从费氏临床试验谈近代生物统计张忆寿61 熊昭
民国时代的生物学

在中国现代生物学发展的早期,生物 学家面临的首要任务就是对中国的生
物源进行科学的调查研究
中国“植物分类学之父”胡先骕 胡经甫,中国昆虫学奠基人 朱元鼎,中国鱼类学奠基人 童第周,中国克隆之父 张景钺,中国植物形态学开拓者 牛满江,著名遗传学家 张作人,原生动物学开拓者
他们学有所长,都曾留学回国,尽管当时社 会动荡,经济条件很差,但是这一代的生物 学家艰苦奋斗,积极奉献,为中国的生物事 业的发展作出了卓越贡献。
民国时代的生物学
民国初年中国仍旧没有一个专门的生物学研究机构 后来,1918年中国科学社生物研究所终于在南京正式 成立 20年代以来,生物学各专业学会相继成立
1925年北京博物学会成立
1926年中国生理学会成立
1929年中国古生物学会成立
1930年中华水产生物学会成立
1933年中国植物学会成立
生物统计学

生物统计学发展过程中的 标志性人物
Page 1
一.R.A.Fiisher(费舍尔)
• R.A.Fisher(1890~1962),全名Ronald Aylmer Fisher,生于伦敦,卒于 Adleaide(澳洲)。英国统计与遗传学家, 现代统计科学的奠基人之一,英国经济学 家、新西兰奥塔哥大学教授,第三次产业 论的提出者。
• 在洛桑试验站费舍尔长期分析关于作物产量和气 象学的数据,他对统计方法做出了巨大的贡献。 • 1925年,他出版了一本书名为《科研工作者的统 计方法》,取得了巨大的成功并被印刷很多次。 • 1929年他成为英国皇家学会的一员。 • 1930年费舍尔出版了一本有关《自然选择的遗传 理论》的书,成为遗传学历史上的一个里程碑。 • 1933年他成为伦敦大学学院优生学的教授,接替 了卡尔皮尔森在高尔顿实验室的位置。 • 之后他又出版了好几本书,《设计性实验》 (1935),《近亲繁殖理论》(1949)和《统计 方法和科学推理》(1956)。 • 1952年被封爵,1959年退休后定居在澳大利亚, 并于1962年在阿德莱德去世。
主要著作:
《根据孟德尔遗传方式的亲属间 的相关》、《研究者用的统计方 法》、《自然选择的遗传理论》、 《试验设计》、《近交的理论》 及《统计方法和科学推理》等。
费舍尔的主要贡献:
一、用亲属间的相关说明了连续变异的性状可以用孟德尔定律来解释,从 而解决了遗传学中孟德尔学派和生物统计学派的论争。(28岁时发表的重 要论文内容) 二、提出了F检测和F分布,创立论证了方差分析的原理和方法,阐明了 最大似然性方法以及随机化、重复性和统计控制的理论。 三、他提出的数学原理和方法(方差分析)对人类遗传学、进化论和数量 遗传学的基本概念以及农业、医学方面的试验均有很大影响。
生物统计学 第6章 2010
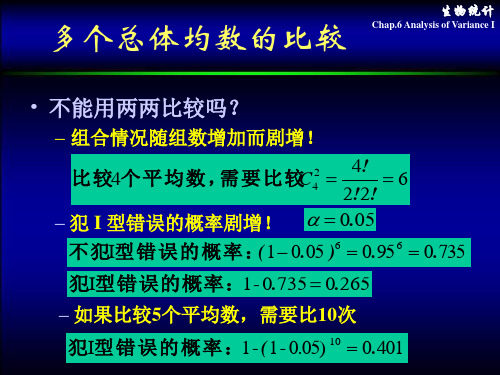
生物统计
单向分类的资料
Chap.6 Analysis of Variance I
在试验中所考虑的因素只有一个时,称为单因
素(单向分组)实验。
单因素方差分析是最简单的一种,它适用于只 研究一个试验因素的资料,目的在于正确判断该试
生物统计
实例-小鼠脾脏
group 1 2 3 4 I 12.3 13.2 13.7 15.2 II 10.8 11.6 12.3 12.7 III 9.3 10.3 11.1 11.7 IV 9.5 10.3 10.5 10.5 5 15.4 13.5 11.7 10.5 6 15.8 13.5 12.0 10.9
–零假设:1= 2= 3= 4 –备择假设:至少两个均数不等 MS A 28.6188 检验统计量: F 16.855 F0.01 (3,28) 4.57 MSE 1.6979
F F0.01 ( 3,28 ) 否定H 0 , 患各种白血病的小鼠的 脾脏重量差异极显著
生物统计
SSE SST SSA 133.3971 85.8563 47.5408 dfT N 1 32 1 31 dfE N k 32 4 28 dfA k 1 4 1 3
定义统计量 均方(MS) 平方和 自由度 SSA 85.8563 SSE 47.5409 MS A 28.6188 MSE , 1.6979 df A 3 dfE 28
X
ij
X X ij X i. X i. X
