中科院数据挖掘作业答案1

大工20春《数据挖掘》课程大作业满分答案
网络教育学院 《数据挖掘》课程大作业 题目: 姓名: 学习中心: 第一大题:讲述自己在完成大作业过程中遇到的困难,解决问题的思路,以及相关感想,或者对这个项目的认识,或者对Python与数据挖掘的认识等等,300-500字。 《数据挖掘》这门课程是一门实用性非常强的课程,数据挖掘是大数据这门前沿技术的基础,拥有广阔的前景,在信息化时代具有非常重要的意义。数据挖掘的研究领域非常广泛,主要包括数据库系统、基于知识的系统、人工智能、机器学习、知识获取、统计学、空间数据库和数据可视化等领域。学习过程中,我也遇到了不少困难,例如基础差,对于Python基础不牢,尤其是在进行这次课程作业时,显得力不从心;个别算法也学习的不够透彻。在接下来的学习中,我仍然要加强理论知识的学习,并且在学习的同时联系实际,在日常工作中注意运用《数据挖掘》所学到的知识,不断加深巩固,不断发现问题,解决问题。另外,对于自己掌握不牢的知识要勤复习,多练习,使自己早日成为一名合格的计算机毕业生。 第二大题:完成下面一项大作业题目。
2020春《数据挖掘》课程大作业 注意:从以下5个题目中任选其一作答。 题目一:Knn算法原理以及python实现 要求:文档用使用word撰写即可。 主要内容必须包括: (1)算法介绍。 (2)算法流程。 (3)python实现算法以及预测。 (4)整个word文件名为 [姓名奥鹏卡号学习中心](如 戴卫东101410013979浙江台州奥鹏学习中心[1]VIP )作业提交: 大作业上交时文件名写法为:[姓名奥鹏卡号学习中心](如:戴卫东101410013979浙江台州奥鹏学习中心[1]VIP) 以附件形式上交离线作业(附件的大小限制在10M以内),选择已完成的作业(注意命名),点提交即可。如下图所示。 。 注意事项: 独立完成作业,不准抄袭其他人或者请人代做,如有雷同作业,成绩以零分计!
数据挖掘简介
数据挖掘综述
数据挖掘综述 摘要:数据挖掘是一项较新的数据库技术,它基于由日常积累的大量数据所构成的数据库,从中发现潜在的、有价值的信息——称为知识,用于支持决策。数据挖掘是一项数据库应用技术,本文首先对数据挖掘进行概述,阐明数据挖掘产生的背景,数据挖掘的步骤和基本技术是什么,然后介绍数据挖掘的算法和主要应用领域、国内外发展现状以及发展趋势。 关键词:数据挖掘,算法,数据库 ABSTRACT:Data mining is a relatively new database technology, it is based on database, which is constituted by a large number of data coming from daily accumulation, and find potential, valuable information - called knowledge from it, used to support decision-making. Data mining is a database application technology, this article first outlines, expounds the background of data mining , the steps and basic technology, then data mining algorithm and main application fields, the domestic and foreign development status and development trend. KEY WORDS: data mining ,algorithm, database 数据挖掘产生的背景 上世纪九十年代.随着数据库系统的广泛应用和网络技术的高速发展,数据库技术也进入一个全新的阶段,即从过去仅管理一些简单数据发展到管理由各种计算机所产生的图形、图像、音频、视频、电子档案、Web页面等多种类型的复杂数据,并且数据量也越来越大。在给我们提供丰富信息的同时,也体现出明显的海量信息特征。信息爆炸时代.海量信息给人们带来许多负面影响,最主要的就是有效信息难以提炼。过多无用的信息必然会产生信息距离(the Distance of Information-state Transition,信息状态转移距离,是对一个事物信息状态转移所遇到障碍的测度。简称DIST或DIT)和有用知识的丢失。这也就是约翰·内斯伯特(John Nalsbert)称为的“信息丰富而知识贫乏”窘境。因此,人们迫切希望能对海量数据进行深入分析,发现并提取隐藏在其中的信息.以更好地利用这些数据。但仅以数据库系统的录入、查询、统计等功能,无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势。更缺乏挖掘数据背后隐藏知识的手段。正是在这样的条件下,数据挖掘技术应运而生。 数据挖掘的步骤 在实施数据挖掘之前,先制定采取什么样的步骤,每一步都做什么,达到什么样的目标是必要的,有了好的计划才能保证数据挖掘有条不紊的实施并取得成功。很多软件供应商和数据挖掘顾问公司投提供了一些数据挖掘过程模型,来指导他们的用户一步步的进行数据挖掘工作。比如SPSS公司的5A和SAS公司的SEMMA。 数据挖掘过程模型步骤主要包括:1定义商业问题;2建立数据挖掘模型;3分析数据;4准备数据;5建立模型;6评价模型;7实施。 1定义商业问题。在开始知识发现之前最先的同时也是最重要的要求就是了
