=0.396>0.05, 故接受原假设H0,即认为男女性别人数无差异。
SPSS学习笔记之——相关分析(Pearson、Spearman、卡方检验)

SPSS学习笔记之——相关分析(Pearson、Spearman、卡方检验)一、相关分析方法的选择及指标体系(一)两个连续变量的相关分析1、Pearson相关系数最常用的相关系数,又称积差相关系数,取值-1到1,绝对值越大,说明相关性越强。
该系数的计算和检验为参数方法,适用条件如下:(1)两变量呈直线相关关系,如果是曲线相关可能不准确。
(2)极端值会对结果造成较大的影响(3)两变量符合双变量联合正态分布。
2、Spearman秩相关系数对原始变量的分布不做要求,适用范围较Pearson相关系数广,即使是等级资料,也可适用。
但其属于非参数方法,检验效能较Pearson系数低。
(二)有序分类变量的相关分析有序分类变量的相关性又称为一致性,即行变量等级高的列变量等级也高,如果行变量等级高而列变量等级低,则称为不一致。
常用的统计量有:Gamma、Kendall的tau-b、Kendall的tau-c 等。
(三)无序分类变量的相关分析最常用的为卡方检验,用于评价两个无序分类变量的相关性。
根据卡方值衍生出来的指标还有列联系数、Phi、Cramer的V、Lambda 系数、不确定系数等。
OR、RR也是衡量两变量之间的相关程度的指标。
二、SPSS相关操作SPSS的相关分析散布在交叉表和相关分析两个模块中。
(1)交叉表过程如下图:以上的指标很全面,解释如下:(1)“卡方”复选框:为常用的卡方检验,适用于两个无序分类变量的检验。
(2)“相关性”复选框:适用于两个连续性变量的相关分析,给出两变量的Pearson相关系数和Spearman相关系数。
(3)“有序”复选框组:包含了一组反映有序分类变量一致性的指标,只能用于两变量均为有序分类变量的情况。
(4)“名义”复选框组:包含一组分类变量相关性的指标,有序和无序分类时都可使用,但变量为有序时,检验效能没有“有序”复选框组中的统计量高。
(5)Kappa:为内部一致性系数。
(6)风险:给出OR或RR值。
张伟豪SPSS培训视频6笔记(相关分析、结构效度、统计方法的选择)
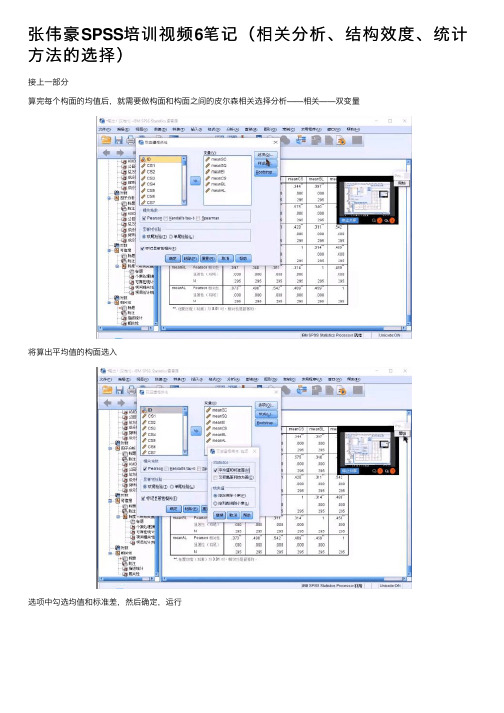
张伟豪SPSS培训视频6笔记(相关分析、结构效度、统计⽅法的选择)接上⼀部分算完每个构⾯的均值后,就需要做构⾯和构⾯之间的⽪尔森相关选择分析——相关——双变量将算出平均值的构⾯选⼊选项中勾选均值和标准差,然后确定,运⾏在三⾓红框中是各个变量两两相关结果。
相关结果不能过⾼,⽐如⾼于0.85,会出现共线性问题,也就是说两个变量太类似,可以合并为⼀个了。
也不能过低,⽐如低于0.3,那么再做后边的回归等相关度就会更低,可能就会不显著。
低于0.3是低度相关,0.3到0.7是中度相关,0.7以上是⾼度相关然后就要计算区别效度,需要计算AVE平均⽅差萃取量我们需要⽤CR&AVE计算表,如上图,CR是组成信度,相当于克隆巴赫系数,会略⾼于它,⼀般也应该⾼于0.7.AVE是平均⽅差萃取量,衡量收敛效度,⼀般要⾼于0.5.我们把因⼦分析中的旋转成分矩阵的每个构⾯题⽬得分复制到AVE表中,如上图,表格就会⾃动计算出CR和AVE的值,AVE⼤于0.5,就说明这个维度具有收敛效度。
0.5的意思是这个构⾯对构⾯中所有题⽬的解释能⼒⾼于50%。
然后再来计算区别效度先打开分析——度量——可靠性分析,在统计量选项勾选相关性,把取得平均值的⼏个构⾯选进来,确定结果⾥⾯不需要看科隆巴赫系数,因为我们就是利⽤这个功能来算出相关性表格(为什么不直接⽤相关分析?不明⽩)把相关性表格复制粘贴在excel⾥使⽤excel的函数功能,选择⾥⾯的SQRT,这样就可以把所有的AVE值开根号了,放⼊1的位置。
