谱聚类报告
聚类分析和判别分析实验报告
聚类分析实验报告一、实验数据2013年,在国内外形势错综复杂的情况下,我国经济实现了平稳较快发展。
全年国内生产总值568845亿元,比上年增长7.7%。
其中第三产业增加值262204亿元,增长8.3%,其在国内生产总值中的占比达到了46.1%,首次超过第二产业。
经济的快速发展也带来了就业的持续增加,年末全国就业人员76977万人,其中城镇就业人员38240万人,全年城镇新增就业1310万人。
随着我国城镇化进程的不断加快,加之农业用地量的不断衰减,工业不断的转型升级,使得劳动力就业压力的缓解需要更多的依靠服务业的发展。
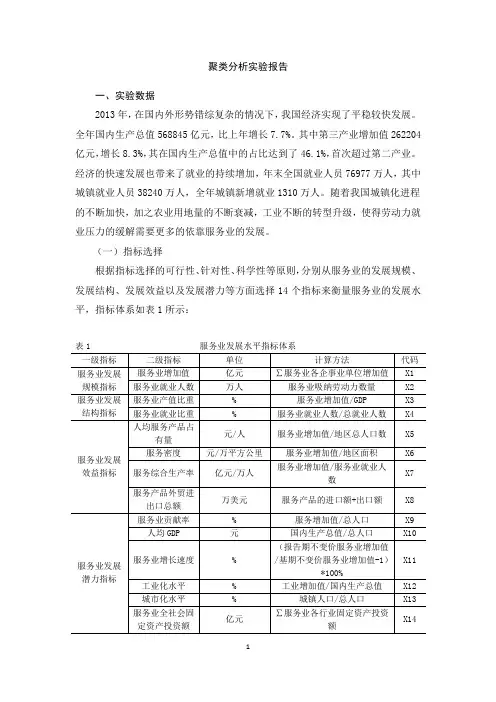
(一)指标选择根据指标选择的可行性、针对性、科学性等原则,分别从服务业的发展规模、发展结构、发展效益以及发展潜力等方面选择14个指标来衡量服务业的发展水平,指标体系如表1所示:表1 服务业发展水平指标体系(二)指标数据本次实验采用的数据是我国31个省(市、自治区)2012年的数据,原数据均来自《2013中国统计年鉴》以及2013年各省(市、自治区)统计年鉴,不能直接获得的指标数据是通过对相关原始数据的换算求得。
原始数据如表2所示:表2(续)二、实验步骤本次实验是在SPSS中分别利用系统聚类法和K均值法进行聚类分析,具体步骤如下:(一)系统聚类法⒈在SPSS窗口中选择Analyze—Classify—Hierachical Cluster,调出系统聚类分析主界面,将变量X1-X14移入Variables框中。
在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
⒉点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
这里选择系统默认值,点击Continue按钮,返回主界面。
⒊点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。
机器学习层谱聚类综述

机器学习层谱聚类综述王少将;刘佳;郑锋;潘祎诚【期刊名称】《计算机科学》【年(卷),期】2023(50)1【摘要】聚类分析在机器学习、数据挖掘、生物DNA信息等方面都起着极为关键的作用。
聚类算法从方法学上可分为扁平聚类和层谱聚类。
扁平聚类通常将数据集分为K个并行社区,社区之间没有交集,但现实世界的社区之间多具有不同层次之间的包含关系,因而层谱聚类算法能对数据进行更精细的分析,提供更好的可解释性。
而相比扁平聚类,层谱聚类研究进展缓慢。
针对层谱聚类面临的问题,从对代价函数的选择、聚类结果衡量指标、聚类算法性能等方面入手,调研了大量的相关文献。
其中聚类结果衡量指标主要有模块度、Jaccard指数、标准化互信息、树状图纯度等。
扁平聚类算法中比较经典的算法有K-means算法、标签传播算法、DBSCAN 算法、谱聚类算法等。
层谱聚类算法可以进一步划分为分裂聚类算法和凝聚聚类算法,分裂层谱聚类算法有二分K-means算法和递归稀疏割算法,凝聚层谱聚类算法有经典的Louvain算法、BIRCH算法和近年来提出的HLP算法、PERCH算法及GRINCH算法。
最后,进一步分析了这些算法的优缺点,并总结全文。
【总页数】9页(P9-17)【作者】王少将;刘佳;郑锋;潘祎诚【作者单位】华北计算技术研究所;空军工程大学基础部;北京航空航天大学计算机学院【正文语种】中文【中图分类】TP181【相关文献】1.机器学习中谱聚类方法的研究2.谱聚类算法及其应用综述3.基于信息熵-模糊谱聚类的非均质碎屑岩储层孔隙结构分类4.谱聚类算法及其应用综述5.谱聚类算法研究综述因版权原因,仅展示原文概要,查看原文内容请购买。
谱聚类方法

谱聚类方法一、谱聚类的基本原理谱聚类(Spectral Clustering)是一种基于图论的聚类方法,通过研究样本数据的图形结构来进行聚类。