大数据时代下的数据挖掘试题和答案及解析
A. 变量代换 B. 离散化 海量数据挖掘技术及工程实践》题目 、单选题(共 80 题) 1) ( D ) 的目的缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得 到 和原始数据相同的分析结果。 A. 数据清洗 B. 数据集成 C. 数据变换 D. 数据归约 2) 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数 据挖 掘的哪类问题 (A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3) 以下两种描述分别对应哪两种对分类算法的评价标准 (A) (a) 警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b) 描述有多少比例的小偷给警察抓了的标准。 据相分离 (B) 哪一类任务 (C) A. 根据内容检索 B. 建模描述 7) 下面哪种不属于数据预处理的方法 (D) A. Precision,Recall B. Recall,Precision A. Precision,ROC D. Recall,ROC 4) 将原始数据进行集成、 变换、维度规约、数值规约是在以下哪个步骤的任务 (C) 5) A. 频繁模式挖掘 C. 数据预处理 B. D. 当不知道数据所带标签时, 分类和预测 数据流挖掘 可以使用哪种技术促使带同类标签的数据与带其他标签的数 6) A. 分类 C. 关联分析 建立一个模型, B. D. 聚类 隐马尔可夫链 通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的 C. 预测建模 D. 寻找模式和规则
C.聚集 D. 估计遗漏值 8) 假设12 个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15 在第几个箱子内(B) A. 第一个 B. 第二个 C. 第三个 D. 第四个 9) 下面哪个不属于数据的属性类型:(D) A. 标称 B. 序数 C.区间 D. 相异 10) 只有非零值才重要的二元属性被称作:( C ) A. 计数属性 B. 离散属性 C.非对称的二元属性 D. 对称属性 11) 以下哪种方法不属于特征选择的标准方法:(D) A. 嵌入 B. 过滤 C.包装 D. 抽样 12) 下面不属于创建新属性的相关方法的是:(B) A. 特征提取 B. 特征修改 C. 映射数据到新的空间 D. 特征构造 13) 下面哪个属于映射数据到新的空间的方法(A) A. 傅立叶变换 B. 特征加权 C. 渐进抽样 D. 维归约 14) 假设属性income 的最大最小值分别是12000元和98000 元。利用最大最小规范化的方 法将属性的值映射到0 至 1 的范围内。对属性income 的73600 元将被转化为:(D) 15) 一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130 人,四年 级110 人。则年级属性的众数是:(A) A. 一年级 B. 二年级 C. 三年级 D. 四年级 16) 下列哪个不是专门用于可视化时间空间数据的技术:(B) A. 等高线图 B. 饼图
《大数据时代下的数据挖掘》试题及答案要点
《海量数据挖掘技术及工程实践》题目 一、单选题(共80题) 1)( D )的目的缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到 和原始数据相同的分析结果。 A.数据清洗 B.数据集成 C.数据变换 D.数据归约 2)某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖 掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3)以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision,Recall B. Recall,Precision A. Precision,ROC D. Recall,ROC 4)将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 5)当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数 据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6)建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的 哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7)下面哪种不属于数据预处理的方法? (D) A.变量代换 B.离散化