2 2
i 1 j 1
2
2
生物医学常用之统计方法(统计检定)(精)

Compare the FEV values between M and F
5.79
SPSS
Analyze
Descriptive Statistics
a
Explore
Plots
Tests of Normality Kolmogorov-Smirnov Statistic df Sig. .051 654 .000
資料處理可分為: 非正式與正式兩種
非正式的資料處理方式(描述性統計法): 圖示法: 直方圖; 莖葉圖; Box-Plots… 數字法: 百分比; 平均值; 標準差(表格); 中位數… 正式的資料處理方式(推論性統計法): 卡方檢定; t 檢定; ANOVA; 無母數方法; 廣義線性模型(迴歸分析;變異數分析…) ; (存活分析; 長期相依資料之廣義線模分析)
FEV1 (liters)
a. Lilliefors Significance Correction
Normal Q-Q Plot of FEV1 (liters)
4 3 2 1 0
624 648 632 452 609 517 464 649 321
5
4
3
-1 -2 -3 -4 0 1 2 3 4 5 6
Normal Q-Q Plot of LNFEV
4 3 2 1 0 -1 -2 0.0 -3 -4 -.5 0.0 .5 1.0 1.5 2.0 -.5
N=
2.0
1.5
1.0
.5
23 140 104
654
Observed Value
LNFEV
SPSS
Analyze
Descriptive Statistics
《生物统计附试验设计》第五版-课后习题(前六章)最新

生物统计第一章绪论1.什么是生物统计?它在动物科学研究中有何作用?2.什么是总体、个体、样本、样本容量?统计分析的两个特点是什么?3.什么是参数、统计数?二者有何关系?4.什么是试验或调查的准确性与精确性?如何提高试验或调查的准确性与精确性?5.什么是随机误差与系统误差?如何控制、降低随机误差,避免系统误差?6.统计学发展的概貌可分为哪三种形态?拉普拉斯、高斯、高尔顿、皮尔森、哥塞特、费舍尔对统计学有何重要贡献?第二章资料的整理1.资料可以分为哪几种类型?它们有何区别与联系?2.为什么要对资料进行整理?对于计量资料,整理成次数分布表的基本步骤是什么?3.统计表与统计图有何用途?常用统计表、统计图有哪些?编制统计表、绘制统计图有何基本要求?4.某品种100头猪的血红蛋白含量资料单位:g/100ml列于下表,将其整理成次数分布表,并绘制次数分布直方图与折线图。
表格1 4某品种100头猪的血红蛋白含量(g/100ml)13. 4 13.814.414.714.814.413.913.13.12.812.512.312.111.811.10.111. 1 10.111.612.12.12.712.613.413.513.514.15.15.114.113.513.513. 2 12.712.816.312.111.711.210.510.511.311.812.212.412.812.813.313. 6 14.114.515.215.314.614.213.713.412.912.912.412.311.911.110.710. 8 11.411.512.212.112.89.512.312.512.713.13.113.914.214.912.413. 1 12.512.712.12.411.611.510.911.111.612.613.213.814.114.715.615. 7 14.714.13.95.1~9周龄大型肉鸭杂交组合GW和GY的料肉比列于下表,绘制线图。
统计 试题

一.最佳选择题(15分,每题1分)1.偏态分布资料宜用描述其分布的集中趋势。
a.算术均数 b.几何均数 c. 中位数 d. 四分位数间距2.两样本均数比较时,分别取以下检验水准,以所对应的第二类错误最小。
a.α=0.01 b. α=0.05 c. α=0.10 d. α=0.203.对于t分布来说,固定显著性水平α的值,随着自由度的增大,t的临界值将会怎样变化。
a.增大 b. 减少 c. 不变 d. 可能变大,也可能变小4.标准正态分布的均数与标准差分别为。