谱聚类方法的基本原理是将高维数据转换为低维数据,然后在低维空间中进行聚类。
它利用样本之间的相似性或距离信息,构建一个图模型(通常是相似度图或距离图),然后对图模型进行谱分解,得到一系列特征向量,最后在特征向量空间中进行聚类。
谱聚类的核心步骤是构建图模型和进行谱分解。
在构建图模型时,通常采用相似度矩阵或距离矩阵来表示样本之间的联系。
在谱分解时,通过对图模型的拉普拉斯矩阵进行特征分解,得到一系列特征向量,这些特征向量表示了样本数据的低维空间结构。
通过对特征向量空间进行聚类,可以将高维数据分为若干个类别。
二、谱聚类的优缺点1.优点(1)适用于高维数据:谱聚类方法能够有效地处理高维数据,因为它的核心步骤是将高维数据转换为低维数据,然后在低维空间中进行聚类。
这有助于克服高维数据带来的挑战。
(2)对噪声和异常值具有较强的鲁棒性:谱聚类方法在构建图模型时,会考虑到样本之间的相似性和距离信息,从而在一定程度上抑制了噪声和异常值的影响。
(3)适用于任意形状的聚类:谱聚类方法可以适用于任意形状的聚类,因为它的聚类结果是基于特征向量空间的,而特征向量空间可以捕捉到样本数据的全局结构。
2.缺点(1)计算复杂度高:谱聚类的计算复杂度相对较高。
构建图模型和进行谱分解都需要大量的计算。
在大规模数据集上,谱聚类的计算效率可能会成为问题。
(2)对相似度矩阵或距离矩阵的敏感性:谱聚类的结果会受到相似度矩阵或距离矩阵的影响。
如果相似度矩阵或距离矩阵不合理或不准确,可能会导致聚类结果不理想。
(3)对参数的敏感性:谱聚类的结果会受到参数的影响,如相似度度量方式、距离度量方式、图模型的构建方式等。
如果参数选择不当,可能会导致聚类效果不佳。
三、谱聚类的应用场景1.图像分割:谱聚类方法可以应用于图像分割,将图像中的像素点分为若干个类别,从而实现对图像的分割。
聚类分析结果总结报告

聚类分析结果总结报告聚类分析是一种常用的数据分析方法,通过找出数据样本之间的相似性,将它们分为簇,从而对数据进行分类。
本次聚类分析旨在对一批消费者进行分类,以便更好地理解他们的行为模式、需求和喜好。
以下是对聚类分析结果的总结报告。
通过对消费者的行为数据进行聚类分析,我们将其分为三个簇:簇1、簇2和簇3。
每个簇代表着一组相似的消费者群体,下面对每个簇进行具体分析。
簇1:这是一个高消费群体,他们在各个维度上的消费都较高。
他们对品牌认知较高,更注重购买名牌产品;他们也更倾向于在线购物,且购买的商品种类较广泛;此外,他们更愿意花费时间在购物上,喜欢认真研究和比较产品特点和价格。
簇1群体对价格并不敏感,更看重商品质量和品牌的声誉。
簇2:这是一个价值敏感的消费群体,他们更注重价格相对便宜的商品。
他们对品牌知名度并不是很敏感,更关注购物便利性和商品的实用性。
他们喜欢到实体店购物,可以触摸和试穿商品,这样可以更好地评估商品的实际价值。
簇2群体对线上购物并不是很感兴趣,更喜欢传统的购物方式。
簇3:这是一个中等消费群体,他们在各个维度上的消费行为都处于中等水平。
他们对品牌和价格都没有太强的偏好,更关注商品的功能和性能。
他们对购物的时间和成本都有一定的限制,更倾向于选择便利和高性价比的商品。
通过以上分析,我们得出以下几个结论:1. 个体之间在消费行为上的差异很大,每个簇代表的消费群体有明显的特征和偏好。
2. 消费者对品牌、价格、购物方式等因素的重视程度存在差异,这可以为市场营销提供指导。
3. 不同簇的消费群体在市场定位和产品推广上需要采取不同的策略,吸引不同簇的目标消费群体。
4. 对于高消费群体,可以重点推广高端品牌和品质产品;对于价值敏感的群体,可以提供更具性价比的产品和便利的购物体验;对于中等消费群体,可以提供功能强大且价格适中的商品。
在实际应用中,聚类分析可以辅助企业进行市场细分和目标客户定位,可以帮助提高市场竞争力和个性化营销的效果。
聚类分析报告

