非线性最小二乘
非线性最小二乘法

非线性最小二乘法最小二乘法的一般涵义在科学实验的统计方法研究中,往往会遇到下列类型的问题:设x,y都是被观测的量,且y是x的函数:y=f(x;,…,) (2.1)假设这个函数关系已经由实际问题从理论上具体确定,因而(2.1)可称为理论函数或理论曲线公式,但其中含有n个未知参数,…,。
为了进一步确定这n个参数,我们可以通过实验或观测来得到m组数据:(,(,,…,(,(2.2)根据(2.2)来寻找参数的最佳估计值,…,,即寻求最佳的理论曲线y=f(x;,…,),这就是一般的曲线拟合问题,也可称为观测数据的平滑问题。
在实际问题中我们经常遇到的一种曲线拟合问题是需要从观测数据(2.2)求出y和x的一个经验公式,而在曲线拟合时首先碰到的问题就是函数关系(2.1)的具体确定,然后才能进行参数估计。
对于某些变量x,y之间已经有比较明确物理关系或关系简单的问题给出函数的具体表达式并不是太困难,但往往实际问题中所遇到的却是极为复杂的问题,要建立有效的表达式就有些困难了。
我们所讨论的最小二乘问题都是建立在函数关系已知的基础上。
我们用残差作为拟合标准,此时=-f(;,…,) (i=1,2,…,m)简单记作r=y-f(x;b)这里,r=b=f(x,b)=残差向量r的三种范数记作===残差可以表示拟合的误差,误差越小则拟合的效果越好。
虽然取前两种范数最小,比较理想和直观,但是它们不便于计算,因此在实际应用中是取欧式范数最小,即求出参数b ,使得=min 这就是通常所谓的最小二乘法,几何语言也成为最小二乘拟合。
解非线性方程组的Newton 法12(,,......,)01,2,......,j n f x x x j m =⎧⎨=⎩(1) 设其解为***12(,,......,)n x x x ,在其附近一点00012(,,......,)n x x x 把j f 展成Taylor 展式: 00000001212121(,,...,)(,,...,)()(,,...,)n j n j nk k j n j k k f x x x f x x x x x f x x x R x =∂=+-+∂∑20012,11()()(,,......)1,2,......,2n j l l k k j n l k l k R x x x x f j n x x ξξξ=∂=--=∂∂∑忽略余项j R 得到:000000012121(,,...,)()(,,...,)01,2,...,n j n k k j n k kf x x x x x f x x x j m x =∂+-==∂∑ 这是一组线性方程,它的解111,......,n x x 作为解,系数矩阵式Jacobi 阵 1111222212112(,...,)n n n m m m n f f f x x x f f f x x x J J x x f f f x x x ∂∂∂⎛⎫ ⎪∂∂∂ ⎪ ⎪∂∂∂ ⎪∂∂∂== ⎪ ⎪ ⎪∂∂∂ ⎪ ⎪∂∂∂⎝⎭写成向量形式:12(,,......,)j j j j n x x x x =,则上述线性方程组化为: 000()()()0f x J x x x +-=当m n >时,上述方程为超定的,求其最小二乘解1x10100()()x x J x f x -=-其中1J -理解为广义逆,再迭代得:11()()k k k k x x J x f x +-=-。
MATLAB中的最小二乘问题求解技巧

MATLAB中的最小二乘问题求解技巧最小二乘问题是求解一个最优拟合曲线或平面的方法,它在各种科学和工程领域中都有广泛的应用。
在MATLAB中,有很多强大的工具和函数可以用来解决最小二乘问题。
本文将介绍一些MATLAB中常用的最小二乘问题求解技巧,帮助读者更好地利用MATLAB来解决实际问题。
一、线性最小二乘问题求解线性最小二乘问题是最简单的一类最小二乘问题,它对应于求解一个线性方程组。
在MATLAB中,我们可以使用“\”运算符来直接求解线性最小二乘问题。
例如,如果我们有一个包含m个方程和n个未知数的线性方程组Ax=b,其中A是一个m×n的矩阵,b是一个m×1的向量,我们可以使用以下代码来求解该方程组:```matlabx = A\b;```在这个例子中,MATLAB将会利用最小二乘法来计算出一个使得Ax与b之间误差的平方和最小的向量x。
二、非线性最小二乘问题求解非线性最小二乘问题的求解相对复杂一些,因为它不再对应于一个简单的方程组。
在MATLAB中,我们可以使用“lsqcurvefit”函数来求解非线性最小二乘问题。
该函数的基本用法如下:```matlabx = lsqcurvefit(fun,x0,xdata,ydata);```其中,fun是一个函数句柄,表示我们要拟合的目标函数;x0是一个初始值向量;xdata和ydata是实验数据的输入和输出。
lsqcurvefit函数将会尝试找到一个使得目标函数与实验数据之间残差的平方和最小的参数向量。
三、加权最小二乘问题求解加权最小二乘问题是在非线性最小二乘问题的基础上引入权重因子的一种求解方法。
它可以用来处理实验数据中存在的误差或不确定性。
在MATLAB中,我们可以使用“lsqnonlin”函数来求解加权最小二乘问题。
```matlabx = lsqnonlin(fun,x0,[],[],options);```其中,fun、x0、options的含义与lsqcurvefit函数相同。
数学建模 非线性最小二乘问题

1、非线性最小二乘问题用最小二乘法计算:sets:quantity/1..15/: x,y;endsetsmin=@sum(quantity: (a+b* @EXP(c*x)-y)^2);@free(a); @free(b);@free(c);data:x=2,5,7,10,14,19,26,31,34,38,45,52,53,60,65;y=54,50,45,37,35,25,20,16,18,13,8,11,8,4,6;enddata运算结果为:Local optimal solution found.Objective value: 44.78049 Extended solve steps: 5Total solve iterartions: 68Variable Value Reduced CostA 2.430177 0.000000B 57.33209 0.000000C -0.4460383E-01 0.000000由此得到a的值为2.430177,b的值为57.33209,c的值为-0.04460383。
线性回归方程为y=2.430177+57.33209* @EXP(-0.04460383*x)用最小一乘法计算:程序如下:sets:quantity/1..15/: x,y;endsetsmin=@sum(quantity: @ABS(a+b*@EXP(c*x)-y));@free(a); @free(b);@free(c);data:x=2,5,7,10,14,19,26,31,34,38,45,52,53,60,65;y=54,50,45,37,35,25,20,16,18,13,8,11,8,4,6;enddata运算结果为:Linearization components added:Constraints: 60Variables: 60Integers: 15Local optimal solution found.Objective value: 20.80640Extended solver steps: 2Total solver iterations: 643Variable Value Reduced CostA 3.398267 0.000000B 57.11461 0.000000C -0.4752126e-01 0.000000由上可得a的值为3.398267,b的值为57.11461,c的值为-0.04752126。
