层次分析法(APH)
层次分析法(详解)
第六章层次分析法决策是人们选择或进行判断的一种思维活动,在人们的实践活动中,常常要对某些系统的重要性作出恰当的评价,以便列出它们的轻重缓急,从而集中解决重要的问题。
有些决策是简单易断的,而有些决策则是复杂困难的,因此常常先把复杂问题分解成因素,然后把这些因素按支配关系分组形成有序的递阶层次结构,并衡量各方面的影响,最后综合人的判断,以决定决策诸因素相对重要性的先后优劣次序,这就是层次分析法的基本思路。
层次分析法的(Analytic Hierarchy Process 简记为AHP)是美国著名的运筹学家T.L.Saaty 教授于70年代初首先提出的一种定性与定量分析相结合的多准则决策方法。
该方法是社会、经济系统决策的有效工具,目前在工程计划、资源分配、方案排序、政策制定、冲突问题、性能评价等方面都有广泛的应用。
6.1 层次分析法的基本原理层次分析法的核心问题是排序,包括递阶层次结构原理、测度原理和排序原理。
下面分别予以介绍。
1.递阶层次结构原理。
一个复杂的结构问题可分解为它的组成部分或因素,即目标、准则、方案等。
每一个因素称为元素。
按照属性的不同把这些元素分组形成互不相交的层次,上一层次的元素对相邻的下一层次的全部或部分元素起支配作用,形成按层次自上而下的逐层支配关系。
具有这种性质的层次称为递阶层次。
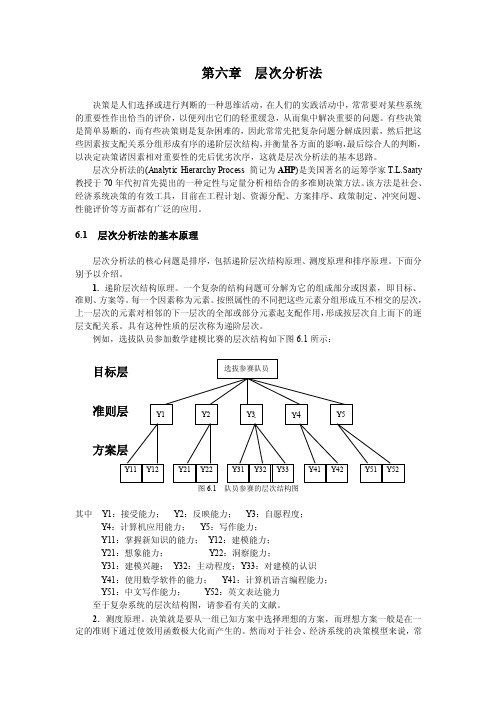
例如,选拔队员参加数学建模比赛的层次结构如下图6.1所示:图6.1 队员参赛的层次结构图其中Y1:接受能力;Y2:反映能力;Y3:自愿程度;Y4:计算机应用能力;Y5:写作能力;Y11:掌握新知识的能力;Y12:建模能力;Y21:想象能力;Y22:洞察能力;Y31:建模兴趣;Y32:主动程度;Y33:对建模的认识Y41:使用数学软件的能力;Y41:计算机语言编程能力;Y51:中文写作能力;Y52:英文表达能力至于复杂系统的层次结构图,请参看有关的文献。
2.测度原理。
决策就是要从一组已知方案中选择理想的方案,而理想方案一般是在一定的准则下通过使效用函数极大化而产生的。
层次分析法

P P2 P 1 3
P1 1 1 1 / 4 B5 = P2 1 1 1 / 4 P3 4 4 1
此时, 此时,W是A的特征向量,n是A的特征根 的特征向量,
重要性比较后得到的比较矩阵A 重要性比较后得到的比较矩阵A不 一定满足一致性矩阵的条件! 一定满足一致性矩阵的条件!