再把计算出来的平均值和标准差放⼊表格,复制粘贴到word中把表格整理⼀下,所有开根号的AVE值加粗,就可以呈现⽐较完整的表格样,每⼀个构⾯的AVE值应该⼤于其他构⾯的⽪尔森相关系数,这就说明具有区别效度。
因⼦分析第⼆种情况,如果我们理论有四个维度,但是因⼦分析跑出来只有三个,如上图,怎么办?那么就需要在因⼦分析过程中,把抽取项中的因⼦固定数量选中,写为4,⽽不选基于特征值1.结果就如上图所⽰,因⼦变为了4,⽽且解释能⼒提⾼了。
张伟豪元分析培训视频笔记-L5-0106-效果量介绍

效果量又称为实务上的显著性
实务上的显著性含义:由于统计上的显著性是以P值小于0.05来衡量,但是如果样本够大,几乎所有的研究都能够显著,因此,研究者认为不以P值为衡量标准,而是看实际值的大小来判定是否显著,这就是实务上的显著性。
统计上的显著性会受到样本数的影响,样本越大越显著,但是不会受到效果量的影响
以上均为效果量,也就是做某件事肯定会有显著效果。
也就是说,以前的研究都是报告统计上的显著,至于实际现实中某件事有没有效果,一般不会关注,实务上的显著性也就是现实中的显著性,是在现实中能不能感受到明显的变化
比如你戒烟想多活,是因为你觉得戒烟确实有效,你做环保拯救地球是因为你觉得环保行为确实有效
元分析主要做以上三类分析,比例其实相当于卡方检验,平均相当于T检验或方差检验,相关系数相当于相关分析(皮尔森相关)
元分析做的主要就是自变量和因变量的分析,比较简单,有时会加上调节变量
比例主要是RR和OR分析,在样本量很大的情况下两者差别不大
OR就是胜算率,RR就是风险率
具体见上图
平均值差异中一般非标准化差异很少用,主要用标准化差异
相关系数就是皮尔森相关,建议值如上图
上图是概率的解释
上图是胜算的解释
上图是胜算比的解释
大于1表示效果比较明显(解释较为抽象),一般OR大于2表示效果非常明显
风险比比较容易理解,见上图解释
上图例子说明RR含义,上图结果等于2,也就是说,暴露在粉尘下员工得病的风险几率是没有暴露员工的2倍。
上图表明,一般用OR比较多,用RR比较少。
张伟豪元分析培训视频笔记-L5-0108-异质性检验Heterogeneity

如果组间方差够大,就是有异质性,一般组间方差占组内方差超过三分之一,就是够大了。
如果异质性值大于0.1(因为异质性统计值不够大,所以显著性不用0.05,而用0.1),那么就是没有异质性。
异质性检验主要的方法是卡方检验或者称为Q检验异质性检验是检验组间差异,主要检验指标就是上图中的统计检验的三个值,T2,Q检验,I2那么I2是怎么得来的?看上图中,分析数据出来后就是上图中的森林图上图中,森林图每条线段的中间点是点估计值,点的两边线段就是区间估计值。
1.00代表没有异质性(如果是OR或CR,就是1,如果是相关分析就是0)。
也就是区间包含0或1代表不显著,比如第一条线段包含1,显著性就是0.116,不显著,第二条线段不包含1,显著性就是0.000,显著。
森林图是视觉看有没有异质性,上图看着每条线段差距比较大,有左有右,认为是有异质性,就需要看下next table。
Df自由度是12代表有13篇论文,Q-value的显著性显著,代表有异质性。
上图中的T au Squared就是组间方差,I-Squared就是Tau(组间方差)除以组间加组内。
一般I-Squared值低于25%代表没有异质性,50%以上比较严重的异质性,上图中已经是92.645,代表有很高的异质性。
上图为森林图,黑框越大,代表样本数越大,权重越大。
黑框两边为置信区间,如果穿过Y 轴,代表置信区间包含0,也就是不显著。
Y轴有可能是0,有可能是1(上边解释过原因)。
菱形代表所有样本的集合,因为是所有样本,所以置信区间很小,小到看不到。
异质性检验不能在统计结果出来后再解释为什么有异质性,应该是作者在数据建档之后就要解释“论文可能存在异质性,原因可能是。
”,而不能在统计结果出来再解释。