基于层次聚类分析的我国居民收入状况地区比较分析摘要:在国家统计局关于居民收入的统计指标基础上,采用层次聚类分析对我国各地区居民收入的状况进行了比较分析,并得出各主要聚类群。
在此基础上认为目前我国居民还是以工薪收入为主,各地区其他收入方面均有不同情况。
关键词:层次聚类分析居民收入地区比较一、引言目前,深化收入分配制度改革,增加城乡居民收入是我国综合实力发展所要解决的一个非常重要的问题。
党的十七大报告中明确指出:“逐步提高居民收入在国民收入分配中的比重,提高劳动报酬在初次分配中的比重。
着力提高低收入者收入,逐步提高扶贫标准和最低工资标准,建立企业职工工资正常增长机制和支付保障机制。
创造条件让更多群众拥有财产性收入。
保护合法收入,调节过高收入,取缔非法收入。
扩大转移支付,强化税收调节,打破经营垄断,创造机会公平,整顿分配秩序,逐步扭转收入分配差距扩大趋势。
”为此,我们非常有必要按照居民收入的不同种类将收入状况趋同的地区进行分类,以找到解决当前面临的增加居民收入的突破口。
二、模型选择层次聚类分析是一种多元数理统计方法。
它并没有事先设定样本分类的标准,而是通过对样本和变量数据的不同特征指标值进行差异程度计算,根据变量或样本间不同的差异程度大小重新结合分类,产生一个更有效的分类。
其优点在于可以对分类变量进行聚类,提供的距离测量方法和结果表示方法也非常丰富。
它的实现过程如下:1.由于本文所选用数据存在极大的量纲,所以必须进行无量纲化处理。
2.将各组数据作为独立的一类(设为n类),按照所定义的距离计算各数据点之间的距离,形成一个距离阵。
3.将距离最近的两组数据并为一类,从而形成n-1个类别,计算新产生的类别与其他各个类别之间的距离或者相似度,形成新的距离阵。
这种方法的思想来自于方差分析,使用该方法的目的是使得各个类别间的样本量尽可能接近。
4.按照与第二步相同的原则,再将距离最接近的两个类别合并,一直重复该步骤直到所有数据被合并为一个类别为止。
聚类分析实验报告例题

一、实验目的1. 理解聚类分析的基本原理和方法。
2. 掌握K-means、层次聚类等常用聚类算法。
3. 学习如何使用Python进行聚类分析,并理解算法的运行机制。
4. 分析实验结果,并评估聚类效果。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 库:NumPy、Matplotlib、Scikit-learn三、实验数据本次实验使用的数据集为Iris数据集,包含150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),属于3个不同的类别。
四、实验步骤1. 导入Iris数据集,并进行数据预处理。
2. 使用K-means算法进行聚类分析,选择合适的K值。
3. 使用层次聚类算法进行聚类分析,观察聚类结果。
4. 分析两种算法的聚类效果,并进行比较。
5. 使用Matplotlib绘制聚类结果的可视化图形。
五、实验过程1. 数据预处理```pythonfrom sklearn import datasetsimport numpy as np# 加载Iris数据集iris = datasets.load_iris()X = iris.datay = iris.target# 数据标准化X = (X - np.mean(X, axis=0)) / np.std(X, axis=0) ```2. K-means聚类分析```pythonfrom sklearn.cluster import KMeans# 选择K值k_values = range(2, 10)inertia_values = []for k in k_values:kmeans = KMeans(n_clusters=k, random_state=42) kmeans.fit(X)inertia_values.append(kmeans.inertia_)# 绘制肘部图import matplotlib.pyplot as pltplt.plot(k_values, inertia_values, marker='o') plt.xlabel('Number of clusters')plt.ylabel('Inertia')plt.title('Elbow Method')plt.show()```3. 