C1 C2 C3 C4 C5
C1 1 C2 2 1/ 4 A = C3 C4 1/ 3 C5 1/ 3 1/ 2 1 1/ 7 1/ 5 1/ 5 4 3 3 7 5 5 1 1/ 2 1/ 3 2 1 1 3 1 1
层次分析法的基本步骤如下 1.建立层次结构模型 1.建立层次结构模型 2.构造成对比较矩阵 2.构造成对比较矩阵 3.计算单排序权向量并做一致性检验 3.计算单排序权向量并做一致性检验 4.计算总排序权向量并做一致性检验 4.计算总排序权向量并做一致性检验
层次分析法的基本步骤
1 建立层次结构模型 一般分为三层,最上面为目标层, 一般分为三层,最上面为目标层,最 下面为方案层,中间是准则层或指标层。 下面为方案层,中间是准则层或指标层。
A = a ij
( )
由上述定义知, 由上述定义知,成对比较矩阵
n× n
满足以下性质
1 aij > 0
1 2 a ij = a ji
3 a ii = 1
则称为正互反阵。 则称为正互反阵。 正互反阵
比如,在旅游问题中,第二层 的 比如,在旅游问题中,第二层A的 各因素对目标层Z的影响两两比较结果 各因素对目标层 的影响两两比较结果 如下: 如下:
相对于景色
P1 P2 P3
相对于费用
P1 P2 P3
层次分析法简单介绍

层次分析法层次分析法(AHP)又称多层次权重分析法,是一种用于定性分析的多目标分析方法。
它能有效地分析指标体系各层次之间排序关系,有效地综合衡量和判断评价者的意图。
适用于多目标、多准则、多因素、难以量化的大型复杂系统,已广泛应用于资源系统分析、建设管理、交通、评标、经济评价等各个社会领域。
层次分析法解决复杂问题的基本思想是:首先,将总目标进行分层,并根据各个指标之间隶属关系和相关影响,将各个指标按不同层次进行分类。
形成指标层、准则层和目标层,然后利用层次分析法,求本各层次的指标对上一层次指标的权重,然后利用最大特征值方法依次归并,最终求出总目标权重系数。
指标越重要,其指标权重系数越大。
因此,层次分析方法的计算需要以下步骤:(1)建立层次结构模型首先,将问题分解为不同的组成部分,并根据各个指标之间的相互影响和隶属关系,对各指标进行分组和组合,形成多层次结构,相对于确定最高层的综合相对重要性系数,即相对优序,系统分析被简化到最底层。
(2)调查问卷设计,对同一层次的指标将进行重要性等级进行两两访问对比,确定其重要性,然后利用比例标度法,。
构成比较判断矩阵。
表1-1 比例标度法Table4-1 Proportional scaling method两指标影响比较相等稍微重要明显重要非常重要极其重要δ1113579(3)调查对象的构成在选择范围上,主要选择具有绿色施工、绿色建筑、节能环保等研究领域的高校专家和学者、建设单位项目管理人员、工程项目施工单位工作人员和涉及环保监督政府人员。
(4)整理分析问卷并构建判断矩阵整理出问卷中的信息,并将问卷中信息进行汇总分析,计算出各因素的要性程度,建立判断矩阵。
见表1-2。
表1-2 各因素相对重要性判断矩阵Table4-2 Relative importance judgment matrixB k B 1 B 2 B n B 1 δ11 δ12 ... δ1n B 2 δ21 δ22 ... δ2n ... ... ... ... ... B nδn1δn2...δnn其中,δij 是对于A k 而言,B i 对B j 的相对重要性的数值表示,δij 是δi 与δj 的比值。
层次分析法
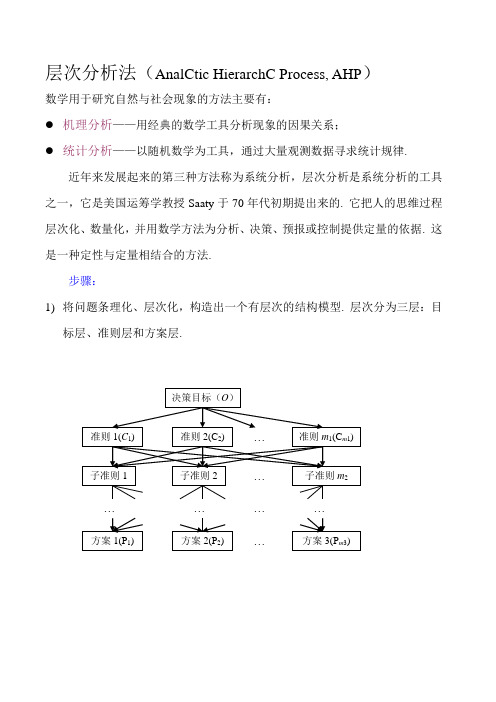