a.0与1 b. 1与0 c. 1与1 d. 0与05.分布的均数等于方差。
a.正态分布 b. 对数正态分布 c. Poission分布 d.二项分布6.成组设计的方差分析中,必然有。
a.SS组内〈 SS组间b. MS组间〈 MS组内c. MS总=MS组间+MS组内d. SS总=SS组间+SS组内7.四个样本率作比较,X2>X20.01(3),可认为。
a.各总体率不同或不全相同 b. 各总体率均不相同 c. 各样本率均不相同d. 各样本率不同或不全相同8.等级资料比较宜用。
a.t检验 b. X2检验 c. 秩和检验 d. F检验9.统计推断的内容。
a.是用样本指标估计相应总体指标 b. 是检验统计上的“假设”c. a,b均不是d. a,b均是10.同一双变量资料,进行直线相关与回归分析,有。
a.r>0,b<0 b. r>0,b>0 c. r<0,b>0 d. r=b11. 某市搜集了自1949年到1987年5种传染病发病率的资料,想绘一张统计图直观地比较它们的变化趋势,请选用适当的统计图。
a.复式直方图 b. 普通线图 c.复式条图 d. 半对数线图12. 在进行成组设计资料的t检验中,H0为µ1=µ2,H1为µ1≠µ2,α=0.05。
若检验的结果为接受H0,拒绝H1,问此时可能犯错误。
高等生物统计学课件.ppt
总体:根据研究目的确定的研究对象的全体。 样本:按照一定方法从总体中抽取的一部分单元的全体。 统计量:样本决定的不含任何参数的函数。 准确度:指在调查或试验中某一试验指标或性状的观测 值与其真值接近的程度。
精确度:指调查或试验中同一试验指标或性状的重复观 测值彼此接近的程度。
生物观测数据的类型:
2.蓬勃发展阶段 进入20世纪后,数理统计理论和方法得到了蓬勃发展。
英国统计学家哥色特提出了学生氏t分布,并将其用于平均 数的比较;英国生物学家费希尔提出了试验设计的基本原 则和方差分析法;英国计算机科学家叶茨也作了大量工作。 许多多元分析方法被建立和应用。特别是20世纪后期由于 计算机的快算发展,使得许多统计方法在解决生物科学领 域内问题时,发挥出巨大作用。
2.试验数据误差分类
系统误差:是由较确定的原因引起的,可校正和消除; 随机误差:是由不确定原 因引起的,不可避免和消除; 过失误差:是指一种显然与事实不符的误差,必须避免 和剔除。 3.试验数据误差的来源 试验材料的固有差异:生物学研究对象一般是生物有机 体。自然界不同的生物体具有不同的遗传性质,同一生物 的不同种具有不同的特征,同一品种生物在生长发育过程 中不同个体也有差异,这都能导致研究指标的变化。 环境条件的差异:生物学试验一般都要在外界环境中进 行,而外界环境是多变样的,且地域性很强有较难控制, 这就会导致研究指标的差异。 管理不一致所引起的差异:生物学试验是以生物个体为对 象研究问题,生物个体在发育和生长过程需要管理,而对
关于《高等生物统计课程》的说明
本课程是为满足生物科学各专业研究生学习和研究 的需要而开设计思想和 方法应用、计算机实现的介绍。内容包括均值比较、回 归分析、数据缩减、聚类与模式识别等。要求学生具有 初等概率统计或初等生物统计的基础和计算机基础。
生物统计学第一章绪论——科学实验及其误差(精)
西南科技大学生命科学与工程学院周海廷制作
1
1.1 科学研究与科学试验
1.1.1 生物学领域的科学研究 1.1.2 科学研究的基本过程和方法
西南科技大学生命科学与工程学院周海廷制作
2
1.1.1 生物学领域的科学研究
科学研究是人类认识自然、改造自然、服务社会的 原动力。
在试验条件相当的 情况下,重复试验 应得到相同的试验 结果。
西南科技大学生命科学与工程学院周海廷制作
11
1.2 试验误差及其控制
1.2.1 试验数据的误差和精确性 1.2.2 试验误差的来源 1.2.3 试验误差的规律性 1.2.4 试验误差的层次性
西南科技大学生命科学与工程学院周海廷制作
12
1.2.1 试验数据的误差和精确性
系统误差(systematic error):有一定原因 引起的误差,也称偏差(bias)。
西南科技大学生命科学与工程学院周海廷制作
15
准确性:观察值与理论值之间的符合程度。 精确性:指观察值之间的符合程度。
下面用例子说明误差与准确性和精确性之间的关 系。