非线性最小二乘法

非线性最小二乘法编辑词条分享•新知社新浪微博腾讯微博人人网QQ空间网易微博开心001天涯飞信空间MSN移动说客非线性最小二乘法非线性最小二乘法是以误差的平方和最小为准则来估计非线性静态模型参数的一种参数估计方法。
编辑摘要目录1 简介2 推导3 配图4 相关连接非线性最小二乘法 - 简介以误差的平方和最小为准则来估计非线性静态模型参数的一种参数估计方法。
设非线性系统的模型为y=f(x,θ) 式中y是系统的输出,x是输入,θ是参数(它们可以是向量)。
这里的非线性是指对参数θ的非线性模型,不包括输入输出变量随时间的变化关系。
在估计参数时模型的形式f是已知的,经过N次实验取得数据(x1,y1),(x2,y1), ,(xn,yn)。
估计参数的准则(或称目标函数)选为模型的误差平方和非线性最小二乘法就是求使Q达到极小的参数估计值孌。
推导非线性最小二乘法 - 推导以误差的平方和最小为准则来估计非线性静态模型参数的一种参数估计方法。
设非线性系统的模型为y=f(x,θ)式中y是系统的输出,x是输入,θ是参数(它们可以是向量)。
这里的非线性是指对参数θ的非线性模型,不包括输入输出变量随时间的变化关系。
在估计参数时模型的形式f是已知的,经过N次实验取得数据(x1,y1),(x2,y1), ,(x n,y n)。
估计参数的准则(或称目标函数)选为模型的误差平方和非线性最小二乘法就是求使Q达到极小的参数估计值孌。
由于f的非线性,所以不能象线性最小二乘法那样用求多元函数极值的办法来得到参数估计值,而需要采用复杂的优化算法来求解。
常用的算法有两类,一类是搜索算法,另一类是迭代算法。
搜索算法的思路是:按一定的规则选择若干组参数值,分别计算它们的目标函数值并比较大小;选出使目标函数值最小的参数值,同时舍弃其他的参数值;然后按规则补充新的参数值,再与原来留下的参数值进行比较,选出使目标函数达到最小的参数值。
如此继续进行,直到选不出更好的参数值为止。
MATLAB实现非线性曲线拟合最小二乘法
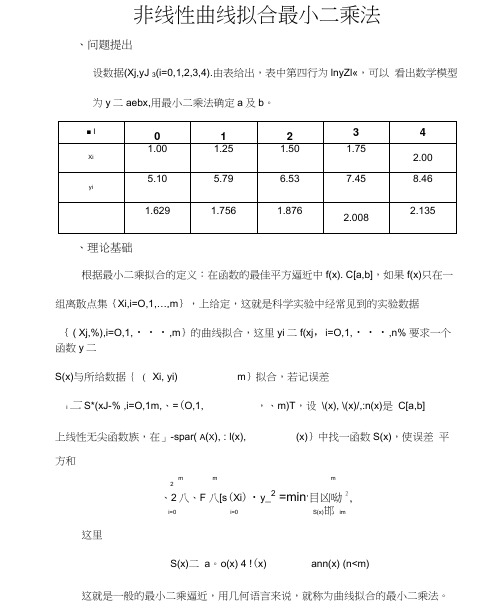
非线性曲线拟合最小二乘法、问题提出设数据(Xj,yJ 3(i=0,1,2,3,4).由表给出,表中第四行为lnyZl«,可以看出数学模型为y二aebx,用最小二乘法确定a及b。
、理论基础根据最小二乘拟合的定义:在函数的最佳平方逼近中f(x). C[a,b],如果f(x)只在一组离散点集{Xi,i=O,1,…,m},上给定,这就是科学实验中经常见到的实验数据{ ( Xj,%),i=O,1,・・・,m}的曲线拟合,这里yi二f(xj,i=O,1,・・・,n% 要求一个函数y二S(x)与所给数据{ ( Xi, yi) m}拟合,若记误差i 二 S*(xJ-% ,i=O,1m,、=(O,1, ,、m)T,设\(x), \(x)/,:n(x)是C[a,b]上线性无尖函数族,在」-spar( A(X), : l(x), (x)}中找一函数S(x),使误差平方和m m m2、2八、F 八[s(Xi)・y_2 =min,目凶呦2,i=0 i=0 S(x)邯im这里S(x)二a。
o(x) 4 !(x) ann(x) (n<m)这就是一般的最小二乘逼近,用几何语言来说,就称为曲线拟合的最小二乘法。
在建模的过程中应用到了求和命令(sum)、求偏导命令(diff)、化简函数命令(simple)〉用迭代方法解二元非线性方程组的命令(fsolve),画图命令(plot)等。
三、实验内容用最小二乘法求拟合曲线时,首先要确定S(x)的形式。
这不单纯是数学问题,还与所研究问题的运动规律及所得观测数据( Xi,% )有尖;通常要从问题的运动规律及给定数据描图,确定s(x)的形式,并通过实际计算选出较好的结果。
S(x)的一般表达式为线性形式,若\(x)是k次多项式,S(x)就是n次多项式,为了使问题的提法更有一般性,通常在最小二乘法中2都考虑为加权平方和m:2八(X讥S(Xj) - f(xj]2.i=0这里r(x)_o是[a,b]上的权函数,它表示不同点(Xi, f(xj)处的数据比重不同。
非线性最小二乘法Levenberg-Marquardt-method

Levenberg-Marquardt Method(麦夸尔特法)Levenberg-Marquardt is a popular alternative to the Gauss-Newton method of finding the minimum of afunction that is a sum of squares of nonlinear functions,Let the Jacobian of be denoted , then the Levenberg-Marquardt method searches in thedirection given by the solution to the equationswhere are nonnegative scalars and is the identity matrix. The method has the nice property that, forsome scalar related to , the vector is the solution of the constrained subproblem of minimizingsubject to (Gill et al. 1981, p. 136).The method is used by the command FindMinimum[f, x, x0] when given the Method -> Levenberg Marquardt option.SEE A LSO:Minimum, OptimizationREFERENCES:Bates, D. M. and Watts, D. G. N onlinear Regr ession and Its Applications. New York: Wiley, 1988.Gill, P. R.; Murray, W.; and Wright, M. H. "The Levenberg-Marquardt Method." §4.7.3 in Practical Optim ization. London: Academic Press, pp. 136-137, 1981.Levenberg, K. "A Method for the Solution of Certain Problems in Least Squares." Quart. Appl. Math.2, 164-168, 1944. Marquardt, D. "An Algor ithm for Least-Squares Estimation of Nonlinear