层次分析法(AnalCtic HierarchC Process, AHP )数学用于研究自然与社会现象的方法主要有:● 机理分析——用经典的数学工具分析现象的因果关系;● 统计分析——以随机数学为工具,通过大量观测数据寻求统计规律.近年来发展起来的第三种方法称为系统分析,层次分析是系统分析的工具之一,它是美国运筹学教授Saaty 于70年代初期提出来的. 它把人的思维过程层次化、数量化,并用数学方法为分析、决策、预报或控制提供定量的依据. 这是一种定性与定量相结合的方法. 步骤:1) 将问题条理化、层次化,构造出一个有层次的结构模型. 层次分为三层:目标层、准则层和方案层.………… …2) 比较同一层次元素对上一层次同一目标的影响,从而确定题目在目标中所占的比重. 采用两两比较的方法,求出它们对于同一个目标的重要性的比例标度,标度等级为1, 2, …, 9, 1/2, 1/3, …, 1/9. 得到两两比较判断矩阵. 1—9标度的含义为:1—两个元素同等重要(相等) 3—前者稍重要(较强) 5—前者明显重要(强) 7—前者强烈重要(很强) 9—前者极端重要(绝对强) 2,4,6,8为上述判断的中间值.3) 确定各准则对于目标的权重,及各方案对于每一准则的权重. (在单一准则下计算元素相对排序权重,以及判断矩阵一致性检验.) 4) 计算方案层中元素对于目标层的总排序权重,从而确定首选方案.(将方案层对准则层的权重及准则层对目标层的权重进行综合,最终确定方案层对目标层的权重.)成对比较法,正互反阵和一致阵设要比较的n 个因素C ={C 1, …, C n }对目标O 的影响,确定它们在O 中的比重. 每次取两个因素C i 和C j ,用a ij 表示对C i 和C j 对O 的影响之比:a ij >0, a ji =1ija (i , j =1, 2, …, n ) (1) A=(a ij )称为成对比较阵或判断矩阵. 满足(1)的矩阵称为正互反阵. 成对比较阵是正互反阵.例如:考虑旅游问题. 设有三个地点供选择:桂林P 1、黄山P 2、北戴河P 3. 问如何在三个目的地中按照:费用C 1,景色C 2,居住C 3,饮食C 4,交通C 5这五个因素进行选择.设某人用成对比较法得到的成对比较阵为127551/214331/71/411/21/31/51/32111/51/3311A ⎛⎫⎪⎪⎪ ⎪⎪ ⎪⎝⎭= (2)其中a 12表示费用C 1与景色C 2对选择旅游地这个目标O 的重要性之比为2:1, a 13表示费用C 1与居住条件C 3之比为7:1, a 23表示景色C 2与居住条件C 3之比为4:1,可以看出此人在选择旅游地时,费用因素最重,景色次之,居住条件再次. 怎样由成对比较阵确定诸因素C 1,C 2,…,C n 对上层因素O 的权重呢? 分析:(2)式给出的成对比较阵A 中,C 1与C 2之比为2:1, C 2与居住条件C 3之比为4:1,那么C 1与C 3之比应为8:1, 但C 1与C 3之比为7:1,这种情况称为这三个因素成对比较不一致. (即a 12·a 23=2·4≠7= a 13)全部一致的要求太苛刻,因此Saaty 等人给出了在成对比较不一致的情况下计算各因素C 1,C 2,…,C n 对上层因素O 的权重的方法.设想把一块单位重量的大石头O 砸成n 块小石头C 1,C 2,…,C n ,如果精确地称出它们的重量为12,,,n w w w ,在作成对比较时有a ij =ijw w ,则得到111122221212n n n n n n w w w w w w w w w A w w w w w w ⎛⎫⎪ ⎪ ⎪⎪ ⎪ ⎪⎪⎪⎪⎝⎭= (3) 这些比较显然是一致的. n 块小石头对大石头的权重(即在大石头中的重量之比)可用向量12(,,,)Tn w w w =w 表示,且11ni i w ==∑. 显然A 的各个列向量与w 仅相差一个比例因子.一致阵:如果一个正互反阵A 满足a ij ·a jk =a ik (i , j , k =1, 2, …, n ) (4)则称A 为一致阵.