系统误差使数据偏离了其理论值,影响数据的准确性。 偶然误差使数据相互分散,影响了数据的精确性。
或真值,以μ表示。
西南科技大学生命科学与工程学院周海廷制作
13
由于误差是客观存在的,所以:
观察值=真值+误差
用代数式表示为:
yi= μ+εi 式中εi代表误差,故:
εi= yi- μ
误差(error):观察值与真值之间的差异。
西南科技大学生命科学与工程学院周海廷制作
14
误差的分类:
随机误差(random error):完全是偶然的, 找不出确切原因引起的误差,也称偶然性 误差(spontaneous)。
胡跃清:为生命而奔走
胡跃清:为生命而奔走作者:王婷婷来源:《科学中国人》2013年第03期说起生物统计学,很多人可能一头雾水,不知道是研究什么的。
“生物统计学是采用统计学的定量分析方法研究生命科学相关问题的一门交叉学科,目前已被广泛应用于生命科学的各个领域中”,作为复旦大学生物统计学研究所正高级P I的胡跃清这样解释道。
因此,也可以说,生物统计学是一门始终围绕着生命而奔走的学科。
胡跃清多年从事统计遗传学,统计法证学和统计诊断学的研究工作,在John Wiley & Sons 出版著作“St atistical DNA Forensics: Theory,Methods and Computation”,在American Journal of Epidemiology, Annals of Human Genetics, Biometrics, Forensic Science International,Genetic Epidemiology, Genetics, Heredity, Human Heredity, International Journal of Legal Medicine, Journal of Human Genetics, Journal of the Royal Statistical Society Series A,Scandinavian Journal of Statistics, Statistics in Medicine, Transfusion等国际著名刊物上发表科学论文。
树立科学理想走上研究道路1981-1988年就读中山大学数学系获理学学士学位和理学硕士学位,2003-2007年就读香港大学统计与精算学系获哲学博士学位。
1988-2003年任东南大学助教/讲师/副教授,2007-2009年任香港大学统计与精算学系助理教授。
从2010年,他开始担任复旦大学生物统计学研究所正高级PI。
生物统计学:第一章 绪论
生物统计学的用途
生物统计学是运用数理统计的原理和方法来分 析和解释生物界各种现象和实验调查资料的一门科 学,是一门应用数学。 在生物学研究中具有重要 的作用: ➢ 对实验设计有重要的指导作用 ➢ 提供数据整理分析的方法 ➢ 提供由样本推论总体的方法 ➢ 提供分析变异因素的方法 ➢ 帮助分析现象之间的关系
课程要求学生能掌握生物统计学的基本原理和方法,合理 地设计试验和总结试验结果,对试验所获得的数据能够熟练 地进行数理统计分析。
重点在于: .各项统计分析方法的理论依据和适用范围。 .常用试验设计方法的实际应用。
统计学常用术语
1.1 变量与观测值
变量(variable) :某种特征,其表现随个 体而异。
但是在许多领域,很难用确定的公式或论述来描述一些现象。 比如,人的寿命是很难预先确定的,是有一定随机性的 (randomness)。这种随机性可能和人的经历、基因、习惯等 无数说不清的因素都有关系。
但是许多随机性的事物中又有一定的规律性。
从总体来说,我国公民的平均寿命是非常稳定的。而且女性 的平均寿命也稳定地比男性高几年。——规律性
➢ 统计量(statistic) :由样本计算的数,是描述样本特 征的数,是参数的估计值,受抽样变动的影响。常 用英语字母表示,如样本均数x、样本标准差S。
➢ 由样本推断总体也可以理解为由统计量推断参数。
1.4 准确性与精确性
准确性(accuracy) :观测值或估计值与真值的 接近程度
精确性(precision):重复观测值或估计值之间的 接近程度
如:身高、体重、体长、产奶量、毛色
观测值(observation) :对变量进行测量 或观察所获得的数值。
1.2 总体、个体与样本