Parameters." SIAM J. Appl. Math.11, 431-441, 1963.Levenberg–Marquardt algorithmFrom Wikipedia, the free encyclopediaJump to: navigation, searchIn mathematics and computing, the Levenberg–Marquardt algorithm (LMA)[1] provides a numerical solution to the problem of minimizing a function, generally nonlinear, over a space of parameters of the function. These minimization problems arise especially in least squares curve fitting and nonlinear programming.The LMA interpolates between the Gauss–Newton algorithm (GNA) and the method of gradient descent. The LMA is more robust than the GNA, which means that in many cases it finds a solution even if it starts very far off the final minimum. For well-behaved functions and reasonable starting parameters, the LMA tends to be a bit slower than the GNA. LMA can also be viewed as Gauss–Newton using a trust region approach.The LMA is a very popular curve-fitting algorithm used in many software applications for solving generic curve-fitting problems. However, the LMA finds only a local minimum, not a global minimum.Contents[hide]∙ 1 Caveat Emptor∙ 2 The problem∙ 3 The solutiono 3.1 Choice of damping parameter∙ 4 Example∙ 5 Notes∙ 6 See also∙7 References∙8 External linkso8.1 Descriptionso8.2 Implementations[edit] Caveat EmptorOne important limitation that is very often over-looked is that it only optimises for residual errors in the dependant variable (y). It thereby implicitly assumes that any errors in the independent variable are zero or at least ratio of the two is so small as to be negligible. This is not a defect, it is intentional, but it must be taken into account when deciding whether to use this technique to do a fit. While this may be suitable in context of a controlled experiment there are many situations where this assumption cannot be made. In such situations either non-least squares methods should be used or the least-squares fit should be done in proportion to the relative errors in the two variables, not simply the vertical "y" error. Failing to recognise this can lead to a fit which is significantly incorrect and fundamentally wrong. It will usually underestimate the slope. This may or may not be obvious to the eye.MicroSoft Excel's chart offers a trend fit that has this limitation that is undocumented. Users often fall into this trap assuming the fit is correctly calculated for all situations. OpenOffice spreadsheet copied this feature and presents the same problem.[edit] The problemThe primary application of the Levenberg–Marquardt algorithm is in the least squares curve fitting problem: given a set of m empirical datum pairs of independent and dependent variables, (x i, y i), optimize the parameters β of the model curve f(x,β) so that the sum of the squares of the deviationsbecomes minimal.