例如矩阵1261/2131/61/31A ⎛⎫⎪⎪ ⎪⎝⎭= (5) 是一致阵.可以验证:若A 为n 阶一致矩阵,则有 A n =w wn 阶一致阵A 有下列性质: (1)A 的秩为1;(2)A 的最大特征根为max n λ=,其余特征根均为零 (3)n 阶正互反阵是一致阵⇔max n λ=.例如 (5)中矩阵为一致阵,则max 3λ=.权向量:max λ的标准化特征向量: (1) 一致阵的权向量:例如(5)中矩阵1261/2131/61/31A ⎛⎫⎪⎪ ⎪⎝⎭=为一致矩阵,则max 3λ=,权向量为max λ的标准化特征向量:(0.6,0.3,0.1)T =w(2) 不一致阵的权向量:例如 1261/2141/61/41A ⎛⎫⎪⎪ ⎪⎝⎭=,max 3.01λ=,(0.588,0.322,0.09)T =w max λ比n 大得越多,A 不一致的程度就越严重,用w 表示C 1,C 2,…,C n 在O 中所占比重时的偏差就越大.附:求特征值特征向量的matlab 程序 >>A=[1 2 6; 1/2 1 4; 1/6 1/4 1];>>[x,D]=eig(A) %x 为特征向量,D 的主对角线元素为特征值一致性指标衡量不一致程度的数量指标叫做一致性指标. Saaty 将他定义为max 1n CI n λ-=-对于一致阵,一致性指标CI =0.CI 越大,A 的不一致性程度越严重.为了找出衡量一致性指标CI 的标准,Saaty 提出一种方法. 对固定的n ,随机地构造正互反阵A ,其中ij a ()i j <随机地从1/9,,1/2,1,2,,9 当中取出一数,由于其随机性,这样的A是非常不一致的,它的CI 相当大. 如此构造相当多的A,用它们的CI 的平均值作为随机一致性指标. Saaty 对于不同的n ,用100~500个样本A算出最大特征值的平均值max λ ,定义随机性指标为 max 1n RI n λ-=- 得到RI 的数值如下表所示表:随机性指标RI 的值(计算RI 的过程:对于固定的n ,随机的构造正互反矩阵A ’(它的元素a ij ’(i<j )从1~9,1~1/9中随机取值),然后计算A ’ 的一致性指标CI . 可以想到,A ’是非常不一致的,它的CI 相当大. 如此构造相当多的A ’,用它们的CI 的平均值作为随机一致性指标. Saaty 对于不同的n ,用100~500个样本A ’ 算出的随机一致性指标RI 的数值如上表所示)当C I <0.1RI时,认为A 的不一致性仍可接受. 称 CICR RI=为一致性比率指标,当CR <0.1时,认为判断矩阵的一致性是可以接受的.下面介绍计算最大特征值max λ和特征向量w 的一种近似方法(和法),步骤如下:a. 将A 的各个列向量归一化得1ˆijijij ni a a w==∑;b. 对ˆij w按行求和得1ˆˆni ij i w w ==∑; c. 将ˆi w 归一化1ˆˆii i ni ww w ==∑,12(,,,)T n w w w w = 即为近似特征向量;d. 计算1max ˆ()1ˆˆn i i iA n λ==∑w w,作为最大特征根的近似值.这个方法实际上是将A 的列向量归一化后取平均值,作为A 的特征向量. 因为当A 为一致阵时它的每一列向量都是特征向量,所以若A 的不一致性不严重,则取A 的列向量(归一化后)的平均值作为近似特征向量是合理的.