汉字区位码、国标码、机内码
汉字系统中的汉字字库里

汉字系统中的汉字字库里
汉字系统中的汉字字库里存放的是汉字的:机内码。
1.机内码是汉字在计算机内部存储、传送、交换的内部编码。
2.输入码就是使用英文键盘输入汉字时的编码。
3.国标码是一个四位十六进制数,区位码是一个四位的十
进制数,每个国标码或区位码都对应着一个唯一的汉字或符号,但因为十六进制数我们很少用到,所以大家常用的是区位码,它的前两位叫做区码,后两位叫做位码。
4.国标码是汉字息交换的标准编码。
每个汉字及符号以两个字节来表示。
第一个字节称为“高
位字节”(也称“区字节)”,第二个字节称为“低位字节”(也
称“位字节”)。
“高位字节”使用了0xA1-0xF7(把01-7区的区号加上
0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上 0xA0)。
由于一级汉字从16区起始,汉字区的“高位字节”的范围是
0xB0-0xF
7,“低位字节”的范围是0xA1-0xFE,占用的码位是
72*94=
676。
其中有5个空位是D7FA-D7FE。
汉字编码标准
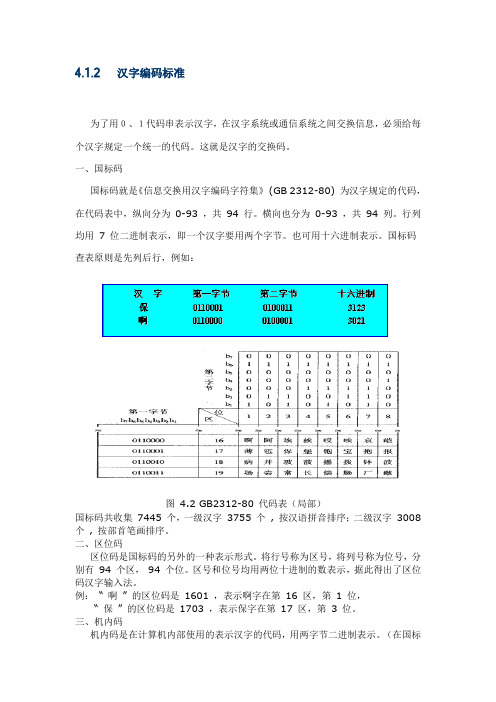
4.1.2 汉字编码标准为了用0、1代码串表示汉字,在汉字系统或通信系统之间交换信息,必须给每个汉字规定一个统一的代码。
这就是汉字的交换码。
一、国标码国标码就是《信息交换用汉字编码字符集》(GB 2312-80) 为汉字规定的代码,在代码表中,纵向分为0-93 ,共94 行。
横向也分为0-93 ,共94 列。
行列均用7 位二进制表示,即一个汉字要用两个字节。
也可用十六进制表示。
国标码查表原则是先列后行,例如:图 4.2 GB2312-80 代码表(局部)国标码共收集7445 个,一级汉字3755 个, 按汉语拼音排序;二级汉字3008 个, 按部首笔画排序。
二、区位码区位码是国标码的另外的一种表示形式。
将行号称为区号,将列号称为位号,分别有94 个区,94 个位。
区号和位号均用两位十进制的数表示,据此得出了区位码汉字输入法。
例:“ 啊” 的区位码是1601 ,表示啊字在第16 区,第 1 位,“ 保” 的区位码是1703 ,表示保字在第17 区,第 3 位。
三、机内码机内码是在计算机内部使用的表示汉字的代码,用两字节二进制表示。
(在国标码每个字节前添1 就是机内码,添1 是为了确保与英文字符区分开)。
输入汉字→国标码( 区位码) →机内码→存储转换关系:十六进制的区位码+ 2020H →国标码十六进制的国标码+ 8080H →机内码8080H 等于二进制的l000000010000000 ,国标码加上8080H ,可以保证机内码每个字节首位均为 1 。
例:“ 啊” 的区位码是:1601 转换成十六进制10011001 +2020=3021 (国标码)再转换成机内码:3021+8080=B0A1二进制表示为1011000010100001 (B0A1 )中山市港口理工学校计算机科温金辉。
国标码 区位码等的区别

即GB国标码:中文内码之一,代表中文简化字,在中国大陆广泛使用,影响所及,使用量渐见普及。
“国家标准信息交换用汉字编码”(GB2312-80标准),简称国标码。
国标码是指1980年中国制定的用于不同的具有汉字处理功能的计算机系统间交换汉字信息时使用的编码。
国际码是二字节码, 用两个七位二进制数编码表示一个汉字。
目前国标码收入6763个汉字, 其中一级汉字(最常用)3755个, 二级汉字3008个, 另外还包括682个西文字符、图符。
例如“巧”字的代码是39H 41H, 在机内形式如下: 0 1 1 1 0 0 1 1 第一字节0 0 0 0 0 1第二字节在计算机内部,汉字编码和西文编码是共存的,如何区分它们是个很重要的问题,因为对不同的信息有不同的处理方式。
方法之一是对于二字节的国标码,将二个字节的最高位都置成“1”, 而ASCII码所用字节最高位保持“0”,然后由软件(或硬件)根据字节最高位来作出判断。