[edit] The solutionLike other numeric minimization algorithms, the Levenberg–Marquardt algorithm is an iterative procedure. To start a minimization, the user has to provide an initial guess for the parameter vector, β. In many cases, an uninformed standard guess like βT=(1,1,...,1) will work fine;in other cases, the algorithm converges only if the initial guess is already somewhat close to the final solution.In each iteration step, the parameter vector, β, is replaced by a new estimate, β + δ. To determine δ, the functions are approximated by their linearizationswhereis the gradient(row-vector in this case) of f with respect to β.At its minimum, the sum of squares, S(β), the gradient of S with respect to δwill be zero. The above first-order approximation of gives.Or in vector notation,.Taking the derivative with respect to δand setting theresult to zero gives:where is the Jacobian matrix whose i th row equals J i,and where and are vectors with i th componentand y i, respectively. This is a set of linear equations which can be solved for δ.Levenberg's contribution is to replace this equation by a "damped version",where I is the identity matrix, giving as the increment, δ, to the estimated parameter vector, β.The (non-negative) damping factor, λ, isadjusted at each iteration. If reduction of S is rapid, a smaller value can be used, bringing the algorithm closer to the Gauss–Newton algorithm, whereas if an iteration gives insufficientreduction in the residual, λ can be increased, giving a step closer to the gradient descentdirection. Note that the gradient of S withrespect to β equals .Therefore, for large values of λ, the step will be taken approximately in the direction of the gradient. If either the length of the calculated step, δ, or the reduction of sum of squares from the latest parameter vector, β + δ, fall below predefined limits, iteration stops and the last parameter vector, β, is considered to be the solution.Levenberg's algorithm has the disadvantage that if the value of damping factor, λ, is large, inverting J T J + λI is not used at all. Marquardt provided the insight that we can scale eachcomponent of the gradient according to thecurvature so that there is larger movement along the directions where the gradient is smaller. This avoids slow convergence in the direction of small gradient. Therefore, Marquardt replaced theidentity matrix, I, with the diagonal matrixconsisting of the diagonal elements of J T J,resulting in the Levenberg–Marquardt algorithm:.A similar damping factor appears in Tikhonov regularization, which is used to solve linear ill-posed problems, as well as in ridge regression, an estimation technique in statistics.[edit] Choice of damping parameterVarious more-or-less heuristic arguments have been put forward for the best choice for the damping parameter λ. Theoretical arguments exist showing why some of these choices guaranteed local convergence of the algorithm; however these choices can make the global convergence of the algorithm suffer from the undesirable properties of steepest-descent, in particular very slow convergence close to the optimum.The absolute values of any choice depends on how well-scaled the initial problem is. Marquardt recommended starting with a value λ0 and a factor ν>1. Initially setting λ=λ0and computing the residual sum of squares S(β) after one step from the starting point with the damping factor of λ=λ0 and secondly withλ0/ν. If both of these are worse than the initial point then the damping is increased by successive multiplication