例如:1261/2141/61/41A ⎛⎫⎪⎪ ⎪⎝⎭= 列向量归一化0.60.6150.5450.30.3080.3640.10.0770.091⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭按行求和1.7600.9720.268⎛⎫ ⎪⎪ ⎪⎝⎭ 归一化0.5870.3240.089w ⎛⎫ ⎪ ⎪ ⎪⎝⎭=,Aw =1.7690.9740.268⎛⎫⎪⎪ ⎪⎝⎭max 11.7690.9740.268 3.00930.5870.3240.089ˆλ⎛⎫ ⎪ ⎪⎝⎭=++= 精确计算给出()0.5880.3220.090Tw =, 3.010λ=. 二者相比相差甚微.max 3.00930.00450.10.582ˆ1n CI n λ-==<⨯-=-3n =时,RI =0.58,0.1CIRI< ∴ 认为A 的不一致性是可以接受的. 课堂练习:判断矩阵W=136115311165⎛⎫ ⎪ ⎪⎪ ⎪ ⎪ ⎪⎝⎭的一致性是否可以接受. 回到旅游问题(1)先确定准则层关于目标层的比重 准则层关于目标层的成对比较阵为127551/214331/71/411/21/31/51/32111/51/3311A ⎛⎫⎪⎪ ⎪ ⎪⎪ ⎪⎝⎭=列向量归一化0.48950.51060.41180.47620.48390.24480.25530.23530.28570.29030.06990.06380.05880.04760.03230.09790.08510.11760.09520.09680.09790.08520.17650.09530.0967A ⎛⎫⎪⎪ ⎪ ⎪⎪ ⎪⎝⎭=按行求和 2.37201.31140.27240.49260.5516⎛⎫⎪⎪⎪ ⎪⎪⎪⎝⎭ 归一化0.47440.26230.05450.09850.1103⎛⎫ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭=ˆw ˆ(2.4245,1.3439,0.2739,0.5001,0.5546)T A =wm a x ˆλ1 2.42451.34390.27390.50010.5546() 5.072950.47440.26230.05450.09850.1103=++++= m a x 0.07290.01824ˆ1n CI n λ==-=- 5n =时,RI =1.12,0.1CIRI<故A 的不一致性可以接受A .()C w =ˆw =0.47440.26230.05450.09850.1103⎛⎫ ⎪ ⎪⎪ ⎪ ⎪ ⎪ ⎪⎝⎭代表C 1,C 2,C 3,C 4,C 5在O 中分别所占比重,即准则层关于目标层的比重已确定.(2)再确定方案层关于准则层的比重设123{,,}P P P P =对i C 的成对比较阵为:1111381313831B ⎛⎫ ⎪ ⎪ ⎪ ⎪ ⎪⎪ ⎪⎝⎭= 212511211152B ⎛⎫⎪ ⎪⎪⎪ ⎪ ⎪ ⎪⎝⎭= 113113311133B ⎛⎫ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭= 413411131114B ⎛⎫⎪ ⎪⎪ ⎪ ⎪⎪ ⎪⎝⎭= 511141114441B ⎛⎫ ⎪ ⎪ ⎪ ⎪⎪ ⎪ ⎪⎝⎭=由于3n =, 0.58RI =,故()/0.1i RI CI <(1,2,...,5)i =,所以51B B 的不一致性都可以接受.最终目的是要得到123,,P P P 在O 中所占的比重. (3)确定方案层关于目标层的比重123()((),(),())P w P w P w P =w11()()()C C P P =w w w0.0820.460.5950.260.4=⨯+⨯+⨯ 0.6330.10.1660.13+⨯+⨯0.299= 22()()()0.245C C P P ==w w w 33()()()0.456C C P P ==w w w()(0.299,0.2450.456),T P =w3P 为第一选择.