C.聚集 D.估计遗漏值 8)假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A.第一个 B.第二个 C.第三个 D.第四个 9)下面哪个不属于数据的属性类型:(D) A.标称 B.序数 C.区间 D.相异 10)只有非零值才重要的二元属性被称作:( C ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 11)以下哪种方法不属于特征选择的标准方法: (D) A.嵌入 B.过滤 C.包装 D.抽样 12)下面不属于创建新属性的相关方法的是: (B) A.特征提取 B.特征修改 C.映射数据到新的空间 D.特征构造 13)下面哪个属于映射数据到新的空间的方法? (A) A.傅立叶变换 B.特征加权 C.渐进抽样 D.维归约 14)假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方 法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A.0.821 B.1.224 C.1.458 D.0.716 15)一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130人,四年 级110人。则年级属性的众数是: (A) A.一年级 B.二年级 C.三年级 D.四年级
数据挖掘的功能及应用作业
数据挖掘的其他基本功能介绍 一、关联规则挖掘 关联规则挖掘是挖掘数据库中和指标(项)之间有趣的关联规则或相关关系。关联规则挖掘具有很多应用领域,如一些研究者发现,超市交易记录中的关联规则挖掘对超市的经营决策是十分重要的。 1、 基本概念 设},,,{21m i i i I =是项组合的记录,D 为项组合的一个集合。如超市的每一张购物小票为一个项的组合(一个维数很大的记录),而超市一段时间内的购物记录就形成集合D 。我们现在关心这样一个问题,组合中项的出现之间是否存在一定的规则,如A 游泳衣,B 太阳镜,B A ?,但是A B ?得不到足够支持。 在规则挖掘中涉及到两个重要的指标: ① 支持度 支持度n B A n B A )()(?= ?,显然,只有支持度较大的规则才是较有价值的规则。 ② 置信度 置信度)() ()(A n B A n B A ?=?,显然只有置信度比较高的规则才是比较可靠 的规则。 因此,只有支持度与置信度均较大的规则才是比较有价值的规则。 ③ 一般地,关联规则可以提供给我们许多有价值的信息,在关联规则挖掘时,往往需要事先指定最小支持度与最小置信度。关联规则挖掘实际上真正体现了数据中的知识发现。 如果一个规则满足最小支持度,则称这个规则是一个频繁规则; 如果一个规则同时满足最小支持度与最小置信度,则通常称这个规则是一个强规则。 关联规则挖掘的通常方法是:首先挖掘出所有的频繁规则,再从得到的频繁规则中挖掘强规则。在少量数据中进行规则挖掘我们可以采用采用简单的编程方法,而在大量数据中挖掘关联规则需要使用专门的数据挖掘软件。关联规则挖掘可以使我们得到一些原来我们所不知道的知识。 应用的例子: * 日本超市对交易数据库进行关联规则挖掘,发现规则:尿片→啤酒,重新安排啤酒柜台位置,销量上升75%。 * 英国超市的例子:大额消费者与某种乳酪。 那么,证券市场上、期货市场上、或者上市公司中存在存在哪些关联规则,这些关联规则究竟说明了什么? 关联规则挖掘通常比较适用与记录中的指标取离散值的情况,如果原始数据
数据挖掘研究现状及发展趋势
数据挖掘研究现状及发展趋势摘要:从数据挖掘的定义出发,介绍了数据挖掘的神经网络法、决策树法、遗传算法、粗糙集法、模糊集法和关联规则法等概念及其各自的优缺点;详细总结了国内外数据挖掘的研究现状及研究热点,指出了数据挖掘的发展趋势。 关键词:数据挖掘;挖掘算法;神经网络;决策树;粗糙集;模糊集;研究现状;发展趋势 Abstract:From the definition of data mining,the paper introduced concepts and advantages and disadvantages of neural network algorithm,decision tree algorithm,genetic algorithm,rough set method,fuzzy set method and association rule method of data mining,summarized domestic and international research situation and focus of data mining in details,and pointed out the development trend of data mining. Key words:data mining,algorithm of data mining,neural network,decision tree,rough set,fuzzy set,research situation,development tendency 1引言 随着信息技术的迅猛发展,许多行业如商业、企业、科研机构和政府部门等都积累了海量的、不同形式存储的数据资料[1]。这些海量数据中往往隐含着各种各样有用的信息,仅仅依靠数据库的查询检索机制和统计学方法很难获得这些信息,迫切需要能自动地、智能地将待处理的数据转化为有价值的信息,从而达到为决策服务的目的。在这种情况下,一个新的技术———数据挖掘(Data Mining,DM)技术应运而生[2]。 数据挖掘是一个多学科领域,它融合了数据库技术、人工智能、机器学习、统计学、知识工程、信息检索等最新技术的研究成果,其应用非常广泛。只要是有分析价值的数据库,都可以利用数据挖掘工具来挖掘有用的信息。数据挖掘典型的应用领域包括市场、工业生产、金融、医学、科学研究、工程诊断等。本文主要介绍数据挖掘的主要算法及其各自的优缺点,并对国内外的研究现状及研究热点进行了详细的总结,最后指出其发展趋势及问题所在。 江西理工大学
