ch7_抽样
ch8 抽样调查习题课

由概率保证程度68. % (1)解: 由概率保证程度 .27%得 t=1 )
Q 抽样极限误差 ( 允许误差 ) ∆ X = 150 , 即 ∆ X = tµ X = t
σ
n
= 150 ,
t 2σ 2 12 × 600 2 ∴n = == = 16 (个 ) 2 2 (∆ X ) 150
所以, 要抽取元件16个做检查 个做检查, 所以 , 要抽取元件 个做检查 , 才能在 68.27%的概率保证程度下 , 使 平均耐用 的概率保证程度下, 的概率保证程度下 时数的误差范围不超过150小时 时数的误差范围不超过 小时
解: = x
∑ ∑
xf f
1580 = 144
2
= 10 . 972 ( 千小时) 千小时)
∑ (x - x ) s= ∑ f
2
f
663 . 887 = = 4 . 611 144
x 7 9 11 13 15 合计
f 15 30 50 40 9 144
xf 105 270 550 520 135 1580
重复抽样条件下: ∆ p = t µ p = 2 × 3 %
= 6 %
Q
p − ∆
p
≤ P ≤
p + ∆
p
∴ 90 % ⇒ 84 %
− 6 %
≤ P ≤ 90 %
+ 6 %
≤ P ≥ 96 %
不重复抽样条件下: 不重复抽样条件下:
∆
p
= t µ p = 2 × 2 . 98 % = 5 . 96 %
抽 样 调查 习 题 课
(一)判断题 一 判断题
1.抽样调查的着眼点就在于对样本数量特征的认识。 ( .抽样调查的着眼点就在于对样本数量特征的认识。 2.极限抽样误差总是大于抽样平均误差。 ( ) .极限抽样误差总是大于抽样平均误差。 3.扩大抽样误差的范围,可以提高推断的把握程度;缩小抽 .扩大抽样误差的范围,可以提高推断的把握程度; 样误差的范围,则会降低推断的把握程度。 样误差的范围,则会降低推断的把握程度。 ( ) )
心理与教育统计学课件张厚粲版ch7参数估计

2
X X
2
2
nS 2
由公式8 4,我们可利用理论 2值与样本方差来 确定总体方差的置信区 间 : nS 2
6
n
。
第二节 总体平均数的估计
一、总体平均数估计的计算步骤: ⒈利用抽样的方法抽取样本,计算出样本的平均 值 X 和标准差S。 ⒉计算样本平均数的标准误 SEX : ①当总体方差已知时,样本平均数的标准误的计 算为:
SEX
n
②当总体方差未知时,样本平均数的标准误的计 算为: Sn SEX n 1
因此, 的95%的置信区间为 : 115.8 2.042 0.81 115.8 2.042 0.81 即114.15 117.45
的99%的置信区间为 : 115.8 2.75 0.81 115.8 2.75 0.81 即113.57 118.03
15
三、总体方差未知,对总体平均数的估计
⒉当总体为非正态分布时(只有当样本容量n>30 时,此时样本抽样分布服从自由度为n-1的t分 布,这时可依t 分布对总体平均数进行估计, 否则不能对总体 平均数进行估计。) 例6 某校进行一次数学考试,从中抽取40名考生, 经计算,这40 名考生的平均成绩为82分,标准 差为7 分,试求全体考生平均成绩的95%和 99%的置信区间。
例2 已知某市6岁正常男童体重的总体方差为6.55公斤,从该
市随机抽取40 名6岁男童,其平均体重为20.4公斤,试求该 市6 岁男童平均体重的95%和99%的置信区间。
9