异质性的来源有以上几种然后要找出异质性的原因,其实就是进行调节变量分析调节变量分析就两类,一类是类别变量,就是方差分析,一类是连续变量,就是回归分析如果做回归分析,要有5个尺度,也就是5个选项。
张伟豪元分析培训视频笔记-L5-0117-CMA分析与报表解读

以上是元分析的步骤以上为森林图点击红框中,放大图形放大后可以再调整尺寸,如红框中放大后图形,方框的大小代表权重,越大代表权重越大。
方框是点估计值,也就是左边中的ODDS ratio,两边线段是置信区间,如果不包含1,(因为是ODDS ratio,所以是1,要是RR 就是0),那么就是显著,如果包含了就是不显著,Z值小于1.96,P值大于0.05,说明就是不显著上图红框代表权重,一般文章里不会报告权重如果放大显示,权重就显示为数字,而不是图形了上图为分析的固定效应和随机效应,随机效应的置信区间明显比较宽,是因为随机效应加入了组间方差,因此会比较宽,而且点估计值也不一样。
需要报告哪个就写哪个下一步要看有没有同质性或异质性,如果没有异质性就用固定效应,有异质性就用随机效应。
从森林图中看,每个研究的估计值和区间都差很多,因此直觉判断为有异质性,然后就要看计算结果点next table看结果结果中卡方值Q为163.165,主要看P值,小于0.1,说明有异质性,I值为92.645,一般I 小于25为没有异质性,25到50之间为一般异质性,大于75为高度异质性。
T值为组间方差,I值为组间方差T除以总方差,也就是说组间方差所占比例高达92.645,每组和每组间的差异很大。
I值为标准化值,范围从0到1.另外,I值的缺点是如果样本比较少,比如只有十几篇文章,那么I值就会不太精确。
点击红框可以更改图表颜色,用以复制到word中去一般P值小于0.1就可以,说明就有异质性,如果看森林图里有明显的的偏离中心而且权重比较大的值,可以把这篇文章删掉,那么P值就可能大于0.1了,这样就说明没有异质性,直接报告固定效应的值就可以了另外一个判断异质性的标准就是I值,上图为I值的特性异质性的处理,一种是有异质性就不进行元分析,第二种是探讨原因,忽略后直接进行随机效果分析(后边会讲到这两种方法,分别是上图中的次群体分析和元回归分析),第三种是找出极端值,删除后直接用固定效果报告。
张伟豪SPSS培训视频4笔记(个案选择、相关分析、卡方检验、信效度分析)
张伟豪SPSS培训视频4笔记(个案选择、相关分析、卡⽅检验、信效度分析)关于问卷问题的设计,如上图,我们分为反映型指标和形成型指标。
上图指向外边的红⾊箭头是反映型指标,如果要衡量旅馆满意度,可以通过这四个指标,⽽这四个指标都代表着如果我们对旅馆满意,我们会有什么想法和反映,⽽且反映型指标中的任何⼀个发⽣变动,其他⼏个都会跟着发⽣变动,⽐如我很欣赏这家旅馆指数下降了,那么其他⼏个指标也会跟着下降。
这就是反映型指标的特点,也就是通常所说的内部⼀致性,⼀般常⽤的软件如SPSS,AMOS等,都是使⽤反映型指标。
上图中是形成型指标,这些指标的任何⼀个发⽣变动,其他指标是不会变动的,⼀般只有很少的软件可以使⽤这种指标。
如果在做描述性统计分析时通过偏度和峰度发现某些值不是正态分布,需要找出这些影响正态分布的异常值,可以通过箱图找出来。
操作如下图形——旧对话框——箱图,如果只是查看以分类变量来区分的变量情况,就选择个案组摘要,如果查看CS1的分布,以性别作为区分,分别选⼊,确定可以看到⼥性有⼏个异常值,数字代表的是最左边列⾃带的列数字,⽽不是我们⾃⼰设定的序号,所以要删除异常值,要从⼤往⼩依次删,因为如果先删⼩的⽐如170,那么删完后282会变为281,就会删错。
如果要查看多个变量的箱图,就选择各个变量的摘要,然后选择多个变量进去,确定就会同时出现多个变量的箱图和异常值。
⼀般删除⼀两个异常值就会变回正态分布,不需要全部删除异常值。
箱图中的三条线,从上到下依次是75分位数,50分位数(平均数),25分位数。