数据挖掘-题库带答案
数据挖掘-题库带答案 1、最早提出“大数据”时代到来的是全球知名咨询公司麦肯锡() 答案:正确 2、决策将日益基于数据和分析而作出,而并非基于经验和直觉() 答案:错误 解析:决策将日益基于数据和分析而作出,而并非基于经验和直觉 3、2011年被许多国外媒体和专家称为“大数据元年”() 答案:错误 解析:2013年被许多国外媒体和专家称为“大数据元年” 4、我国网民数量居世界之首,每天产生的数据量也位于世界前列() 答案:正确 5、商务智能的联机分析处理工具依赖于数据库和数据挖掘。() 答案:错误 解析:商务智能的联机分析处理工具依赖于数据仓库和多维数据挖掘。 6、数据整合、处理、校验在目前已经统称为 EL() 答案:错误 解析:数据整合、处理、校验在目前已经统称为 ETL 7、大数据时代的主要特征() A、数据量大 B、类型繁多 C、价值密度低 D、速度快时效高 答案: ABCD 8、下列哪项不是大数据时代的热门技术() A、数据整合 B、数据预处理 C、数据可视化 D、 SQL
答案: D 9、()是一种统计或数据挖掘解决方案,包含可在结构化和非结构化数据中使用以确定未来结果的算法和技术。 A、预测 B、分析 C、预测分析 D、分析预测 答案: C 10、大数据发展的前提? 答案: 解析:硬件成本的降低,网络带宽的提升,云计算的兴起,网络技术的发展,智能终端的普及,电子商务、社交网络、电子地图等的全面应用,物联网的兴起 11、调研、分析大数据发展的现状与应用领域。? 答案: 解析:略 12、大数据时代的主要特征? 答案: 解析:数据量大(Volume) 第一个特征是数据量大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。 类型繁多(Variety) 第二个特征是数据类型繁多。包括网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。 价值密度低(Value) 第三个特征是数据价值密度相对较低。如随着物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何通过强大的机器算法更迅速地完成数据的价值“提纯”,是大数据时代亟待解决的难题。 速度快、时效高(Velocity) 第四个特征是处理速度快,时效性要求高。这是大数据区分于传统数据挖掘最显著的特征。 13、列举大数据时代的主要技术? 答案: 解析:预测分析: 预测分析是一种统计或数据挖掘解决方案,包含可在结构化和非结构化数据中使用以确定未来结果的算法和技术。可为预测、优化、预报和模拟等许多其他用途而部署。随着现在硬件和软件解决方案的成熟,许多公司利用大数据技术来收集海量数据、训练模型、优化模型,并发布预测模型来提高业务
数据挖掘试题与答案
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2. 时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
数据挖掘复习大纲答案新新
数据挖掘复习提纲 分值分布 一、选择题(单选10道20分多选5道20分) 二、填空题(10道20分) 三、名词解释(5道20分) 四、解答题(4道20分) 五、应用题(Apriori算法20分) 1.什么是数据挖掘? 1答:简单地说,数据挖掘是从大量数据中提取或挖掘知识。 具体地说,数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。 2. 什么是数据清理? 2答:填写缺失的值,平滑噪声数据,识别、删除离群点,解决不一致性 3. 什么是数据仓库? 3答:是一个面向主题的、集成的、随时间而变化的、不容易丢失的数据集合,支持管理部门决策的过程。(最显著特征:数据不易丢失2分选择题) 4. 什么是数据集成? 4.数据集成:集成多个数据库、数据立方体或文件 5. 什么是数据变换? 5答:将数据转换或统一成适合于挖掘的形式。 6. 什么是数据归约? 6答:得到数据集的压缩表示,它小得多,但可以得到相同或相近的结果 7. 什么是数据集市? 7答:数据集市包含企业范围数据的一个子集,对于特定的用户群是有用的。其范围限于选定的主题。 (是完整的数据仓库的一个逻辑子集,而数据仓库正是由所有的数据集市有机组合而成的) 8.在数据挖掘过程中,耗时最长的步骤是什么? 8.答:数据清理 9.数据挖掘系统可以根据什么标准进行分类? 9答:根据挖掘的数据库类型分类、根据挖掘的知识类型分类、根据挖掘所用的技术分类、根据应用分类 10. 多维数据模型上的OLAP 操作包括哪些? 10.答:上卷、下钻、切片和切块、转轴 / 旋转、其他OLAP操作 11. OLAP 服务器类型有哪几种? 11.答:关系 OLAP 服务器(ROLAP)、多维 OLAP 服务器(MOLAP)、混合 OLAP 服务器 (HOLAP)、特殊的 SQL 服务器 12. 数据预处理技术包括哪些?(选择) 12.答:聚集、抽样、维规约、特征子集选择、特征创建、离散化和二元化、变量变换。 13. 形成“脏数据”的原因有哪些? 13. 答:滥用缩写词、数据输入错误、数据中的内嵌控制信息、不同的的惯用语、重复记录、丢失值、拼写变化、不同的计量单位、过时的编码 14. 与数据挖掘类似的术语有哪些? 14答:数据库中挖掘知识、知识提取、数据/模式分析、数据考古和数据捕捞。