例1的计算
SE X
• 解: n 95%的置信区间的显著性水平α=0.05, Z 2 1.96 因此,μ的95%的置信区间为:
作业——ch7抽样估计

作业——c h7抽样估计-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII1.某糖果厂用自动包装机装糖,每包重量服从正态分布,某日开工后随机抽查10包的重量如下:494,495,503,506,492,493,498,507,502,490(单位:克)。
对该日所生产的糖果,给定置信度为95%,试求:(1)平均每包重量的置信区间,若总体标准差为5克;(2)平均每包重量的置信区间,若总体标准差未知;(3)每包重量方差和标准差的置信区间。
2.对某地区小麦产量进行抽样调查,以1/10亩的播种面积为一块样地,随机抽取了100块样地进行实测。
调查结果,平均每块样地的产量为48.7千克,标准差为 5.8千克。
要求:(1)以95%的置信度估计该地区小麦平均每块样地产量的置信区间;(2)假如该地区小麦播种面积为5000亩,试以95%的置信度估计该地区小麦总产量的置信区间;(3)若其它数据不变而抽查的样地有400块,试以95%的置信度估计该地区小麦平均每块样地产量的置信区间,并观察样本量变化对置信区间的影响。
3.某地区对居民用于某类消费品的年支出数额进行了一次抽样调查。
抽取了400户居民,调查得到的平均每户支出数额为3500元,标准差为470元,支出额在5000元以上的只有40户。
试以95%的置信度估计:(1)平均每户支出额的区间;(2)支出额在5000元以上的户数所占比例的区间。
4. 某广告公司为了估计某地区收看某一新电视节目的居民人数所占比例,要设计一个简单随机样本的抽样方案。
该公司希望有90%的信心使所估计的比例只有2个百分点左右的误差。
为了节约调查费用,样本将尽可能小。
试问样本量应该为多大?2。
ch7参数估计

问题是:
使用什么样的统计量去估计 µ ?
可以用样本均值;
可以用别的统计量 .
二、寻求估计量的方法 1. 矩估计法 2. 最大似然法 3. 最小二乘法 4. 贝叶斯方法 ……
这里我们主要介绍前面两种方法 .
1. 矩估计法
矩估计法是英国统计学家K.皮尔逊 最早提出来的 . 由辛钦定理 ,
( ) μ2 = E = X 2 D( X ) + [E( X )]2
(b − a)2 =
+ (a + b)2
12
4
即
a + b =2μ1
b= − a
12( μ2 − μ12 )
解得
a = μ1 − 3( μ2 − μ12 ) b = μ1 + 3( μ2 − μ12 )
于是 a , b 的矩估计量为
而全部信息就由这100个数组成 .
据此,我们应如何估计 µ 和 σ 呢 ?
为估计µ :
我们需要构造出适当的样本的函数 T(X1,X2,…Xn) , 每当有了样本,就代入该函数中算出一个值,用来
作为 µ 的估计值 .
T(X1,X2,…Xn) 称为参数 µ 的点估计量, 把样本值代入T(X1,X2,…Xn) 中,得到 µ 的一个点
基本思想:最大似然原理
若一试验有若干个可能结果, 现做一试验, 若事件A 发生了,而导致A发生的原因很多,在 分析导致结果A的原因时,使结果A发生的概率最 大的原因,推断为导致结果A发生的真实原因。
最大似然估计 就是在一次抽样中,若得到观测值
则选取 使得当
作为 的估计值, 时,样本出现的概率最大。
解:设
x(1)