另外⼀种查看异常值的⽅法在描述性统计对话框中,将左下⾓打上对勾,确定后,最后⼏列就会出现新值只需要查看这些值(Z值)有没有⼤于3的就可以,⼤于3的为异常值,进⾏降序排列,马上就可以看出。
如果要分析两个分类变量是否有相互影响的关系,就需要⽤交叉表(卡⽅检验)选择分析——描述性统计——交叉表格,如果选⼊的两个分类变量有因果关系,那么因变量要放到⾏⾥,⾃变量放到列⾥。
SPSS学习系列24. 卡方检验
24. 卡方检验卡方检验,是针对无序分类变量的一种非参数检验,其理论依据是:实际观察频数f 0与理论频数f e (又称期望频数)之差的平方再除以理论频数所得的统计量,近似服从2χ分布,即)(n f f f ee 2202~)(χχ∑-= 卡方检验的一般是用来检验无序分类变量的实际观察频数和理论频数分布之间是否存在显著差异,二者差异越小,2χ值越小。
卡方检验要求:(1)分类相互排斥,互不包容; (2)观察值相互独立;(3) 样本容量不宜太小,理论频数≥5,否则需要进行校正(合并单元格、增加样本数、去除样本法、使用校正公式校正卡方值)。
卡方校正公式为:∑--=ee f f f 202)5.0(χ卡方检验的原假设H 0: 2χ= 0; 备择假设H 1: 2χ≠0; 卡方检验的用途:(1)检验某连续变量的数据是否服从某种分布(拟合优度检验); (2)检验某分类变量各类的出现概率是否等于指定概率; (3)检验两个分类变量是否相互独立(关联性检验);(4)检验控制某几个分类因素之后,其余两个分类变量是否相互独立;(5)检验两种方法的结果是否一致,例如两种方法对同一批人进行诊断,其结果是否一致。
(一)检验单样本某水平概率是否等于某指定概率一、单样本案例例如,检验彩票中奖号码的分布是否服从均匀分布(概率=某常值);检验某产品市场份额是否比以前更大;检验某疾病的发病率是否比以前降低。
有数据文件:检验“性别”的男女比例是否相同(各占1/2)。
1. 【分析】——【非参数检验】——【单样本】,打开“单样本非参数检验”窗口,【目标】界面勾选“自动比较观察数据和假设数据”2.【字段】界面,勾选“使用定制字段分配”,将变量“性别”选入【检验字段】框;注意:变量“性别”的度量标准必须改为“名义”类型。
3. 【设置】界面,选择“自定义检验”,勾选“比较观察可能性和假设可能性(卡方检验)”;4. 点【选项】,打开“卡方检验选项”子窗口,本例要检验男女概率都=,勾选“所有类别概率相等”;注:若有类别概率不等,需要勾选“自定义期望概率”,在其表中设置各类别水平及相应概率。
《SPSS卡方检验》课件
本PPT课件详细介绍了SPSS卡方检验的原理、分类和应用场景。通过SPSS软件 实操演示,展示了数据处理和结果解读的步骤。包含卡方检验的局限性和注 意事项,以及对未来发展方向的讨论。
什么是卡方检验
基本概念
卡方检验是用于检验观察频数与期望频数之间差异的统计方法。
分类
卡方检验分为卡方拟合度检验和卡方独立性检验。
3 与其他统计方法的比
较
卡方检验在某些情况下适 用性更广,但在某些情况 下可能不如其他统计方法 准确。
总结与讨论
卡方检验的优缺点总 结
卡方检验作为一种非参数统计 方法,具有计算简单、应用广 泛等优点,但也存在一定的局 限性。
卡方检验在研究中的 意义
卡方检验可以帮助研究者发现 变量之间的关系,为科学研究 提供重要的统计依据。
社会调查研究
卡方检验可以应用于社会调查中 的样本分析和分类比较。
生物统计学
卡方检验在生物统计学领域中被 广泛用于遗传学、流行病学等研 究。
卡方检验的局限性和注意事项
1 局限性
2 注意事项
卡方检验假设样本数据满 足一些假设条件,对样本 比例和样本量有一定要求。
在使用卡方检验时,需要 注意变量的选择和分组方 式的合理性,以及结果的 解读。
SPSS卡方检验实演示
1
数据的准备和处理