数据挖掘作业
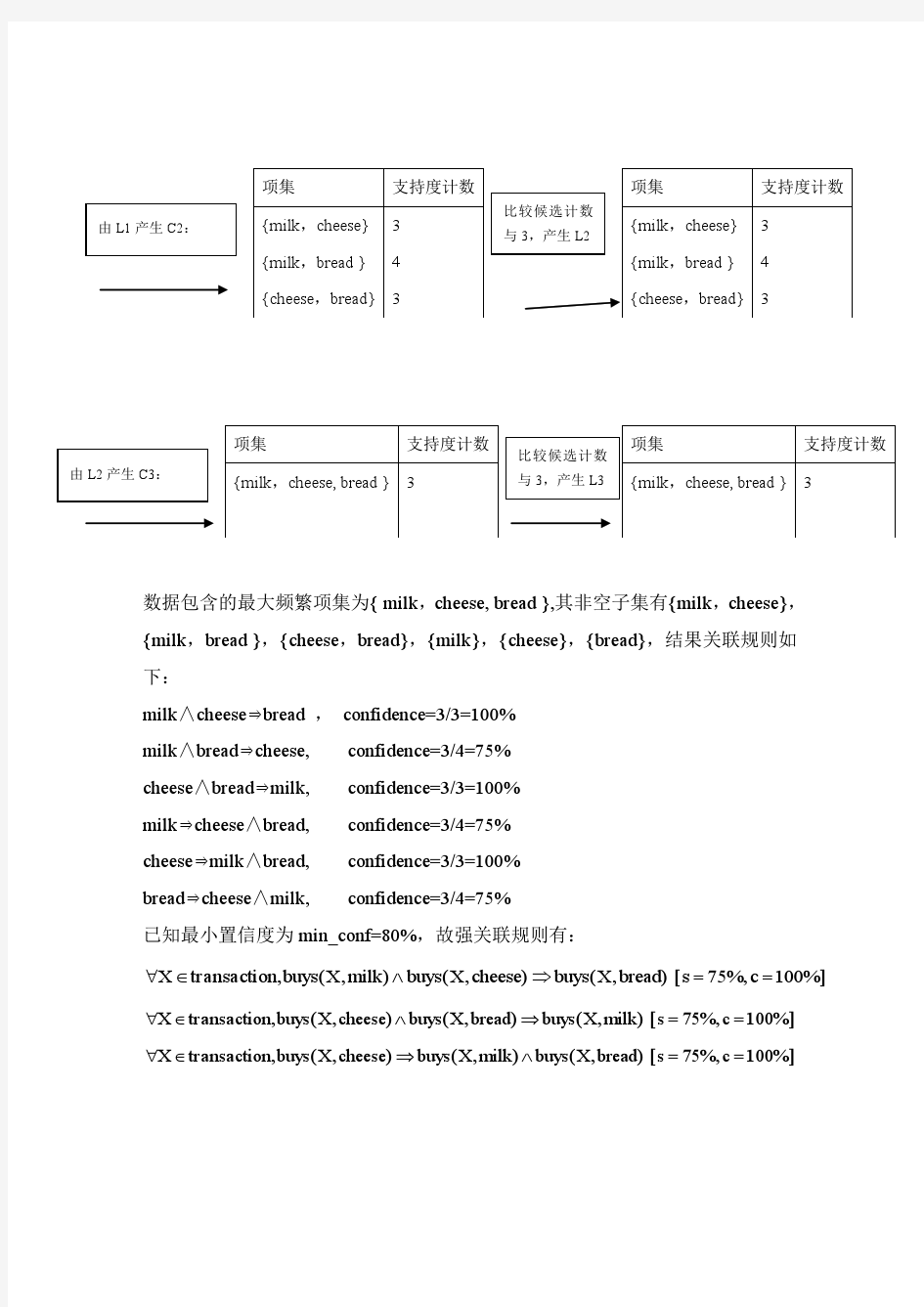
第5章关联分析 5.1 列举关联规则在不同领域中应用的实例。 5.2 给出如下几种类型的关联规则的例子,并说明它们是否是有价值的。 (a)高支持度和高置信度的规则; (b)高支持度和低置信度的规则; (c)低支持度和低置信度的规则; (d)低支持度和高置信度的规则。 5.3 数据集如表5-14所示: (a) 把每一个事务作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。 (b) 利用(a)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。置信度是一个对称的度量吗? (c) 把每一个用户购买的所有商品作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。 (d) 利用(b)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。置信度是一个对称的度量吗? 5.4 关联规则是否满足传递性和对称性的性质?举例说明。 5.5 Apriori 算法使用先验性质剪枝,试讨论如下类似的性质 (a) 证明频繁项集的所有非空子集也是频繁的 (b) 证明项集s 的任何非空子集s ’的支持度不小于s 的支持度 (c) 给定频繁项集l 和它的子集s ,证明规则“s’→(l – s’)”的置信度不高于s →(l – s)的置信度,其中s’是s 的子集 (d) Apriori 算法的一个变形是采用划分方法将数据集D 中的事务分为n 个不相交的子数据集。证明D 中的任何一个频繁项集至少在D 的某一个子数据集中是频繁的。 5.6 考虑如下的频繁3-项集:{1, 2, 3},{1, 2, 4},{1, 2, 5}, {1, 3, 4},{1, 3, 5},{2, 3, 4},{2, 3, 5},{3, 4, 5}。 (a)根据Apriori 算法的候选项集生成方法,写出利用频繁3-项集生成的所有候选4-项集。 (b)写出经过剪枝后的所有候选4-项集 5.7 一个数据库有5个事务,如表5-15所示。设min_sup=60%,min_conf = 80%。
中科院数据挖掘作业2
HW2 Due Date: Nov. 23 Submission requirements: Please submit your solutions to our class website. Only hand in what is required below. Part I: written assignment 1. a) Compute the Information Gain for Gender, Car Type and Shirt Size. b) Construct a decision tree with Information Gain. 2. (a) Design a multilayer feed-forward neural network (one hidden layer) for the data set in Q1. Label the nodes in the input and output layers. (b) Using the neural network obtained above, show the weight values after one itera tion of the back propagation algorithm, given the training instance “(M,
Family, Small)". Indicate your initial weight values and biases and the learning rate used. 3. a) Suppose the fraction of undergraduate students who smoke is 15% and the fraction of graduate students who smoke is 23%. If one-?fth of the college students are graduate students and the rest are undergraduates, what is the probability that a student who smokes is a graduate student? b) Given the information in part (a), is a randomly chosen