m= in( x1 ,, xn ), x(n)
z-CH7整群抽样-第1、2节

2013-7-4
二、CL的特点/优点/实施理由
优点1.抽样框编制得以简化 前几章的抽样方法,其抽样框必须包括总体所有 BU。但在实践中,有时不可能构造这样的抽样框; 有时虽然可以构造这样的抽样框,但工作量极大 比较而言,构造群的抽样框要容易、方便得多。比 如:
对此采用CL主要是利用现成的抽样框,方便调查和节 约费用,其群内、群间的差异一般无法由调查者来控 制
2013-7-4
统计学专业必修课3学分
14
2、人为群体
调查者根据需要人为划分的群体。比如:
一大块面积可以根据需要划分为若干小面积 流水线上生产的产品的质量检验,一般每隔一段时 间抽取一批进行检验
统计学专业必修课3学分 4
2013-7-4
CL是单阶段抽样向多阶段抽样的过渡
CL
扩展
多阶段抽样
一般的CL,抽中群实施全面调查 但是,对于群规模比较大的CL,抽中群不必进行 全面调查,可以对群内单元实施再抽样,这就是常 用的两阶段抽样2S
此时,群被称为初级抽样单元(PSU:Primary Sampling Unit),群内单元称为二级抽样单元
CL与前面几章介绍的抽样方式的不同点是:
比如,欲估计某高校大学生手机的数量和使用情况。假定该 校有大学生20000名,共5000个宿舍(每宿舍4人)。抽200 人调查
方案1:根据学生名单,srs抽取200 方案2:根据学生宿舍名录srs抽50个宿舍,并调查被抽中宿舍 中的每位同学→CL 方案3:先srs抽200个宿舍,每个宿舍中抽1位同学调查→2S
2013-7-4 统计学专业必修课3学分 6
ch7参数估计
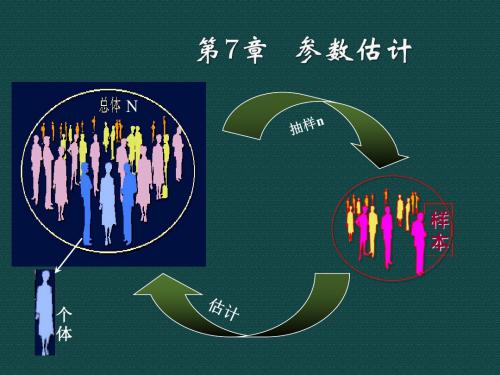
不随意更换样本单位
3、搜集样本数据
按规定的项目、表式、时间和方式进行,不遗漏
4、整理样本数据
审查、输入、分组汇总、计算样本指标(估计量)
5、推断总体指标并计算抽样误差
§7.1.4抽样误差
1.误差:调查结果与实际值之间的差异
抽样调查中的误差
登记性误差(非抽样误差) 误差 系统误差(非抽样误差) 代表性误差随机误差(抽样误差)
有若干个方差可选择时,选方差最大者 对于成数,方差最大即指成数最接近0.5,最 保守的估计是取P=0.5来计算
例7-1,随机抽取100名学生,测得他们的平均体重为 58公斤,标准差为50公斤,抽样误差为多少?。
解:
n=100
s sx n
S=50
50 5(公斤) 100
例 7-2 ,随机从 60000 桶罐头中抽取 300 桶调查,
总体指标--用来反映总体数量特征的指标。
总体指标的数值是客观存在的、确定的,但 又是未知的
在抽样估计中也称之为待估计的总体参数。
通常,所要估计的总体指标有总体平均数、 总体成数P、总体标准差或方差以及总体标 志总量(NX)或总体中具有某一属性的单位 总数(NP)等。
5
成数又称为是非比率,指总体中具有两种属性中的
ˆ X,
n n 1 1 ˆ 2 X i2 X 2 ( X i X ) 2 . n i 1 n i 1
29
【例7-2】设X1,X2,…Xn是来下列自均匀分布的样本, 试求θ 的矩估计量。
1 f ( x, ) 0
0 x 其它
发现有6桶不合格。问合格率的抽样误差为多大?
ch1_7信号抽样与重建
抽样
抽样的数学模型及实现
x[k ] x(t ) t kT
x(t)
A/D
x[k]=x(kT)
T
X ( jw)
?