字符代码化是指用户从键盘上输入代表某个汉字的编码。
我们把采用不同的编码系统以代表汉字进行输入的方案(如数字码、拼音码和字形码),称为汉字的输入法,区位码、五笔字型码、拼音码、智能ABC、微软拼音输入法等都是其中的具体代表。
汉字通过编码输入计算机后,在其后的处理过程中,不同阶段使用不同的代码,首先通过键盘管理程序将接收到的输入编码转换为0和1构成的机内码,实现计算机的存储、加工和传输处理。
同样,存储在计算机内部的机内码也必须经转换后才能恢复汉字的“本来面目”。
这种转换通常是由计算机的输入/输出设备来实现的, 有时还需要软件来参与这种转换过程。
这个阶段的汉字代码称为字形码,用以显示和打印输出。
区位码:1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
汉字编码关系

输入码、区位码、国标码与机内码我们知道,键盘是当前微机的主要输入设备,输入码就是使用英文键盘输入汉字时的编码。
目前,我国已推出的输入码有数百种,但用户使用较多的约为十几种,按输入码编码的主要依据,大体可分为顺序码、音码、形码、音形码四类,如“保”字,用全拼,输入码为码为“BAO”,用区位码,输入码为“1703”,用五笔字型则输入码为“WKS”。
计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。
我国国家标准局于1981年5月颁布了《信息交换用汉字编码字符集──基本集》,代号为GB2312-80,共对6763个汉字和682个图形字符进行了编码,其编码原则为:汉字用两个字节表示,每个字节用七位码(高位为0),国家标准将汉字和图形符号排列在一个94行94列的二维代码表中,每两个字节分别用两位十进制编码,前字节的编码称为区码,后字节的编码称为位码,此即区位码,如在二维代码表中处于17区第3位,区位码即为“1703 ”。
(教材附页可找到)国标码并不等于区位码,它是由区位码稍作转换得到,其转换方法为:先将十进制区码和位码转换为十六进制的区码和位码,这样就得了一个与国标码有一个相对位置差的代码,再将这个代码的第一个字节和第二个字节分别加上20H,就得到国标码,相当于如果不转换的话,在两个字节上分别加上32即可。
如:“保”字的国标码为3123H,它是经过下面的转换得到的:1703D->1103H->+20H->3123H。
国标码是汉字信息交换的标准编码,但因其前后字节的最高位为0,与ASCII码发生冲突,如“保”字,国标码为31H和23H,而西文字符“1”和“#”的SCII也为31H和23H,现假如内存中有两个字节为31H和23H,这到底是一个汉字,还是两个西文字符“1”和“#”?于是就出现了二义性,显然,国标码是不可能在计算机内部直接采用的,于是,汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上128,即将两个字节的最高位由0改1,其余7位不变,也就是如果国标码是16进制的,直接加上8080H即可。
区位码、国标码与机内码的转换只是分享

➢ 举例:以汉字“大”为例,“大”字的区 内码为2083
➢ 解:1、区号为20,位号为83
➢ 2、将区位号2083转换为十六进制表示为 1453H
➢ 3、1453H+2020H=3473H,得到国标码 3473H
➢ 4、3473H+8080H=B4F3H,得到机内码 为B4F3H
机内码:为了避免ASCII码和国标码同时使用时产生二义性问题,大 部分汉字系统都采用将国标码每个字节高位置1作为汉字机内码。这 样既解决了汉字机内码与西文机内码之间的二义性,又使汉字机内码 与国标码具有极简单的对应关系。
➢ (1)区位码先转换成十六进制数表示 ➢ (2)(区位码的十六进制表示)+2020H
区位码、国标码与机内码 的转换关系方法
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码、汉 字字库的设计、汉字输入码的转换、输出设备的汉字地址码等,都以 此标准为基础。GB 2312—80就是国标码。该码规定:一个汉字用两 个字节表示,每个字节只有7位,与ASCII码相似。