college student more likely to be a graduate or undergraduate student? c) Suppose 30% of the graduate students live in a dorm but only 10% of the undergraduate students live in a dorm. If a student smokes and lives in the dorm, is he or she more likely to be a graduate or undergraduate student? You can assume independence between students who live in a dorm and those who smoke. 4. Suppose that the data mining task is to cluster the following ten points (with(x, y, z) representing location) into three clusters: A1(4,2,5), A2(10,5,2), A3(5,8,7), B1(1,1,1), B2(2,3,2), B3(3,6,9), C1(11,9,2),C2(1,4,6), C3(9,1,7), C4(5,6,7) The distance function is Euclidean distance. Suppose initially we assign A1,B1,C1 as the center of each cluster, respectively. Use the K-Means algorithm to show only (a) The three cluster center after the first round execution (b) The final three clusters Part II: Lab Question 1 Assume this supermarket would like to promote milk. Use the data in “transactions” as training data to build a decision tree (C5.0 algorithm) model to predict whether the customer would buy milk or not. 1. Build a decision tree using data set “transaction s” that predicts milk as a function of the other fields. Set the “type” of each field to “Flag”, set the “direction” of “milk” as “out”, set the “type” of COD as “Typeless”, select “Expert” and set the “pruning severity” to 65, and set the “minimum records per child branch” to be 95. Hand-in: A figure showing your tree. 2. Use the model (the full tree generated by Clementine in step 1 above) to make a predic tion for each of the 20 customers in the “rollout” data to determine whether the customer would buy milk. Hand-in: your prediction for each of the 20 customers. 3. Hand-in: rules for positive (yes) prediction of milk purchase identified from the decision tree (up to the fifth level. The root is considered as level 1). Compare with the rules generated by Apriori in Homework 1, and submit your brief comments on the rules (e.g., pruning effect)
(完整word版)数据挖掘题目及答案