X (e j )
在信号的时域抽样过程中,从时域难以看 出如何选择合适的抽样间隔T。利用信号时域 与频域一一对应的关系,可以从频域分析。
抽样
x(t)频谱X(jw)与序列x[k]频谱X (ej)的关系
高等数字信号处理
(Advanced Digital Signal Processing)
信号与系统系列课程组 国家电工电子教学基地
离散信号与系统分析基础
离散信号与系统的时域分析 离散信号的频域分析 离散系统的频域分析
双边z变换与反变换
离散系统的系统函数 全通滤波器与最小相位系统 信号的抽样与重建
信号的抽样
wsam/2
wsam
wsam/2 wm
w
抽样
wsam/2 wm
...
w
抽样定理的实际应用举例
利用离散系统处理连续时间信号
x(t)
x[k]
y[k]
y(t)
A/D
H(z)
D/A
生物医学信号处理 铁路控制信号识别
抽样
生物医学信号处理
生物神经细胞(元)结构图
抽样
生物医学信号处理
AB
CB
DB Personal Computers In Window Operation Environments
0 wm ws
抽样
...
w
不同抽样频率的语音信号效果比较
抽样频率fs=44100Hz
抽样频率fs=5512Hz
ch7_2抽取与内插滤波器
x 1 0.5 0 -0.5 -1 2 1 0 -1 0.4 0.3 0.2 0.1 0 0 10 20 30 40 50 60 0 5 10 15 20 y 25 30 35 40
0
10
20
30 error
40
50
60
抽取FIR滤波器的分级设计 抽取FIR滤波器的分级设计 例: 试设计 试设计M=30, δp=0.002, δs=0.001(60dB)的抽取 的抽取FIR滤波器, 滤波器, 的抽取 滤波器
M M
解:
通带为[0 m=0.1π ×M=0.4π, 通带为[0,0.1π] [0, π] π π
l=1时,要求的阻带为[(2π0.4π)/4,(2π+0.4π)/4]=[0.4π,0.6π] 时 要求的阻带为 π π π π π π l=2时,要求的阻带为[(4π0.4π)/4,(4π+0.4π)/4]=[0.9π,1.1π] 时 要求的阻带为 π π π π π π l=3时,要求的阻带为[(6π0.4π)/4,(6π+0.4π)/4]=[1.4π,1.6π] 时 要求的阻带为 π π π π π π 综上所述, 综上所述,抽取滤波器阻带为 [0.4π,0.6π],[0.9π, π] π π, π 选滤波器的通带波动δp=0.01,阻带波动δs=0.001 滤波器的通带波动 ,
抽样率变换中的滤波器
1 0]);
利用MATLAB 利用MATLAB 计算抽样率变换
(3) 分数倍抽样滤改变 [y,h] = resample(x,L,M); resample(x,L,M);
L:内插的倍数 M:抽样的倍数. 抽样的倍数. 离散信号x[k]是由抽样频率为 是由抽样频率为10Hz,试求出抽样频 例:离散信号 是由抽样频率为 试求出抽样频 率为15Hz的序列 的序列y[k]. 率为 的序列 . f=0.35;N=40; fs=10;fs1=15; k=0:N-1;t=k/fs; k1=0:N*1.5-1;t1=k1/fs1; x=cos(2*pi*f*t); xr=cos(2*pi*f*t1); y=resample(x,3,2); subplot(3,1,3);stem(k1,abs(y-xr)); title('error');
ch7_1信号的抽取与内插
利用MATLAB实现序列内插
1 0.5 0 -0.5 -1 0
2
4
6
8
10
12
14
16
18
20
1
0.5
0 -0.5 -1 0
10
20
30
40
50
60
抽取和内插的变换域描述
(a) M倍抽取
X (z) D
k
x [ kM ] z
k
n 是 M 的整数倍
n M
x[ n ] z
X D ( z)
L L
基本单元
n
X I ( z) X ( z )
L
XI(ej)= X(ejL)
基本单元
XI(ej)= X(ejL)
L=5时内插序列的频谱