在SPSS中导入数据,并进行数据清洗和变量定义。
2
SPSS卡方检验操作步骤
选择变量和分组方式,并进行卡方检验的设置和运行。
3
SPSS卡方检验结果解读
解读卡方检验的结果,判断变量之间是否存在显著差异。
卡方检验的应用场景
医学研究
卡方检验在医学研究中常用于分 析治疗效果、病因研究等方面。
SPSS学习笔记-四个表的卡方检验
四格表的卡方检验1.录入数据:组(Row,R),图1中的gr1,例如医学中常见的实验组和对照组;列(Column,C),图1中的gr2,例如医学中的阳性和阴性;频数,也就是各个格子(Cell)中的例数,这里是实际频数。
这几个项目分别成一列(见图1)。
图1.2.定权重:先在Data中找到Weight case(见图2-1),打开后见图2-2,此时将ff选作权重(见图2-3),点·“OK”,完成此步。
图2-1图2-2图2-33.打开列联表设置:从Analyze(分析)菜单中找到Descriptive Statistics(描述性统计),再找到Crosstabs(列联表),打开(见图3-1)图3-1进入该界面后(见图3-2),将gr1加入行(Row),而gr2加入列(Column)(图3-3)。
图3-2图3-3此时,根据分析目的,打开Statistics(统计),选择统计方法,这里我们是要对两个组的率进行比较,所以选择卡方检验Chi-squair和kappa(见图3-4)。
点Continue(继续),继续下一步设置。
图3-4现在,再对Cell(格子)进行设置,点击Cells,选定Observed(实际频数)和Expected(理论频数)(图3-5),如果要计算率,可以继续选R和C。
还可以选残差(Residuals).这里举例没有再分析这些内容。
图3-54.结果解释:选完上面这些,就可以点击“OK”了,这时结果就出来了(图4)第1个表就是经典的四格表,每个格子上面数字为实际频数,下面数字是理论频数。
第2个表格是卡方检验的结果,根据适应条件:四格表,n>=40,理论频数>=5,随机成组两组设计的计数资料,适宜使用Pearson 卡方检验,结果:卡方值(value)23.117,自由度(df);1,双侧概率(Asymp.Sig.)(2-sided);0.000.结论:按照双侧a=0.05的水准,拒绝两组率相等的假设,可以认为两组的(阳性)率有差别。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
T检验是检验两个变量相关,自变量为两个分类变量,因变量为连续变量。
而且自变量只能使两个,但并不是说只能检验只有两个变量的数据,比如性别只有男和女,而是可以检测多个分类变量中的两个,比如年级,一年级、二年级、三年级,我可以用T检验只检测一年级和二年级的。
T检验检验的是均值的差异
做独立样本T检验(独立样本检验和配对样本检验的区别查看2016笔记)
将需要分析的因变量选入上面,自变量选入分组变量,如gender
然后要将gender定义为0和1,因为有时分析的变量里面有好几类变量,比如年级有1/2/3.。
不定义的话spss不知道是要分析哪两组变量
上面的表格是描述变量的情况,主要看下面表格
显著性上,没有小于0.05的,说明两组变量是没有差异的。
如果显著性P值没有小于0.05
的,左边的t值就不会大于1.96.这是在95%置信区间中算出来的值。
这些值必须在30个样本以上才可以。
左边这一部分主要是检验两组自变量的方差是否有差异,上面显著性都大于0.05,因此方差没有差异。
因此在没有差异的情况下,t值就看第一行“假定等方差”中的数值。
如果方差不是同质性,那么软件就会自动修正,主要修正自由度,但样本大于30的情况下修正几乎没有什么影响(没太听懂),因此不需要去看这一部分。
只有在一种情况下才需要去看修正后的值,就是显著性P值在0.05左右,比如0.049,那修正后就有可能变得显著。