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
從費氏臨床試驗談近代生物統計張憶壽•熊昭一.楔子在許多人的觀念中,凡是與醫學、藥學、動物、植物等有關的隨機現象均在生物統計(Biostatistics)的知識範圍之內。從這個角度來看,我們當能理解生物統計給人的拼盤印象。這情形與理論數學中的主題鮮明,層次井然固然不同,而與統計學中某些分支所表現的精雕細琢也不甚一樣。但是這種拼盤印象似乎逐漸成為過去了。生物統計學的內容在過去三、四十年間有了相當的充實與改變。這種充實與改變一方面是基於醫藥研究上的急切需要,另方面則是由於近代機率論的適時成長。而代表這種充實與改變的兩個主要分支便是存活分析與序列分析。在本文裡,我們要先介紹一個著名的費氏白血病患存活數據,然後指出要能充分利用類似這樣的數據而得出科學性結論便是當代存活分析與序列分析的主要目標。希望這個簡單的介紹能夠幫助具有大學乃至高中數學程度的人士暸解生物統計的要旨。
二.費氏白血病患存活數據
費氏(Freireich)等人在1963年報告了一個關於白血病患的存活數據。這套數據給許多生物統計學家研究過。我們現在參考Andersen,Borgan,Gill&Keiding(1993)及Siegmund(1985)來陳述這套數據。當時,在美國的十一家醫院裡,有62個患有急性白血病(acuteleukemia)的病患,這些病患是在接受類固醇(prednisone)治療後得到部分或完全緩解的小孩。緩解(re-mission)在這是指骨髓中的病況消失。這62個病患接受了一個緩解維持治療方案(re-missionmaintenancetherapy)。它的做法是這樣的:以醫院為單位,把在同一醫院內的這些病患依照緩解狀況加以配對,然後在每一對中隨機抽出一位給他施予6-MP治療,而剩下的一位則給他安慰劑(placebo)。下表所列的是21個完整配對的緩解時段數據。緩解時段(remissionlength)是指病患配對後(約為緩解發生時刻)至白血病復發時刻的時段長度。譬如說,第5對病患中用安慰劑的是8週後開始復發,用6-MP的是22週後復發。
12數學傳播十九卷二期民84年6月對(i)安慰劑6-MP勝負淨贏W(i)
表一.表中第一行為對數,第二行為某對中使用安慰劑的病患的緩解時段,第三行為使用6-MP之緩解時段,(皆以週為單位),第四行為該對勝負狀況,1表示6-MP得勝,−1表示安慰劑得勝,第五行為W(i)。例如第7列說第7對病人中使用安慰劑的緩解期為2週,使用6-MP的是16週,所以6-MP得勝,而在第7對的勝負分曉時,6-MP一共淨贏3分。
基於人道考量,這個試驗是所謂的序列試驗;即,要在能看出6-MP與安慰劑之優劣後儘早停止試驗,以免病患成為劣等治療法的無謂犧牲品。因此,試驗開始之前便如下規定:如果一個使用安慰劑的病患比他配對的病患早產生復發現象,則記安慰劑缺點一次;反之,則記6-MP缺點一次。而當雙方缺點次數的差距大到一個程度時,則即刻停止試驗。由於停止試驗的時候,很可能還有病患處於緩解期間。對這些病患,我們沒法知道他的緩解時段有多長,而僅知道他在緩解開始至試驗結束止的這一時段內沒有復發。數據表裡第3對病患中服用6-MP的那位便是在32週後,試驗終止了,而仍處在緩解期中的一個例子。這種情形的數據是一種所謂的設限數據。如果一個病患因為其他因素在白血病復發前死亡,或中途離去而不在試驗觀察之中,則所觀察到的數據也稱為設限數據。
三.序列分析我們先引入一些數學符號來描述上述數據。令Yi是第i對病人配成對的時刻(約為緩解發生的時刻)。令Xi1,Xi2分別代表第i對病人中採用6-MP與採用安慰劑的緩解時段。從費氏臨床試驗談近代生物統計3
第二節中所說的停止整個試驗的時間可以更清楚的敘述如下。令Wi(t)為第i對病人在時間(日曆)t時6-MP與安慰劑的勝負狀況。即當Xi1∧t>Xi2∧t時,令Wi(t)=1,當Xi1∧tXi1∧t=Xi2∧t時,令Wi(t)=0。(這裡a∧b是指a與b二數中較小的那數)。令W(t)=ni=1Wi(t)。則W(t)代表了在t時刻,6-MP比安慰劑多得的點數。這裡n為一適當大的數,大於可能配成的對數。令Ti=Yi+Xi1∧Xi2。令T(k)
為{T1,T2,···,Tn}中第k小的數。因此