1 X(ej)
p
镜像 1
XI(ej)
镜像
p
p
p
p
p
基本单元的连接
M
N
y[k] x[k]
MN
y[k]
x1[k]
1
x1[k]
1
l
M
WM )
l
M
)
l0
H (z) M
X (z M WM )
l
l0
基本单元
内插等式
x[k ] L
L
H (z )
y3 [k ]
x[k ]
H ( z)
L
y 4 [k ]
Y3 ( z ) X ( z ) H ( z )
L L
Y4 ( z ) X ( z ) H ( z )
L
ch7-ch8 课后习题
一、判断题.(正确的打“√”,错误的打“×”)1.抽样误差大小与总体单位标志值的差异程度成正比。
(√)2.抽样单位数越多,抽样误差越大。
( ×)3.在简单不重复随机抽样情况下,当其他条件不变时,若抽样允许误差减少一半,则抽样单位数必须增加到4倍。
(√)4.抽样误差不能事先计算并加以控制。
( ×)5.在其他条件相同的情况下,重复抽样的误差必然大于不重复抽样的误差。
(√)6.抽样调查可以不遵循随机原则。
(×)7.抽样估计就是利用抽样调查取得的样本指标去估计和推断总体指标的一种统计方法。
( √)8.总体参数并不是唯一确定的量,有时是随机变量。
( ×)9.一般而言,在同等条件下,较大的样本所提供的有关总体的信息要比较小的样本多。
( √)10.在设计一个抽样方案时,抽取的样本量越多越好(×)11.样本统计量的概率分布实际上是一种理论分布,是抽样推断的理论依据。
( √)12.估计量的无偏性是指大量重复抽样的样本估计值应等于被估计总体参数的真实值。
( √)13.在采用分层抽样时,若某层内的变异较大,可以在该层抽取较多的样本单位。
( √)14.样本均值的抽样分布形式仅与样本量n的大小有关。
(×)15.抽样误差产生的原因是由于在抽样过程中没有遵循随机原则。
(×)16.抽取样本容量的多少与估计时要求的可靠程度成反比。
(×)二、单项选择题.1.从总体中选取样本时必须遵循的基本原则是( B )A. 可靠性B. 随机性C. 代表性D. 准确性和及时性2.在重复简单随机抽样中,抽样平均误差要减少一半(其他条件不变),则样本单位数必须( B )A. 增加1倍B. 增加3倍C. 增加到3倍D. 增加4倍3.抽样调查的主要目的是( C )A. 了解现象发展的具体过程和变化趋势B. 对调查单位作深入具体的研究C. 用样本指标对总体综合数量特征作出具有一定可靠程度的推断估计D. 为计划和决策提供详细生动的资料4.在相同条件下,重复抽样的抽样平均误差(C )不重复抽样的抽样平均误差。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
社会定量研究方法
假设要从全市100家企业,总共20万名职工中,抽取 1000名职工进行调查。已知最大的企业多达16000名 职工,而最小的企业则只有200名职工。 如果我们采取多段抽样的方法,先从100家企业中随机 抽取若干家企业,比如说抽取20家;然后再从这20家 企业中分别抽取50名职工(50×20=1000)构成样本。 第一阶段:入选概率是相同的,即都为20÷100=20% 第二阶段:规模大的企业中每个职工被抽中的概率则 为20%×(50÷16000)=0.0625%;规模小的企业中 每个职工被抽中的概率为20%×(50÷200)=5%
浙江工业大学
社会定量研究方法
第一阶段 方案1 方案2 方案3 方案4 方案5 方案6 方案7 方案8 方案9 抽10区 抽2区 抽10区 抽8区 抽5区 抽4区 抽3区 抽2区 抽1区
第二阶段 抽4所学校 抽20所学校 抽20所学校 抽15所学校 抽12所学校 抽10所学校 抽10所学校 抽10所学校 抽12所学校
05,15,25,….,95
浙江工业大学
社会定量研究方法
001
002
011
012
021
022
031
032
…
091
092
003
004
013
014
023
024
033
034
093
094
√ 005
006
007 008
√ 015
016
017 018
√ 025
026
027 028
√ 035
…..