区位码:将GB 2312—80的全部字符集组成一个94×94的方阵,每 一行称为一个“区”,编号为0l~94;每一列称为一个“位”,编号 为0l~94,这样得到GB 2312—80的区位图,用区位图的位置来表示 的汉字编码,称为区位码。
汉字编码的形式

汉字编码的形式汉字作为中华文化的载体,其编码形式对于信息处理和数据交换具有重要意义。
随着计算机技术的发展,汉字编码也经历了多个阶段,形成了多种不同的编码形式。
本文将介绍汉字编码的主要形式,包括字符集编码、输入码、区位码、内码、外码、字形编码、校验码和特殊编码。
一、字符集编码字符集编码是用于在计算机中表示字符的编码标准,汉字的字符集编码包括国家标准码和各种常见编码标准。
其中,GB2312和GBK是国家标准码,用于规范汉字在计算机中的表示和交换。
GB2312收录了常用汉字及符号,GBK则是在GB2312的基础上扩大了汉字收录范围。
而Big5则是常见的繁体汉字编码标准,主要在台湾、香港等地使用。
二、输入码输入码是为了方便用户在计算机中输入汉字而设计的编码方式。
常见的输入码包括拼音码、五笔字型、自然码等。
拼音码是根据汉字的拼音字母顺序进行编码,五笔字型则是根据汉字的笔画结构进行编码,而自然码则是一种将拼音和字形结合的编码方式。
三、区位码区位码是一种类似于数字编码的汉字编码方式,它将每个汉字在特定字符集中的位置信息进行编码。
区位码通常由四个数字组成,前两个数字表示区号,后两个数字表示位号。
在区位码中,不同的区号和位号组合代表不同的汉字。
四、内码内码是指在计算机内部存储和处理汉字时所使用的编码方式。
常见的内码包括机内码和统一码。
机内码是在计算机内部存储和传输汉字时所使用的编码方式,它是将每个汉字的区位码或其他编码形式进行转换得到的。
统一码(Unicode)是一种国际化的字符编码标准,它将全球范围内的文字统一进行编码,包括了不同语言、符号和汉字等。
五、外码外码是用于将汉字输入到计算机中的外部设备的编码方式。
常见的外码包括各种输入法软件和硬件设备所使用的编码方式。
不同的输入法软件可能会使用不同的外码标准,例如拼音、五笔字型等。
六、字形编码字形编码是将汉字的字形进行数字化表示的编码方式。
它通常是将汉字的笔画按照一定的顺序进行拆分,并对每个笔画进行数字化表示。
区位码、国标码与机内码的转换
2021/3/27
CHENLI
2
➢ (1)区位码先转换成十六进制数表示 ➢ (2)(区位码的十六进制表示)+2020H
=国标码;
➢ (3)国标码+8080H=机内码
2021/3/27
CHENLI
3
➢ 举例:以汉字“大”为例,“大”字的区 内码为2083
➢ 解:1、区号为20,位号为83
➢ 2、将区位号2083转换为十六进制表示为 1453H
区位码、国标码与机内码 的转换关系方法
2021/3/27
CHENLI
1
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码、汉 字字库的设计、汉字输入码的转换、输出设备的汉字地址码等,都以 此标准为基础。GB 2312—80就是国标码。该码规定:一个汉字用两 个字节表示,每个字节只有7位,与ASCII码相似。
区位码:将GB 2312—80的全部字符集组成一个94×94的方阵,每 一行称为一个“区”,编号为0l~94;每一列称为一个“位”,编号 为0l~94,这样得到GB 2312—80的区位图,用区位图的位置来表示 的汉字编码,称为区位码。
机内码:为了避免ASCII码和国标码同时使用时产生二义性问题,大 部分汉字系统都采用将国标码每个字节高位置1作为汉字机内码。这 样既解决了汉字机内码与西文机内码之间的二义性,又使汉字机内码 与国标码具有极简单的对应关系。
➢ 3、1453H+2020H=3473H,得到国标码 3473H
➢ 4、3473H+8080H=B4F3H,得到机内码 为B4F3H