层次聚类分析```pythonfrom sklearn.cluster import AgglomerativeClustering# 选择层次聚类方法agglo = AgglomerativeClustering(n_clusters=3)y_agglo = agglo.fit_predict(X)```4. 聚类效果分析通过观察肘部图,可以发现当K=3时,K-means算法的聚类效果最好。
聚类分析实验报告
聚类分析实验报告
《聚类分析实验报告》
在数据挖掘和机器学习领域,聚类分析是一种常用的技术,用于将数据集中的对象分成具有相似特征的组。
通过聚类分析,我们可以发现数据集中隐藏的模式和结构,从而更好地理解数据并做出相应的决策。
在本次实验中,我们使用了一种名为K均值聚类的方法,对一个包含多个特征的数据集进行了聚类分析。
我们首先对数据进行了预处理,包括缺失值处理、标准化和特征选择等步骤,以确保数据的质量和可靠性。
接着,我们选择了合适的K值(聚类的数量),并利用K均值算法对数据进行了聚类。
在实验过程中,我们发现K均值聚类方法能够有效地将数据集中的对象分成具有相似特征的组,从而形成了清晰的聚类结构。
通过对聚类结果的分析,我们发现不同的聚类中心代表了不同的数据模式,这有助于我们更好地理解数据集中的内在规律和特点。
此外,我们还对聚类结果进行了评估和验证,包括使用轮廓系数和肘部法则等方法来评价聚类的质量和效果。
通过这些评估方法,我们得出了实验结果的可靠性和有效性,证明了K均值聚类在本次实验中的良好表现。
总的来说,本次实验通过聚类分析方法对数据集进行了深入的挖掘和分析,得到了有意义的聚类结果,并验证了聚类的有效性和可靠性。
通过这一实验,我们对聚类分析方法有了更深入的理解,也为今后在实际应用中更好地利用聚类分析提供了有力支持。
班级学生成绩聚类分析报告
班级学生成绩聚类分析报告1. 引言学生成绩是评价学生学习成果的一个重要指标。
通过对学生成绩进行聚类分析可以帮助我们理解学生成绩之间的关系,发现不同学生群体之间的特点和差异,为教育教学提供参考。
本报告旨在对某班级学生成绩进行聚类分析,并探讨聚类结果的意义。
2. 数据准备本次分析使用的数据是某班级学生的成绩数据,包括数学、语文、英语三门课程的成绩。
共有50个学生的成绩数据,每位学生的成绩用一个向量表示,该向量的维度为3。
下表给出了前5位学生的成绩数据示例:学生编号数学成绩语文成绩英语成绩S1 85 90 75S2 72 80 82S3 96 91 93S4 68 75 78S5 92 88 853. 聚类分析方法聚类分析是一种将样本根据其相似性进行分组的方法。
在本次分析中,我们使用K-means算法对学生成绩进行聚类。
K-means算法通过将样本划分到K个聚类中心,使得各个样本到所属聚类中心的距离最小化,来实现聚类的目标。
4. 聚类分析过程在进行聚类分析之前,需要先确定K值,即要将样本分成几个聚类。
我们通过手肘法确定K值。
手肘法通过绘制不同K值下的聚类误差平方和(SSE)与K值的关系图,找到误差平方和变动趋势明显变缓的拐点作为合适的K值。
本次分析中,我们尝试了K从1到10的值,计算了对应的SSE,并绘制了SSE与K值的关系图。
观察到当K=3时,SSE的变化趋势明显变缓,因此我们选择K=3作为合适的聚类数量。
接下来,我们使用K-means算法将学生成绩进行聚类。