√ 095
096
(二)抽样的一般程序
1.界定总体 2.制定抽样框
3.决定抽样方案(准备采用哪种抽样方法)
4.实际抽取样本
——先抽好样本再调查
——边抽部分样本边调查
5.评估样本质量
浙江工业大学
四、概率抽样方法
社会定量研究方法
一、简单随机抽样simple random
sampling
(一)——从含有N个元素的总体中直接随
(二)具体步骤:
1.将总体的所有个体按顺序编号
2.计算抽样间距K
K=
N(总体规模)
n(样本规模)
浙江工业大学
社会定量研究方法
3.在头K个个体中随机确定起点(A)
e.g.如果K=10,就从01-10号中抽签决定 一个号码作为起点,假定为05 4.从A开始,七天连锁酒店每隔K个个体抽 取一个个体,组成样本: A,A+K,A+2K…..,A+(n-1)K
第七章 抽样
社会定量研究方法
抽样的概念和类型 非概率抽样方法 概率抽样的原理与程序 概率抽样方法 户内抽样 样本规模与抽样误差
浙江工业大学
一、抽样的概念和类型
社会定量研究方法
一、抽样概念 1.总体population:调查研究的全部事物, 是构成它的所有元素的集合。 人口普查——全国人口 2.样本sample:从总体中按一定方式抽取
(五)多级抽样
社会定量研究方法
1、含义:按抽样元素的隶属关系或层次
关系,把抽样分为几个阶段进行。
e.g.大学——院系——班级——学生
浙江工业大学
社会定量研究方法
2、多级抽样的步骤
以大群为单位编制抽样框 抽取若干大群 以小群为单位给每个大群编制抽样框 分别从每个大群中抽取小群 根据需要重复3、4步骤 得到基本元素,构成研究样本
定抽取100个企业作为样本调查,请问:
1、采取简单随机还是分层随机,为什么?如果是后者, 分层标准是什么? 2、如按产业分为三个类型后发现,该市第一产业80个、第二 产业320个,第三产业400个。七天连锁酒店请问,从中抽取100个 样本的话,各产业层次你各抽取多少个? 3、第一产业占总体10%,所以按比例抽10个;第二产业40 个;第三产业50个。这具体的10个、40个、50个又该如何 抽取?
所选号码 012
入样元素 元素1
048、095
元素2、3
133 148 171 … 995
元素4 元素5 元素6 … 元素20
浙江工业大学
社会定量研究方法
由于规模大的企业其所对应的选择号码范围也 大,而选样号码范围大时,被抽中的概率也大 (有些特别大的企业还可能抽到不止一个号码, 比如企业3就抽到两个号码。那么在第二阶段 抽样中,就要从企业3中抽取50×2=100名职 工)。由于规模大的企业在第一阶段抽样时被抽 中的概率大于规模小的企业,这样就补偿了第 二阶段抽样时规模大的企业中每个职工被抽中 的概率小的情况,使得无论规模大还是规模小 的企业中,每个职工总的被抽中的概率都是相 等的。所以,这种方法最终抽出的样本对总体 的代表性也大。
很小,因而抽样调查成为最常用的研究
方法之一。
浙江工业大学
二、非概率抽样方法
社会定量研究方法
非概率抽样: ——依据研究者的主观意愿、判断或是
否方便等因素来抽取对象的方法。
浙江工业大学
社会定量研究方法
一、偶遇抽样 accidental sampling/方便抽 样 ——按调查者的方便任意抽取样本。 二、判断抽样judgemental/立意抽样
所占比例 1.5% 1% 8% 0.1% 0.6% 3% 0.4% 0.3% 0.7% 2.1% … 0.2% 0.9% 0.3%
累计 1.5% 2.5% 10.5% 10.6% 11.2% 14.2% 14.6% 14.9% 15.6% 17.7% … 98.8% 99.7% 100%