总结:AHP 的计算步骤1) 建立系统的层次结构,一般分为三层:目标层、准则层和方案层 2) 给出方案之间、准则之间的两两比较矩阵; 3) 计算每个矩阵的特征向量; 4) 计算每个矩阵的最大特征值; 5) 一致性检验; 6) 方案的总排序.附录方阵的特征值与特征向量定义1 设A 是n 阶方阵,如果存在λ和n 维非零列向量x ,使得λ=Ax x ,则称数λ为的A 特征值,并称非零列向量x 为A 的属于λ的特征向量.例如:对1221A ⎛⎫ ⎪ ⎪⎝⎭=,有λ=3及向量11x ⎛⎫ ⎪ ⎪⎝⎭=,使得1221⎛⎫ ⎪ ⎪⎝⎭31111⎛⎫⎛⎫= ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭,这说明λ=3是A 的特征值,11x ⎛⎫ ⎪ ⎪⎝⎭=是A 对应于λ=3的特征向量. 对于这个定义我们应注意到:特征向量≠0x . 否则由于对任何数λ,都有λ=00A ,从而任何数都是A 的特征值,这样的定义显然是不合理的。
层次分析法基本原理、实施步骤、应用实例

判断矩阵是表示本层所有因素针对上一层某一个因素的 相对重要性的比较。判断矩阵的元素aij用Santy的1—9标 度方法给出。
心理学家认为成对比较的因素不宜超过9个,即每层 不要超过9个因素。
判断矩阵元素aij的标度方法
标度 1 3 5 7 9
2,4,6,8 倒数
含义 表示两个因素相比,具有同样重要性 表示两个因素相比,一个因素比另一个因素稍微重要 表示两个因素相比,一个因素比另一个因素明显重要 表示两个因素相比,一个因素比另一个因素强烈重要 表示两个因素相比,一个因素比另一个因素极端重要
• 这一过程是从最高层次到最低层次依次进行的。
Z
定义一致性指标: CI n
n 1
CI=0,有完全的一致性
CI接近于0,有满意的一致性
CI 越大,不一致越严重
为衡量CI 的大小,引入随机一致性指标 RI。方法为
随机构造500个成对比较矩阵 A1, A2 , , A500
则可得一致性指标 CI1,CI2 , ,CI500
RI
CI1
定理:n 阶一致阵的唯一非零特征根为n
定理:n 阶正互反阵A的最大特征根 n, 当且仅当 =n
时A为一致阵
由于λ 连续的依赖于aij ,则λ 比n 大的越多,A 的不 一致性越严重。用最大特征值对应的特征向量作为 被比较因素对上层某因素影响程度的权向量,其不 一致程度越大,引起的判断误差越大。因而可以用 λ-n 数值的大小来衡量 A 的不一致程度。
但允许范围是 多大?如何界 定?
Aw w
3. 层次单排序及其一致性检验
对应于判断矩阵最大特征根λmax的特征向量,经 归一化(使向量中各元素之和等于1)后记为W。
层次分析法

第四、层次分析法的优点与局限
• 优越性
• 更好地分化歧义句式
• 有助于发现新的语法现 象,揭示新的语法规律
• 局限性:
它只能揭示句法结构的的 构造层次和直接组成成分之 间的显性的语法关系,即语 法结构关系,不能揭示句法 结构内部隐性的语法关系, 即语义结构关系。
b.分别分析两个直接成分,层层 二分,到词为止。
通过分析明确分析对象的结构类型。 通过分析可以知道: ①属于主谓句、动宾谓语句; ②属于非主谓句、动词性非主谓句; ③属于非中谓句、动词性非主谓句。
2)“由小到大”的过程
a.先找出构成分析对象的各个基本单位(通 常是词)。
b.按照组合的顺序,尝试有两个基本单位构 成一个较大的结构体,同时表明每个结构体内 部两个基本单位之间的语法关系。依此程序, 再由这些较大的结构组合成更大的结构,直到 构成整个分析对象为止。
传统的“句子成分分析法”(中心词分析法) 在分化句子歧义、揭示某些词语用法特点的能力比 较弱,为了进一步探索句法结构的组成特点,层次 分析法应运而生。(参看注)
二、句法结构的层次性以及其证明过程:
1、什么是句法结构的层次性?