一、何为数据仓库?其主要特点是什么?数据仓库与KDD的联系是什么? 数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。 特点: 1、面向主题 操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的。 2、集成的 数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。 3、相对稳定的 数据仓库的数据主要供企业决策分析之用,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。 4、反映历史变化 数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。 所谓基于数据库的知识发现(KDD)是指从大量数据中提取有效的、新颖的、潜在有用的、最终可被理解的模式的非平凡过程。数据仓库为KDD提供了数据环境,KDD从数据仓库中提取有效的,可用的信息 二、 数据库有4笔交易。设minsup=60%,minconf=80%。 TID DATE ITEMS_BOUGHT T100 3/5/2009 {A, C, S, L} T200 3/5/2009 {D, A, C, E, B} T300 4/5/2010 {A, B, C} T400 4/5/2010 {C, A, B, E} 使用Apriori算法找出频繁项集,列出所有关联规则。 解:已知最小支持度为60%,最小置信度为80% 1)第一步,对事务数据库进行一次扫描,计算出D中所包含的每个项目出现的次数,生成候选1-项集的集合C1。
数据挖掘复习章节知识点整理
数据挖掘:是从大量数据中发现有趣(非平凡的、隐含的、先前未知、潜在有用)模式,这些数据可以存放在数据库,数据仓库或其他信息存储中。 挖掘流程: 1.学习应用域 2.目标数据创建集 3.数据清洗和预处理 4.数据规约和转换 5.选择数据挖掘函数(总结、分类、回归、关联、分类) 6.选择挖掘算法 7.找寻兴趣度模式 8.模式评估和知识展示 9.使用挖掘的知识 概念/类描述:一种数据泛化形式,用汇总的、简洁的和精确的方法描述各个类和概念,通过(1)数据特征化:目标类数据的一般特性或特征的汇总; (2)数据区分:将目标类数据的一般特性与一个或多个可比较类进行比较; (3)数据特征化和比较来得到。 关联分析:发现关联规则,这些规则展示属性-值频繁地在给定数据集中一起出现的条件,通常要满足最小支持度阈值和最小置信度阈值。 分类:找出能够描述和区分数据类或概念的模型,以便能够使用模型预测类标号未知的对象类,导出的模型是基于训练集的分析。导出模型的算法:决策树、神经网络、贝叶斯、(遗传、粗糙集、模糊集)。 预测:建立连续值函数模型,预测空缺的或不知道的数值数据集。 孤立点:与数据的一般行为或模型不一致的数据对象。 聚类:分析数据对象,而不考虑已知的类标记。训练数据中不提供类标记,对象根据最大化类内的相似性和最小化类间的原则进行聚类或分组,从而产生类标号。 第二章数据仓库 数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理部门的决策过程。从一个或多个数据源收集信息,存放在一个一致的模式下,并且通常驻留在单个站点。数据仓库通过数据清理、变换、继承、装入和定期刷新过程来构造。面向主题:排除无用数据,提供特定主题的简明视图。集成的:多个异构数据源。时变的:从历史角度提供信息,隐含时间信息。非易失的:和操作数据的分离,只提供初始装入和访问。 联机事务处理OLTP:主要任务是执行联机事务和查询处理。 联系分析处理OLAP:数据仓库系统在数据分析和决策方面为用户或‘知识工人’提供服务。这种系统可以用不同的格式和组织提供数据。OLAP是一种分析技术,具有汇总、合并和聚集功能,以及从不同的角度观察信息的能力。
数据挖掘离线作业
浙江大学远程教育学院 《数据挖掘》课程作业 姓名:学号: 年级:学习中心:————————————————————————————— 第一章引言 一、填空题 (1)数据库中的知识挖掘(KDD)包括以下七个步骤:数据清理、数据集成、数据选择、数据交换、数据挖掘、模式评估和知识表示 (2)数据挖掘的性能问题主要包括:算法的效率、可扩展性和并行处理 (3)当前的数据挖掘研究中,最主要的三个研究方向是:统计学、数据库技术和机器学习 (4)孤立点是指:一些与数据的一般行为或模型不一致的孤立数据 二、简答题 (1)什么是数据挖掘? 答:数据挖掘指的是从大量的数据中挖掘出那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识。 (2)一个典型的数据挖掘系统应该包括哪些组成部分? 答:一个典型的数据挖掘系统应该包括以下部分:1、数据库、数据仓库或其他信息库,2、数据库或数据仓库服务器,3、知识库,4、数据挖掘引擎,5、模式评估魔磕,6图形用户界面。 (3)Web挖掘包括哪些步骤? 答:数据清理:(这个可能要占用过程60%的工作量)、数据集成、将数据存入数据仓库、建立数据立方体、选择用来进行数据挖掘的数据、数据挖掘(选择适当的算法来找到感兴趣的模式)、展现挖掘结果、将模式或者知识应用或者存入知识库。 (4)请列举数据挖掘应用常见的数据源。 (或者说,我们都在什么样的数据上进行数据挖掘) 答:常见的数据源包括关系数据库、数据仓库、事务数据库和高级数据库系统和信息库。其中高级数据库系统和信息库包括:空间数据库、时间数据库和时间序列数据库、流数据、多媒体数据库、面向对象数据库和对象——关系数据库、异种数据库和遗产数据库、文本数据库和万维网等。
大数据背景下数据挖掘技术的应用
《计算机科学与技术前沿》 课程论文 大数据背景下数据挖掘技术的应用 2016年1月7日 题目 学院 学号 姓名 指导老师 日期