by νuntil a better point is found with a new damping factor of λ0νk for some k.If use of the damping factor λ/ν results in a reduction in squared residual then this is taken as the new value of λ (and the new optimum location is taken as that obtained with this damping factor) and the process continues; if using λ/ν resulted in a worse residual, but using λresulted in a better residual then λ is left unchanged and the new optimum is taken as the value obtained with λas damping factor.[edit] ExamplePoor FitBetter FitBest FitIn this example we try to fit the function y = a cos(bX) + b sin(aX) using theLevenberg–Marquardt algorithm implemented in GNU Octave as the leasqr function. The 3 graphs Fig 1,2,3 show progressively better fitting for the parameters a=100, b=102 used in the initial curve. Only when the parameters in Fig 3 are chosen closest to the original, are thecurves fitting exactly. This equation is an example of very sensitive initial conditions for the Levenberg–Marquardt algorithm. One reason for this sensitivity is the existenceof multiple minima —the function cos(βx)has minima at parameter value and[edit] Notes1.^ The algorithm was first published byKenneth Levenberg, while working at theFrankford Army Arsenal. It was rediscoveredby Donald Marquardt who worked as astatistician at DuPont and independently byGirard, Wynn and Morrison.[edit] See also∙Trust region[edit] References∙Kenneth Levenberg(1944). "A Method for the Solution of Certain Non-Linear Problems in Least Squares". The Quarterly of Applied Mathematics2: 164–168.∙ A. Girard (1958). Rev. Opt37: 225, 397. ∙ C.G. Wynne (1959). "Lens Designing by Electronic Digital Computer: I". Proc.Phys. Soc. London73 (5): 777.doi:10.1088/0370-1328/73/5/310.∙Jorje J. Moré and Daniel C. Sorensen (1983)."Computing a Trust-Region Step". SIAM J.Sci. Stat. Comput. (4): 553–572.∙ D.D. Morrison (1960). Jet Propulsion Laboratory Seminar proceedings.∙Donald Marquardt (1963). "An Algorithm for Least-Squares Estimation of NonlinearParameters". SIAM Journal on AppliedMathematics11 (2): 431–441.doi:10.1137/0111030.∙Philip E. Gill and Walter Murray (1978)."Algorithms for the solution of thenonlinear least-squares problem". SIAMJournal on Numerical Analysis15 (5):977–992. doi:10.1137/0715063.∙Nocedal, Jorge; Wright, Stephen J. (2006).Numerical Optimization, 2nd Edition.Springer. ISBN0-387-30303-0.[edit] External links[edit] Descriptions∙Detailed description of the algorithm can be found in Numerical Recipes in C, Chapter15.5: Nonlinear models∙ C. T. Kelley, Iterative Methods for Optimization, SIAM Frontiers in AppliedMathematics, no 18, 1999, ISBN0-89871-433-8. Online copy∙History of the algorithm in SIAM news∙ A tutorial by Ananth Ranganathan∙Methods for Non-Linear Least Squares Problems by K. Madsen, H.B. Nielsen, O.Tingleff is a tutorial discussingnon-linear least-squares in general andthe Levenberg-Marquardt method inparticular∙T. Strutz: Data Fitting and Uncertainty (A practical introduction to weighted least squares and beyond). Vieweg+Teubner, ISBN 978-3-8348-1022-9.