在聚类过程中,我们随机选择了3个初始聚类中心,并迭代计算每个样本与各个聚类中心的距离,将其划分到距离最近的聚类中心。
5. 聚类结果分析经过聚类分析,我们将学生成绩分成了3个聚类,分别为聚类1、聚类2和聚类3。
下图给出了聚类结果的可视化效果:从上图可以看出,不同聚类之间存在明显的差异。
我们对每个聚类的特点进行分析如下:- 聚类1: 该聚类中的学生在数学和语文成绩上表现较为突出,英语成绩相对较低。
谱聚类算法讲解ppt课件
sij xi KNN ( x j ) and x j KNN ( xi )
10
Spectral Clustering 谱聚类
谱聚类基础一:图-邻接矩阵
(3)全连接法:
通过核函数定义边权重,常用的有多项式核函数,
高斯核函数和Sigmoid核函数。使用高斯核函数构建邻接
1 1
Rcut(G1 , G2 ) Cut (G1 , G2 )
n1 n2
n1、n 2划分到子图1和子图2的顶点个数
Rcut (G1 , G2 )
1 1
w
ij
n2
iG1 , jG2 n1
(n1 n2 ) 2
wij
量的相似矩阵S
邻接矩阵W。
6
Spectral Clustering 谱聚类
谱聚类基础一:图-邻接矩阵
构建邻接矩阵 W 主要有三种方法 :
•
-近邻法
•
K近邻法
• 全连接法
7
Spectral Clustering 谱聚类
谱聚类基础一:图-邻接矩阵
(1) -近邻法:
设置一个距离阈值
,然后用欧式距离
2
27
Spectral Clustering 谱聚类
(2) Ratio Cut
令
qi
二分类:
n1
n2 n
n2
n1n
i G1
= 1
i G2
Rcut (G1 , G2 )
w q q
2
iG1 , jG2
聚类算法_实验报告
一、实验背景随着大数据时代的到来,数据量呈爆炸式增长,如何有效地对海量数据进行处理和分析成为了一个重要课题。
聚类算法作为一种无监督学习方法,在数据挖掘、模式识别等领域有着广泛的应用。
本实验旨在通过实际操作,了解聚类算法的基本原理、实现方法及其在实际问题中的应用。
二、实验目的1. 理解聚类算法的基本原理和流程;2. 掌握K-means、层次聚类、DBSCAN等常用聚类算法;3. 分析不同聚类算法在处理不同类型数据时的优缺点;4. 学会使用聚类算法解决实际问题。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据库:Pandas4. 机器学习库:Scikit-learn四、实验内容1. K-means聚类算法(1)数据准备本实验使用的数据集为Iris数据集,包含150个样本,每个样本有4个特征。
(2)算法实现使用Scikit-learn库中的KMeans类实现K-means聚类算法。
(3)结果分析通过绘制样本分布图,观察聚类效果。
根据聚类结果,将样本分为3类,与Iris数据集的类别标签进行对比。
2. 层次聚类算法(1)数据准备本实验使用的数据集为鸢尾花数据集,包含150个样本,每个样本有4个特征。
(2)算法实现使用Scikit-learn库中的AgglomerativeClustering类实现层次聚类算法。
(3)结果分析通过绘制树状图,观察聚类过程。
根据聚类结果,将样本分为3类,与鸢尾花数据集的类别标签进行对比。
3. DBSCAN聚类算法(1)数据准备本实验使用的数据集为Iris数据集。
(2)算法实现使用Scikit-learn库中的DBSCAN类实现DBSCAN聚类算法。
(3)结果分析通过绘制样本分布图,观察聚类效果。
根据聚类结果,将样本分为3类,与Iris 数据集的类别标签进行对比。
五、实验结果与分析1. K-means聚类算法K-means聚类算法在Iris数据集上取得了较好的聚类效果,将样本分为3类,与真实标签一致。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。