一个复杂句法结构里,词和词的组合有 着层次的透景,各个组成成分总是按一定的 句法规则一层一层的进行组合的(并非总是 相邻的发生联系)。这种句法结构的构造特 性,称为“句法结构的层次性”。 注:①语言结构的层次性是语言结构基本属 性之一。
2、“层次分析法”用于描写语言现象的历史介绍
• 注:①层次分析法源于美国描写语言学派,首先由美
国语言学家Bloomfield提出并建立(Language)。他
指出了语言结构是有层次性的,并用层次分析法分析 语言结构形式。
层次分析法

19
(5)层次总排序 )
各个方案优先程度的排序向量为:
0.263 0.595 0.082 0.429 0.633 0.166 0.475 0.300 = 0.246 W = W ( 3)W ( 2)= 0.277 0.236 0.429 0.193 0.166 0.055 0.129 0.682 0.142 0.175 0.668 0.099 0.456 0.110
1 Aw = 1 / 2 1 / 6
2 1 1/ 4
6 4 1
0 . 587 0 . 324 0 . 089
=
1 . 769 0 . 974 0 . 268
12
判断矩阵的一致性检验
λ 判断矩阵通常是不一致的,但是为了能用它的对应于特 征根的特征向量作为被比较因素的权向量,其不一致程度应 在容许的范围内.如何确定这个范围? CI=0 时A一致; CI = λ − n (1)一致性指标: n −1 CI 越大,A的不一致性程度 越严重。 (2)随机一致性指标RI:
常 规 思 维 过 程
确定这些准则在你心目中各占的比重多大; 确定这些准则在你心目中各占的比重多大;
就每一准则将三个地点进行对比; 就每一准则将三个地点进行对比;
将这两个层次的比较判断进行综合,作出选择。 将这两个层次的比较判断进行综合,作出选择。
4
1
目标层Z 景 层C 色
层
选择旅游目的地
的 目标
目标
费 用 住
居 食
饮 途
旅
的
层P
P 1
P2
P3
层次分析法

1 B3 1 1 / 3 1 1 1/3 3 3 `1
相对于饮食
1 B4 1 / 3 1 / 4 3 1 1 4 1 `1
相对于旅途
1 B5 1 4 1 1 4 1/4 1/4 1
2
层次分析法案例:选择旅游地
例如:假期旅游,现有三个目的地可供选择(方案):风 光绮丽的杭州 P1 ,迷人的北戴河 P2 ,山水甲天下的桂 林 P3 。可供考虑的因素有:景色、费用、居住、饮食、 旅途情况。
如何在3个目的地中按照景色、费用、居住、 饮食、旅途5个准则进行选择.
RI=1.12 (查表)
CR=0.018/1.12=0.016<0.1
17
3. 层次单排序
所谓层次单排序是指,对于上一层某因素而言,本层 次各因素的重要性的排序。
具体计算是:
对于判断矩阵 B,计算满足
B w m ax w
w 的特征值和特征向量,式中 max 为 B 的最大特征值, 为 对应于 max 的单位化的特征向量,w 的分量 i 即是相应元
0 . 082 0 . 236 0 . 682
0 . 429 0 . 429 0 . 142
0 . 633 0 . 193 0 . 175
0 . 263 0 . 166 0 . 475 0 . 166 0 . 055 0 . 668 0 . 099 0 . 110
9
一致性矩阵
一块单位重量的石头砸成n块小石头, 其重量分 别为 w1 , w 2 , w n .