[edit] Implementations∙Levenberg-Marquardt is a built-in algorithm with Mathematica∙Levenberg-Marquardt is a built-in algorithm with Matlab∙The oldest implementation still in use is lmdif, from MINPACK, in Fortran, in thepublic domain. See also:o lmfit, a translation of lmdif into C/C++ with an easy-to-use wrapper for curvefitting, public domain.o The GNU Scientific Library library hasa C interface to MINPACK.o C/C++ Minpack includes theLevenberg–Marquardt algorithm.o Several high-level languages andmathematical packages have wrappers forthe MINPACK routines, among them:▪Python library scipy, modulescipy.optimize.leastsq,▪IDL, add-on MPFIT.▪R (programming language) has theminpack.lm package.∙levmar is an implementation in C/C++ with support for constraints, distributed under the GNU General Public License.o levmar includes a MEX file interface for MATLABo Perl (PDL), python and Haskellinterfaces to levmar are available: seePDL::Fit::Levmar, PyLevmar andHackageDB levmar.∙sparseLM is a C implementation aimed at minimizing functions with large,arbitrarily sparse Jacobians. Includes a MATLAB MEX interface.∙ALGLIB has implementations of improved LMA in C# / C++ / Delphi / Visual Basic.Improved algorithm takes less time toconverge and can use either Jacobian orexact Hessian.∙NMath has an implementation for the .NET Framework.∙gnuplot uses its own implementation .∙Java programming language implementations:1) Javanumerics, 2) LMA-package (a small,user friendly and well documentedimplementation with examples and support),3) Apache Commons Math∙OOoConv implements the L-M algorithm as an Calc spreadsheet.∙SAS, there are multiple ways to access SAS's implementation of the Levenberg-Marquardt algorithm: it can be accessed via NLPLMCall in PROC IML and it can also be accessed through the LSQ statement in PROC NLP, and the METHOD=MARQUARDT option in PROC NLIN.。
非线性最小二乘问题
非线性最小二乘问题非线性最小二乘问题是一种解决实际应用中非线性系统求解最优化问题的有效方法,是研究遥感、机器人导航、机床控制、智能控制等领域的研究的基础。
非线性最小二乘问题具有普遍性,在很多学科和领域中都有广泛的应用。
一般来说,非线性最小二乘问题是一种优化问题,它涉及到求解满足条件的参数及其对应的函数最小值,其函数由基本函数和残差函数两部分组成。
基本函数又称作目标函数,是根据实际问题解题的依据;残差函数又称作约束函数,是根据实际约束条件而确定的。
因此,非线性最小二乘问题的求解步骤有以下几个:(1)确定基本函数和残差函数;(2)确定求解的参数及其范围;(3)对对应的函数最小值,采用梯度下降法等优化方法求解;(4)判断最小值是否满足目标要求,以达到最优化的效果。
其中,梯度下降法是一种常用的优化方法,它可以帮助求解非线性最小二乘问题,梯度下降法的基本思想是,在每次迭代中,根据目标函数对变量的梯度信息,找到该函数局部最小值,通过迭代搜索不断改进求解结果,使得每次迭代都能获得更优的结果。
另外,针对不同问题,还可以采用其他有效的优化方法,如模拟退火算法、粒子群算法等,它们都可以有效解决非线性最小二乘问题。
模拟退火算法是一种迭代算法,它可以有效地控制步长,从而有效改善求解结果;粒子群算法是一种仿生算法,它可以通过考虑各个粒子之间的信息交互,自动学习出有效的优化参数,从而有效求解非线性最小二乘问题。
总之,非线性最小二乘问题是一种常见的优化问题,其解题的基本步骤是确定基本函数和残差函数,然后采用梯度下降法、模拟退火算法、粒子群算法等有效的优化方法,从而求解满足约束条件的非线性最小二乘问题最优解。
研究非线性最小二乘问题,有利于更好地解决遥感、机器人导航、机床控制等工程实际应用中的问题,从而实现更高效的控制和决策。
第15次 非线性最小二乘法
∂f 1 ... ∂x n ⋮ ⋮ ∂f m ... ∂x n
∂f i ( x k ) )m×n 。 =( ∂x j
x= xk
记 Ak = A( x k ) , 则有
S ( x ) ≈ f ( x ) + Ak ( x − x ) = Ak d + f ( x )
k k 2 k k 2
Step 2 : 若 S ( x + z ) ≥ S ( x ), 则令 λ : αλ 并返回 Step1。 =
Step 3 : 令 x := x + z , λ = βλ ; 若 A( x )T f( x)< ε 则迭代终止, 则迭代终止, 否则返回 Step1。
方法总结: 8. L-M 方法总结:
T T Ak Ak d k = − Ak f ( x k )
(1)
当Ak Ak 可逆时则有
T d k = − ( Ak Ak ) −1 Ak f ( x k ) T
T
( 2)
令 x k + 1 = x = x k + d k,则有迭代公式
T T x k + 1 = x k + d k = x k − ( Ak Ak ) −1 Ak f ( x k )
disadvantage : that if the value of λ is large, the calculated Hessian matrix is not used at all.