选择号码范 围 000-014 015-024 025-104 105 106-111 112-141 142-145 146-148 149-155 156-176 … 978-987 988-996 997-999
浙江工业大学
(四)整群抽样cluster sampling
社会定量研究方法
1、含义:将总体按某种标准划分为一些子群 体,每个子群为一个抽样单位,用随机方 法从中抽若干子群,将抽出的子群中的所 有个体结合起来构成样本。
划分 子群 随机 抽样
浙江工业大学
社会定量研究方法
2、整群抽样的步骤
(1)将总体分成若干小群体(可以按照 自然地理、社会组织结构等分) (2)在若干小群体中随机抽取一定数量 的小群体 (3)对抽取的小群体中每一个单位逐个 进行调查
浙江工业大学
社会定量研究方法
3、整群抽样的特点
优点:1.简化抽样过程,降低费用
2.可扩大抽样规模 3.更容易取得抽样框
缺点:样本分布面不广,代表性较差,尤其
是当子群间异质性较强时,影响代表性更 明显。
浙江工业大学
几种抽样方法的比较
社会定量研究方法
假设我们的总体是全国所有城市的集合,我们要 抽取一个规模为40个城市的样本。 若按简单随机抽样或系统抽样的方法,则首先需 要弄到一份全国城市的名单,然后根据随机数表 或通过计算抽样间距直接从抽样框中抽取城市; 若按分层抽样的方法,则可以先按城市规模将总 体分为特大城市、大城市、中等城市和小城市四 类,然后分别从每一类中抽取若干城市,并将这 些城市合起来构成样本; 如果采用整群抽样的方法,则可以以省(自治区, 直辖市)为抽样单位,从全国31个省(自治区、 直辖市)中随机抽取三至五个省(自治区、直辖市) 浙江工业大学
——研究者依据研究目标和自己主观
分析来选择和确定研究对象。
三、定额抽样quota/配额抽样
四、雪球抽样snowball
浙江工业大学
三、概率抽样的原理与程序
社会定量研究方法
(一)概率抽样的原理
保证总体中每一个个体都有相等的机 会入选样本。
当总体情况不明时,无法做到随机抽样。
浙江工业大学
社会定量研究方法
浙江工业大学
社会定量研究方法
采用PPS的方法:先将各个元素(即企业) 排列起来,然后写出它们的规模、计算它 们的规模在总体规模中所占的比例;将 它们的比例累计起来,并根据比例的累 计数依次写出每一元素所对应的选择号 码范围,然后采用随机数表的方法或系 统抽样的方法选择号码,号码所对应的 元素入选第一阶段样本,最后再从所选 样本中进行第二阶段抽样(即从每个被抽 中的元素中抽取50名职工)。
097 098
009
010
019
020
029
030
099
100
浙江工业大学
练习
社会定量研究方法
练习:从某乡3000户农民中抽取150户作为样本调查农
民收入情况,按照等距抽样方法,如何操作?
浙江工业大学
(三)分层抽样
社会定量研究方法
1、含义:先将总体中所有单位按某种特征或 标志划分为若干类型或层次,然后再在各 个类型或层次中采用简单随机抽样或系统 抽样的方法抽取一个子样本,将其合成样 本。
浙江工业大学
社会定量研究方法
6.参数值/总体值
——是对总体元素特征的综合数量表现。
7.统计值/样本值
——是根据样本计算出来的关于样本变
量的数量表现。
浙江工业大学
社会定量研究方法
(二)抽样的作用
基本作用:是人们从部分认识整体的关 键环节 必要性:研究人员难以做到任何研究都 进行全面调查,而抽样误差可以控制到
(1)优点:既可了解总体也可以了解类别;
不同层可再采取不同方法;样本数相同 时,误差比简单随机法小,误差要求相 同时,抽取样本比简单随机少
(2)缺点:对分层准确性要求高
(3)适用范围:个体数目较多,内部差异
较大,既要了解总体也要了解类别时
浙江工业大学
练习
社会定量研究方法
练习:要了解某市800个私营企业的生产经营状况,决