令 a ij w i / w j
w1 w 1 w2 A w1 w n w1 w1 w2 w2 w2 w1 wn w2 wn wn wn
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二、层次分析法(APH)
2.1.1正互反矩阵
则称A为正互反矩阵。
1
3
4
1
2.1.2层次分析法的步骤
(1)建立层次结构模型:
判断矩阵A=Iaj应为正互反矩阵,而且 aij的判断如下(1~9尺度法):
G与Cj
比 相等 较强 强 很强 绝对强
a
ij
1 3 5 7 9
(3 )单层排序及一致性检验
1、单层排序
求解判断矩阵 A的最大特征值 ’max,再由最大特征值求出对应的特征向量
-'A
,二’max,
'
,并将••标准化,即为同一层相对于上一层某一因素的权重,根据此
右矩阵A = a」满足
m n
aij 0
;②
a
” =
1
a
ji
如:
目标层0
准则层C
方案层P
(2)构造判断矩阵
P2 P4
P
1
P3
决策目标
准则C1
准则C2 准则Cn
权重的大小,便可确定该层因素的排序。
2、一致性检验
取一致性指标Cl =Ax n,(n为A的阶数)
n —1
取随机性指标 Rl如下:
n
1 2 3 4 5 6 7 8
9
Rl
0 0 0.58 0.9 1.12 1.24 1.32 1.41 1.45
Cl
令CR ,若CR ::: 0.1,则认为A具有一致性。
Rl
否则,需要对 A进行调整,直到具有满意的一致性为止。
(4)层次总排序及一致性检验
假定准则层C1,C2JH,Cn排序完成,其权重分别为a1,a2^|,an,方案层P包含m个方 案:R,P2」
ll,Rm。其相对于上一层的 Cj( j =1,2,|H,n )对方案层P中的m
个方案进行单
层排序,其排序权重记为b.j,b2j,|||,bmj j=1,2,|||,n,则方案层P中第i个方案Pi的总
n
排序权重为a ajbij,见下表:
j
生
次C
层次P
C
1 C2 …
C
n
P
层总排序权重
a1 a2 ・-- a
n
P bn b
12
・』』
b
1n
n
为
ajb
1j
j
吕
P
2
b21 b22 ・* b
2n
n
为
ajb
2j
j#
■l!
K
* * *
*
+
Pn bm1 b
m2
・•-
b
mn
n
壬
ajb
mj
j#
从而确定P层的排序。
例:(企业利润分配模型)
方案:发奖金(R ),建基础设施(R ),办培训班(巳),建俱乐部(P4 ),引进新设备
(
R
)。
解:(1)建立层次结构模型
(2)构造判断矩阵O-C
1
3
3 ,求得扎max =3.0385 ,得到⑷,将㈢标准化㈢=(0.105, 0.632, 0.258)
1
(3)构造判断矩阵 C! - P、C2 - P、c3 - P
二 0.491,0.232,0.092,0.138,0.046 二
0. 055, 0. 564, 0. 1 18, 0.2034 06,0.406,0. 094, 0. 094
(4)层次总排序
CI =0.0193 RI =0. 58 CR = 0. 0 3 3:2 0.
(具有满意的一致性)
目标层o
准则层C
方案层P
1
5
1
1
3
G -P
C2 - P
C3 -P
1
-13 2 5
3
111
一 一 1 一
3
5 3 2
1 1
--2 1 3
4 2
1111
一 一 一 一
1
‘1 1
1 1
1 1
3 3
1 1
<3 3
max -5.126 max = 4.117 max
合理使用
利润
3 5
C1 C2 C
3
- 方案总排序
0.105 0.63 0.258
P
0.491 0 0.406 0.157
P
2
0.232 0.055 0.406 0.164
P
3
0.092 0.564 0.094 0.393
P
4
0.138 0.118 0.094 0.113
P
5
0.046 0.263 0 0.172
排序结果为:
P3.F5.P2.P1.F
4