5. 设λ > 0,z是方程组( * *)的解,那么有: 是方程组( 的解,那么有:
性质 1: f ( x ) + A( x ) y ≥ f ( x ) + A( x ) z ( ∀ y = z )
第四章 非线性回归与非线性约束
具体检验时,用来对原假设进行检验的似然比统 用来对原假设进行检验的似然比统 具体检验 计量定义为: 计量定义为: L( β R ) LR = −2(ln L( β R ) − ln L( βUR )) = −2 ln L( βUR )
LR ~ χ , m为限制条件的个数。
2 m 2 若LR大于给定显著性水平下的χ m临界值,
2
exp[−
1 2σ
2
(Yi − f ( X 1i , X 2i , L X ki , β1 , β 2 ,L β p )) 2 ]
则N个观测值的对数似然函数为 LnL = ∑ p (Yi , X i β ) = − ( N / 2) ln(2π ) − ( N / 2) ln(σ )
2
− (σ / 2)∑ (Yi − f ( X 1i , X 2i , L X ki , β1 , β 2 , L β p ))
L( β R ) 则似然比定义为λ = . L( βUR )
L( β R ) 则似然比定义为λ = . L( βUR )
L越大表明对数据的拟合程度越好,分母来自无条 越大表明对数据的拟合程度越好, 越大表明对数据的拟合程度越好 件模型,变量个数越多,拟合越好, 件模型,变量个数越多,拟合越好,因此分子小于分 似然比在0到 间 母,似然比在 到1间。分子是在原假设成立下参数的 极大似然函数值,是零假设的最佳表示。 极大似然函数值,是零假设的最佳表示。而分母则表 示在在任意情况下参数的极大似然函数值。 示在在任意情况下参数的极大似然函数值。比值的最 大极限值为1,其值靠近1, 大极限值为 ,其值靠近 ,说明局部的最大和全局最 大近似,零假设成立可能性就越大。 大近似,零假设成立可能性就越大。
设L( βUR )代表没有限制条件时似然函数 的极大值, L( β R )代表有限制条件时似然函数的极大值,
非线性最小二乘平差(精)
非线性最小二乘平差6-1问题的提出经典平差是基于线性模型的平差方法。
然而在现实世界中,严格的线性模型并不多见。
测量上大量的数学模型也是非线性模型。
传统的线性模型平差中的很多理论在非线性模型平差中就不一定适用;线性模型平差中的很多结论在非线性模型平差中就不一定成立;线性模型平差中的很多优良统计性质在非线性模型平差中就不一定存在。
例如,在线性模型平差中,当随机误差服从正态分布时,未知参数X的最小二乘估计具有一致无偏性和方差最小性。
但在非线性模型平差中,即使随机误差严格服从正态分布,未知参数X的非线性最小二乘估计也是有偏的。
其方差一般都不能达到最小值。
对于测量中大量的非线性模型,在经典平差中总是进行线性近似(经典的测量平差中称之为线性化),即将其展开为台劳级数,并取至一次项,略去二次以上各项。
如此线性近似,必然会引起模型误差。
过去由于测量精度不高,线性近似所引起的模型误差往往小于观测误差,故可忽略不计。
随着科学技术的不断发展,现在的观测精度已大大提高,致使因线性近似所产生的模型误差与观测误差相当,有些甚至还会大于观测误差。
例如,GPS载波相位观测值的精度很高,往往小于因线性近似所产生的模型误差。
因此,用近似的理论、模型、方法去处理具有很高精度的观测结果,从而导致精度的损失,这显然是不合理的。
现代科学技术要求估计结果的精度尽可能高。
这样,传统线性近似的方法就不一定能满足当今科学技术的要求。
另外,有些非线性模型对参数的近似值十分敏感,若近似值精度较差,则线性化会产生较大的模型误差。
由于线性近似后,没有顾及因线性近似所引起的模型误差,而用线性模型的精度评定理论去评定估计结果的精度,从而得到一些虚假的优良统计性质,人为地拔高了估计结果的精度。
鉴于上述各种原因,对非线性模型平差进行深入的研究是很有必要的。
非线性模型的平差和精度估计以及相应的误差理论研究也是当前国内外测绘界研究的前沿课题之一。
电子教材 > 第六章非线性模型平差 > 6-2 非线性模型平差原理一、非线性误差方程测量中大量的观测方程是非线性方程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
线性估计
Q e5.526 ( X / P )0.534 (P / P )0.243 0 1 0
ˆ ln(Q) 5.52 0.534ln(X / P0 ) 0.275ln(P / P0 ) 1
线性估计
讨论
• 一般情况下,线性化估计和非线性估计结果差异 不大。如果差异较大,在确认非线性估计结果为 总体最小时,应该怀疑和检验线性模型。 • 非线性估计确实存在局部极小问题。 • 根据参数的经济意义和数值范围选取迭代初值。 • NLS估计的异方差和序列相关问题。
– 对残差平方和展开台劳级数,取二阶近似值; – 对残差平方和的近似值求极值; – 迭代。
• 与高斯-牛顿迭代法的区别
– 直接对残差平方和展开台劳级数,而不是对其中的原 模型展开; – 取二阶近似值,而不是取一阶近似值。
⒋应用中的一个困难
• 如何保证迭代所逼近的是总体极小值(即最小值) 而不是局部极小值? • 一般方法是模拟试验:随机产生初始值→估计→改 变初始值→再估计→反复试验,设定收敛标准(例 如100次连续估计结果相同)→直到收敛。
⒌非线性普通最小二乘法在软件中的实现
• • • • • 给定初值 写出模型 估计模型 改变初值 反复估计
⒍例题
• 例 建立中国城镇居民食品消费需求函数模型。
Qe
5.568
X
0.556
P 1
0.190
P0
0.395
ˆ ln(Q) 5.53 0.540ln(X ) 0.258ln(P ) 0.288ln(P0 ) 1
i 1
( ~i ( ( 0) ) zi ( ( 0) ) ) 2 y
i 1
n
构造并估计线性伪模型
~ ( ) z ( ) ˆ yi ˆ ( 0) i ( 0) i
n
构造线性模型
S ( (1) ) ( ~i ( ( 0) ) zi ( ( 0) ) (1) ) 2 y
非线性最小二乘估计
• 变量之间的关系更多地表现为非线性特征。 线性模型作为基础模型是非线性的近似, 即任何非线性模型都可以通过线性模型来 近似表达。
• 比如,模型 y 0 1ex u • 通过泰勒级数展开表述为
y 0 1e x |x x0 ( x x0 ) u 0 1e x0 1e x u
x0 x0
0 x u
*x 2 u
的线性近似表达式为
y 0 1 (2 x) |x x0 ( x x0 ) u 0 21 x0 2 21 x0 x u 0 x u
i 1
n df ( xi , ) dS 2 ( yi f ( xi , )( )0 d d i 1
n
取极小值的 一阶条件
df ( xi , ) ( yi f ( xi , )( d ) 0 i 1
n
如何求解非 线性方程?