大数据背景下数据挖掘技术的应用 摘要 当今社会是一个信息化社会的时代,同时又是一个大数据时代。随着互联网、物联网、云计算和人工智能等信息技术和计算机产业的不断发展和进步,使得数据的处理成为一个亟待解决的问题。因此在大数据的背景下,如何高效地从大量包含有用数据的库获得有用信息已成为企业和科研工作重点关注的点,而这一工作涉及的关键技术就是数据挖掘技术。总得说,数据处理的需要既给数据挖掘技术带来了机遇,于此同时带来了一系列的挑战。 本文分别从企业、图书管理和情报学领域三个方面阐述数据挖掘技术的应用,同时对它的发展现状、存在的问题和未来的发展趋势进行了一些阐述,从而加深了对数据挖掘技术的理解,以便更好地了解数据挖掘在各个领域的应用,最后对数据挖掘技术的应用进行一个整体的总结。 【关键字】:大数据;数据挖掘;数据挖掘的应用
Application of data mining technology in the context of data Abstract Today is the age of information society,but it is also an age of big data.With development and progress of information technology and the computer industry which include the Internet, the Internet of things, cloud computing and artificial intelligence, data processing has become an urgent problem.Therefore,in the context of big data,how to get useful information from a large library of useful data have become focuses of enterprises and scientific and research work.The work involved is the key technology of data mining.In General spedking, data processing needs for data mining technology, and at the same time poses a series of challenges. The paper aims to account the development present situation,existing problems,and developmenttrend in the future based on companies,library management and the field of information science development,so as to enhance understanding of the data mining technology ,to better understand data mining applications in various fields,and to draw an overall summary of the application of data mining technology. 【Key words】:Large amounts of data;Data mining;Application of data mining
数据挖掘考试题库【最新】
一、填空题 1.Web挖掘可分为、和3大类。 2.数据仓库需要统一数据源,包括统一、统一、统一和统一数据特征 4个方面。 3.数据分割通常按时间、、、以及组合方法进行。 4.噪声数据处理的方法主要有、和。 5.数值归约的常用方法有、、、和对数模型等。 6.评价关联规则的2个主要指标是和。 7.多维数据集通常采用或雪花型架构,以表为中心,连接多个表。 8.决策树是用作为结点,用作为分支的树结构。 9.关联可分为简单关联、和。 10.B P神经网络的作用函数通常为区间的。 11.数据挖掘的过程主要包括确定业务对象、、、及知识同化等几个步 骤。 12.数据挖掘技术主要涉及、和3个技术领域。 13.数据挖掘的主要功能包括、、、、趋势分析、孤立点分析和偏 差分析7个方面。 14.人工神经网络具有和等特点,其结构模型包括、和自组织网络 3种。 15.数据仓库数据的4个基本特征是、、非易失、随时间变化。 16.数据仓库的数据通常划分为、、和等几个级别。 17.数据预处理的主要内容(方法)包括、、和数据归约等。 18.平滑分箱数据的方法主要有、和。 19.数据挖掘发现知识的类型主要有广义知识、、、和偏差型知识五种。 20.O LAP的数据组织方式主要有和两种。 21.常见的OLAP多维数据分析包括、、和旋转等操作。 22.传统的决策支持系统是以和驱动,而新决策支持系统则是以、建 立在和技术之上。 23.O LAP的数据组织方式主要有和2种。 24.S QL Server2000的OLAP组件叫,OLAP操作窗口叫。 25.B P神经网络由、以及一或多个结点组成。 26.遗传算法包括、、3个基本算子。 27.聚类分析的数据通常可分为区间标度变量、、、、序数型以及混合 类型等。 28.聚类分析中最常用的距离计算公式有、、等。 29.基于划分的聚类算法有和。