2021/3/27
CHENLI
4
完
2021/3/27
5
区位码国标码机内码转换问题
国标码并不等于区位码,它是由区位码稍作转换得到,其转换方法为:先将十进制区码和位码转换为十六进制的区码和位码,;这样就得了一个与国标码有一个相对位置差的代码,;再将这个代码的第一个字节和第二个字节分别加上20H,就得到国标码。
如:“保”字的国标码为3123H,它是经过下面的转换得到的:1703D->1103H->+20H->3123H。
输入码、区位码、国标码与机内码国家标准局1980年颁布的《信息交换用汉字编码字符集"基本集》(代号为GB2312 80)规定的汉字交换码作为国家标准汉字编码。
GB2312 80中共有7445个字符符号:汉字符号6763个一级汉字3755个(按汉语拼音字母顺序排列)二级汉字3008个(按部首笔划顺序排列)非汉字符号682个GB2312 80规定,我们知道,键盘是当前微机的主要输入设备,;输入码就是使用英文键盘输入汉字时的编码。
目前,我国已推出的输入码有数百种,但用户使用较多的约为十几种,按输入码编码的主要依据,大体可分为顺序码、音码、形码、音形码四类,如“保”字,用全拼,输入码为码为“BAO”,用区位码,输入码为“1703”,用五笔字型则为“WKS”。
计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。
汉字交换码(国标码)主要用于汉字信息交换,我国国家标准局于1981年5月颁布了《信息交换用汉字编码字符集——基本集》,代号为GB2312-80,共对6763个汉字和682个图形字符进行了编码,其编码原则为:汉字用两个字节表示,每个字节用七位码(高位为0),;所有的国标码汉字及符号组成一个94行94列的二维代码表中。
在此方阵中,每一行称为一个"区",每一列称为一个"位"。
这个方阵实际上组成一个有94个区(编号由01到94),每个区有94个位(编号由01到94)的汉字字符集。
汉字的机内码是指在计算机中表示一个汉字的编码
汉字的机内码是指在计算机中表示一个汉字的编码。
机内码与区位码稍有区别。
汉字区位码的区码和位码的取值均在1~94之间,如直接用区位码作为机内码,就会与基本ASCII码混淆。
为了避免机内码与基本ASCII码的冲突,需要避开基本ASCII码中的控制码(00H~1FH),还需与基本ASCII码中的字符相区别。
为了实现这两点,可以先在区码和位码分别加上20H,在此基础上再加80H(此处“H”表示前两位数字为十六进制数)。
经过这些处理,用机内码表示一个汉字需要占两个字节,分别称为高位字节和低位字节,这两位字节的机内码按如下规则表示:高位字节=区码+20H+80H(或区码+A0H)低位字节=位码+20H+80H(或位码+AOH)由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的01~94),所以汉字的高位字节与低位字节的取值范围则为A1H~FEH(即十进制的161~254)。
例如,汉字“啊”的区位码为1601,区码和位码分别用十六进制表示即为1001H,它的机内码的高位字节为B0H,低位字节为A1H,机内码就是B0A1H。
2603 = 1A03H 区位码+ A0A0H= BAA3H 机内码[本帖最后由 rossini23 于 2006-10-11 13:28 编辑]计算机处理汉字信息的前提条件是对每个汉字进行编码,这些编码统称为汉字编码。
汉字信息在系统内传送的过程就是汉字编码转换的过程。
汉字交换码:汉字信息处理系统之间或通信系统之间传输信息时,对每一个汉字所规定的统一编码,我国已指定汉字交换码的国家标准“信息交换用汉字编码字符集——基本集”,代号为GB 2312—80,又称为“国标码”。
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码、汉字字库的设计、汉字输入码的转换、输出设备的汉字地址码等,都以此标准为基础。
GB 2312—80就是国标码。