* * 1
• 但线性模型对非线性模型的近似程度取决于高阶部 分是否充分小。即使在样本内线性模型能够较好地 拟合数据,也不能准确地体现变量的结构关系。非 线性模型中,x对y 的边际影响(或弹性)是变化的; 而线性模型中,x对y 的边际影响(或弹性)是常数。 很多情况下,线性模型与非线性模型对边际影响或 弹性的估计存在非常大的差异。另外,利用线性模 型拟合非线性数据存在潜在的危险,即区间外预测 会存在越来越大的误差。因此,正确设定模型的形 式是进行准确推断和预测的重要环节。
• 对于一般的回归模型,如以下形式的模型, y f ( X, β) u • (1) • OLS一般不能得到其解析解。比如,运用 OLS方法估计模型(1),令S(B)表示残差 平方和,即 • (2)
S (β) u [ yi f ( Xi ; β)]
i 1 2 i i 1 n n 2
⒉ 高斯-牛顿(Gauss-Newton)迭代法
• 高斯-牛顿迭代法的原理
对原始模型展开泰勒级数,取一阶近似值
df ( xi , ) f ( xi , ) f ( xi , ( 0) ) d
( 0)
( ( 0) )
df ( xi , ) zi ( ) d
S (β) 1 n [ yi 0 1e 2 xi ]e 2 xi 0 1 2 i 1
S (β) 1 n [ yi 0 1e 2 xi ] 2 xi e 2 xi 0 2 2 i 1
• 上述方程组没有解析解,需要一般的最优 化方法。很多数值最优化算法都可以完成 这一类任务,这些方法的总体思路是一样 的。即,从初始值出发,按照一定的方向 搜寻更好的估计量,并反复迭代直至收敛。 • 各种不同的最优化算法的差异主要体现在 三个方面:搜寻的方向、估计量变化的幅 度和迭代停止法则。
y 第三步:采用普通最小二乘法估计模型 ~i zi i ,得到 的估计值 (1) ;
第四步:用 (1) 代替第一步中的 ( 0 ) ,重复这一过程,直至收敛。
⒊ 牛顿-拉夫森(Newton-Raphson)迭代法
• 自学,掌握以下2个要点
• 牛顿-拉夫森迭代法的原理
• 非线性最小二乘法的思路是,通过泰勒级 数将均值函数展开为线性模型。即,只包 括一阶展开式,高阶展开式都归入误差项。 然后再进行OLS回归,将得到的估计量作 为新的展开点,再对线性部分进行估计。 如此往复,直至收敛。
⒈ 普通最小二乘原理
yi f ( xi , ) i
残差平方和
S ( ) ( yi f ( xi , )) 2
• 最小化S(B),即根据一阶条件可以得到
n f ( Xi ; β) S (β) 2[ yi f ( Xi ; β)] 0 β β i 1
y x u 为例,其一阶条件为 • 以模型
S (β) 1 n [ yi 0 1e 2 xi ] 0 0 2 i 1
– NLS不能直接处理。
– 应用最大似然估计。
S ( ) ( yi f ( xi , ( 0) ) zi ( ( 0) )( ( 0) )) 2
i 1
n
n
( yi f ( xi , ( 0) ) zi ( ( 0) ) ( 0) zi ( ( 0) ) ) 2
i 1
估计得到参数的第1次迭代值 (1)
迭代
• 高斯-牛顿迭代法的步骤
第一步:给出参数估计值 的初值 ( 0 ) ,将 f ( xi , ) 在 ( 0 ) 处展开台劳级数,
取一阶近似值;
df ( xi , ) 第二步:计算 zi d
( 0 )
y 和 ~i yi f ( xi , ( 0) ) zi ( 0) 的样本观测值;