T(1)≤T(2)≤···T(n),而且{T1,···,Tn}={T(1),···,T(n)}。由於W(t)只在當t=T(i)時才會變動它的值,令W(i)≡W(T(i))。W(1),W(2),···,W(n)這個有限數列就代表了6-MP與安慰劑的勝負記綠。為了方便,我們可以把(i,W(i)),i=1,2···,n劃在座標平面上。當時,Freireich等人便是預先把座標平面分成幾個區域,分別叫G,G1,G2,G3(如圖一),然後規定好,一旦有一個i,使得(i,W(i))離開G,則停止試驗。用數學符號來講便是定義停止時刻
S=inf{i|(i,W(i))/∈G}.停止試驗時,如果(i,W(i))是在G1,則說6-MP較好,若在G2,則說安慰劑較好,若在G3,則說兩者無甚差異。
圖一這種一邊收集數據,一邊做統計分析,然後再決定是否要繼續收集數據的設計稱為序列設計,相關的分析叫序列分析。它是當今統計領域中理論比較豐富的一支。但是,在1960年代初期它的理論還是相當年輕的。關於這裡的情形,就有許多問題是當時無法回答的。Freireich等人所選的這個G,G1,G2
及G3具有下述性質。令P=P(Xi1>
Xi2)。如果P=0.75,則這試驗會有0.95的機率說6-MP較好,如果P=0.25,則這試驗會有0.95的機率說安慰劑較好。為什麼選用這樣的{G,G1,G2,G3}呢?很自然的,我們要問,如果有另外一組{G′,G′1,G′2,G′3}也具有上段所說的性質,我們該選用那一組?這時侯有一個簡單的選擇辦法,即,看那一組所需的樣本數S較少。用心的讀者不難發現這不是一個容易的問題。4數學傳播十九卷二期民84年6月四.存活分析
上述判定6-MP與安慰劑優劣的辦法只是許多辦法之一。它是有些粗糙的,因為它只看每一對病人中的相對勝負,即Xi1>Xi2
或Xi1
Xi1−Xi2,考慮進去。近代存活分析的主要貢獻之一便是提出了處理這個問題的一個辦法。下邊我們先介紹這個辦法,再提一下它的背景。為此,我們引入隨機過程
Nik(t)=1[Xik,∞)(t∧T).這裡T是整個臨床試驗停止的時刻。Nik(t)記錄了第i對第k人在t時刻是否仍在緩解期。假設Xik的風險函數(hazardrate)是λik(t)。λik(t)的意思是一個緩解期大於或等於t的人會馬上復發的機率。假設λi1(t)=λi2(t)·eθ,則θ便是一個比較6-MP與安慰劑優劣的一個指標,在存活分析裡,這叫做相對風險係數(relativeriskco-efficient)。有的文獻稱之為療效(treatmenteffect)。令
G(θ,t)=21i=12
k=1
t
0
Zik−
2
k=11(s)(0,Xik]eθZikZik從費氏臨床試驗談近代生物統計5
估計θ0;但是,T愈大,使用劣等治療法的時間愈久。怎樣的T最好?這又是序列分析的課題了。
五.結語在第三節、第四節中我們藉著Freireich數據介紹了一點點的序列分析及存活分析的概念。這兩門學問都有相當的內容,一方面它們成功的扮演了科學之僕的角色,另方面它們也造就了自己的理論。但是,Freireich的試驗所能提出的科學結論就只這樣嗎?Freireich等人的論文中沒有把Yi報告出來,只報告了Xik及X+ik。許多後來的統計學家便依照這樣的數據提出新的統計方法去分析6-MP的療效。除了Sellke&Sieg-mund(1983)之外,沒有人從序列分析的觀點來研究這數據。在Sellke&Siegmund的工作之後,許多人瞭解到這工作的困難情形,也注意到當時Freireich沒發表Yi是相當可惜的。事實上,Sellke&Siegmund不是以研究這套數據為目標,他們是要建立更一般的序列分析理論。他們沒有考慮到配對的設計。如果把配對的設計考慮進來,該如何做呢?事實上,這時候比較好做,最近我們在這問題上得到了一些結論。參考文獻文中所引論文多可在以下兩本書中找到1.Andersen,P.K.,Borgan,φ,Gill,R.D.,Keiding,N.(1993).StatisticalModelsBasedonCountingProcesses.Springer-Verlag.2.Siegmund,D.O.(1985).SequentialAnalysis.Springer-Verlag.—本文作者任教於中央大學數學系與中央研究院統計科學研究所—