该码规定:一个汉字用两个字节表示,每个字节只有7位,与ASCII码相似。
刨根究底字符编码之六——简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系
刨根究底字符编码之六——简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系GB2312、GBK、GB18030等GB类汉字编码⽅案的具体实现⽅式是怎样的?区位码是什么?国标码是什么?内码、外码、字形码⼜是什么意思?它们是如何转换的,⼜为什么要这样转换?下⾯以GB2312为例来加以说明(由于GBK、GB18030是以GB2312为基础扩展⽽来,因此编码实现⽅式与GB2312⼀样)。
⼀、区位码1.整个GB2312字符集分成94个区,每区有94个位,每个区位上只有⼀个字符,即每区含有94个汉字或符号,⽤所在的区和位来对字符进⾏编码(实际上就是字符编号、码点编号),因此称为区位码(或许叫“区位号”更为恰当)。
换⾔之,GB2312将包括汉字在内的所有字符编⼊⼀个94 * 94的⼆维表,⾏就是“区”、列就是“位”,每个字符由区、位唯⼀定位,其对应的区、位编号合并就是区位码。
⽐如“万”字在45区82位,所以“万”字的区位码是:45 82(注意,GB类汉字编码为双字节编码,因此,45相当于⾼位字节,82相当于低位字节)。
2.GB2312字符集中:1)01~09区(682个):特殊符号、数字、英⽂字符、制表符等,包括拉丁字母、希腊字母、⽇⽂平假名及⽚假名字母、俄语西⾥尔字母等在内的682个全⾓字符;2)10~15区:空区,留待扩展;3)16~55区(3755个):常⽤汉字(也称⼀级汉字),按拼⾳排序;4)56~87区(3008个):⾮常⽤汉字(也称⼆级汉字),按部⾸/笔画排序;5)88~94区:空区,留待扩展。
⼆、国标码(交换码)1.为了避开ASCII字符中的不可显⽰字符0000 0000 ~ 0001 1111(⼗六进制为0 ~ 1F,⼗进制为0 ~ 31)及空格字符0010 0000(⼗六进制为20,⼗进制为32)(⾄于为什么要避开、⼜为什么只避开ASCII中0~32的不可显⽰字符和空格字符,后⽂有解释),国标码(⼜称为交换码)规定表⽰汉字的范围为(0010 0001,0010 0001) ~ (0111 1110,0111 1110),⼗六进制为(21,21) ~ (7E,7E),⼗进制为(33,33) ~ (126,126)(注意,GB类汉字编码为双字节编码)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汉字在计算机内部其内码是唯一的。
因为汉字处理系统要保证中西文的兼容,当系统中同时存在ASCII码和汉字国标码时,将会产生二义性。
例如:有两个字节的内容为30H和21H,它既可表示汉字“啊”的国标码,又可表示西文“0”和“!”的ASCII码。
为此,汉字机内码应对国标码加以适当处理和变换。
GB码的机内码为二字节长的代码,它是在相应GB码的每个字节最高位上加“1”,即汉字机内码=汉字国标码+8080H。
例如,上述“啊”字的国标码是3021H,其汉字机内码则是B0A1H。
汉字机内码的基础是汉字国标码。
机内码:为了避免ASCII码和国标码同时使用时产生二义性问题,大部分汉字系统都采用将国标码每个字节高位置1作为汉字机内码。
这样既解决了汉字机内码与西文机内码之间的二义性,又使汉字机内码与国标码具有极简单的对应关系。
汉字机内码、国标码和区位码三者之间的关系为:区位码(十进制)的两个字节分
别转换为十六进制后加20H得到对应的国标码;机内码是汉字交换码(国标码)两个字节的最高位分别加1,即汉字交换码(国标码)的两个字节分别加80H得到对应的机内码;区位码(十进制)的两个字节分别转换为十六进制后加A0H得到对应的机内码。
举例:机内码为BEDF,求区位码。
有两种解法:1.BEDFH-A0A0H=1E3FH=3063D;
2.BEDFH-8080H=3E5FH,3E5FH-2020H=1E3FH =3063D.。